使用维也纳开放数据门户评估城市绿地平等性
评估城市绿地平等性
<h2 id="尽管具有许多优点,但在高度城市化地区,访问大自然和绿地越来越困难。有人担心受服务不足的社区更容易受到这些问题的影响。在这里,我提出一种数据驱动的方法来探索这个问题。
具体而言,我提出了一个近来在专业圈子和地方政府中引起关注的城市发展问题——绿色平等。这个概念指的是人们在特定城市的不同地区访问绿地的差异。在这里,我探索了绿色平等的财务维度,并查看了每个城市单位的人均可用绿地面积与该城市单位的经济水平之间是否存在明显的关系。
我将使用奥地利政府的开放数据门户提供的Esri Shapefiles来探索城市的两种不同空间分辨率——区域和普查区。我还将将表格统计数据(人口和收入)融入到地理参考的行政区域中。然后,我将行政区域与官方绿地数据集进行叠加,记录每个绿地的地理空间位置。然后,我将这些信息合并,并量化每个城市区域的人均绿地面积。最后,我将每个区域的财务状况(以年净收入表示)与人均绿地面积比例关联起来,以查看是否存在任何模式。
1. 数据来源
让我们来看看奥地利政府的开放数据门户。
在我撰写本文时,该网站的英文翻译并没有起作用,所以我没有依靠我已经遗忘的12年德语课程,而是使用DeepL在各个子页面和成千上万个数据集之间进行导航。
然后,我收集了一些数据文件,包括地理参考(Esri shapefiles)和简单的表格数据,我将在后续分析中使用。我收集到的数据有:
边界 — 维也纳以下空间单元的行政边界:
- 维也纳的行政边界
- 维也纳的23个区的行政边界
- 维也纳的250个普查区的行政边界
土地利用 — 关于绿地和建筑区域位置的信息:
- 维也纳城市绿地带,可视化现有和专用的绿地带区域,包括1539个地理空间多边形文件
统计数据 — 关于与某一区域的社会经济水平相对应的人口和收入数据:
- 维也纳各区的人口,自2002年以来每年记录一次,并根据5年龄组、性别和原始国籍进行分割存储
- 维也纳各普查区的人口,自2008年以来每年记录一次,并根据三个不规则年龄组、性别和籍贯进行分割存储
- 维也纳各区自2002年以来的平均净收入,以每位员工每年的欧元表示
此外,我将下载的数据文件存储在名为”data”的本地文件夹中。
2. 基本数据探索
2.1 行政边界
首先,读取并可视化包含每个行政边界级别的不同形状文件,以更加了解所涉及的城市:
folder = 'data'admin_city = gpd.read_file(folder + '/LANDESGRENZEOGD')admin_district = gpd.read_file(folder + '/BEZIRKSGRENZEOGD')admin_census = gpd.read_file(folder + '/ZAEHLBEZIRKOGD')display(admin_city.head(1))display(admin_district.head(1))display(admin_census.head(1))在这里我们注意到,列名BEZNR和ZBEZ分别对应于区ID和普查区ID。出乎意料的是,它们以不同的格式存储/解析,numpy.float64和str:
print(type(admin_district.BEZNR.iloc[0]))print(type(admin_census.ZBEZ.iloc[0]))pyth确保我们确实有23个区和250个人口普查区域,就像数据文件文档所声称的那样:
print(len(set(admin_district.BEZNR)))print(len(set(admin_census.ZBEZ)))现在可视化边界-首先是城市,然后是它的区域,然后是更小的人口普查区域。
f, ax = plt.subplots(1,3,figsize=(15,5))admin_city.plot(ax=ax[0], edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Reds')admin_district.plot(ax=ax[1], edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Blues')admin_census.plot(ax=ax[2], edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Purples')ax[0].set_title('城市边界')ax[1].set_title('区边界')ax[2].set_title('人口普查区域边界')此代码输出维也纳的以下可视化结果:
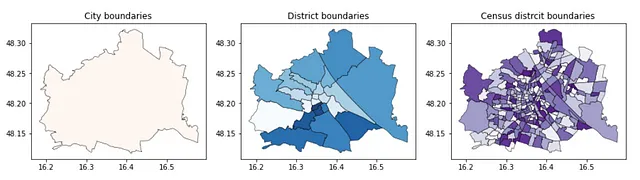
2.2 绿地区域
现在,我们也来看一下绿地分布:
gdf_green = gpd.read_file(folder + '/GRUENFREIFLOGD_GRUENGEWOGD')display(gdf_green.head(3))在这里,您可能会注意到没有直接的方法将绿地区域(例如,没有添加区域ID)与街区关联起来-因此,稍后我们将通过操作几何形状来找到重叠部分。
现在可视化:
f, ax = plt.subplots(1,1,figsize=(7,5))gdf_green.plot(ax=ax, edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Greens')ax.set_title('维也纳的绿地区域')此代码显示了维也纳的绿地区域:
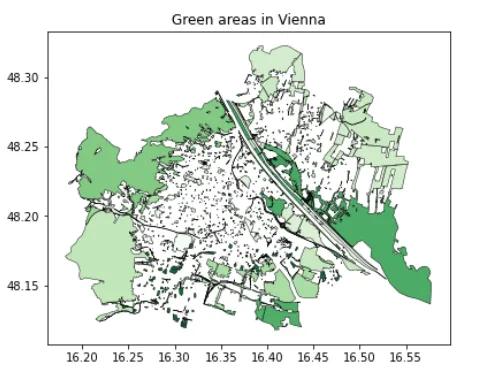
我们可以注意到,林业分区仍位于行政边界内,这意味着城市的每个部分并非都是城市化和人口密集的。稍后在评估人均绿地面积时我们将再次涉及此问题。
2.3 统计数据-人口、收入
最后,让我们来看一下统计数据文件。首要的区别在于这些文件不是地理参考的,而是简单的CSV表格:
df_pop_distr = pd.read_csv('vie-bez-pop-sex-age5-stk-ori-geo4-2002f.csv', sep = ';', encoding='unicode_escape', skiprows = 1)df_pop_cens = pd.read_csv('vie-zbz-pop-sex-agr3-stk-ori-geo2-2008f.csv', sep = ';', encoding='unicode_escape', skiprows = 1)df_inc_distr = pd.read_csv('vie-bez-biz-ecn-inc-sex-2002f.csv', sep = ';', encoding='unicode_escape', skiprows = 1)display(df_pop_distr.head(1))display(df_pop_cens.head(1))display(df_inc_distr.head(1))3. 数据预处理
3.1 准备统计数据文件
前一小节显示了统计数据表格使用不同的命名约定-它们具有DISTRICT_CODE和SUB_DISTRICT_CODE标识符,而不是BEZNR和ZBEZ之类的标识符。然而,阅读每个数据集的文档后,可以明确地知道如何从一个转换为另一个,因此我在下一个单元格中提供了两个简短的函数。我将同时处理区和人口普查区域的数据。
此外,我只对统计信息的(最新的)聚合值和数据点感兴趣,比如最新快照中的总人口。因此,让我们清理这些数据文件并保留我稍后将使用的列。
# 这些函数将区域和人口普查区域的ID转换为与形状文件中的ID兼容的形式def transform_district_id(x): return int(str(x)[1:3])def transform_census_district_id(x): return int(str(x)[1:5])# 选择数据集的最新年份df_pop_distr_2 = df_pop_distr[df_pop_distr.REF_YEAR \ ==max(df_pop_distr.REF_YEAR)]df_pop_cens_2 = df_pop_cens[df_pop_cens.REF_YEAR \ ==max(df_pop_cens.REF_YEAR)]df_inc_distr_2 = df_inc_distr[df_inc_distr.REF_YEAR \ ==max(df_inc_distr.REF_YEAR)]# 转换区域IDdf_pop_distr_2['district_id'] = \ df_pop_distr_2.DISTRICT_CODE.apply(transform_district_id)df_pop_cens_2['census_district_id'] = \ df_pop_cens_2.SUB_DISTRICT_CODE.apply(transform_census_district_id)df_inc_distr_2['district_id'] = \ df_inc_distr_2.DISTRICT_CODE.apply(transform_district_id)# 聚合人口值df_pop_distr_2 = df_pop_distr_2.groupby(by = 'district_id').sum()df_pop_distr_2['district_population'] = df_pop_distr_2.AUT + \ df_pop_distr_2.EEA + df_pop_distr_2.REU + df_pop_distr_2.TCNdf_pop_distr_2 = df_pop_distr_2[['district_population']]df_pop_cens_2 = df_pop_cens_2.groupby(by = 'census_district_id').sum()df_pop_cens_2['census_district_population'] = df_pop_cens_2.AUT \ + df_pop_cens_2.FORdf_pop_cens_2 = df_pop_cens_2[['census_district_population']]df_inc_distr_2['district_average_income'] = \ 1000*df_inc_distr_2[['INC_TOT_VALUE']]df_inc_distr_2 = \ df_inc_distr_2.set_index('district_id')[['district_average_income']]# 显示最终表格display(df_pop_distr_2.head(3))display(df_pop_cens_2.head(3))display(df_inc_distr_2.head(3))# 统一命名规范admin_district['district_id'] = admin_district.BEZNR.astype(int)admin_census['census_district_id'] = admin_census.ZBEZ.astype(int)print(len(set(admin_census.ZBEZ)))在两个层次的聚合中,再次检查计算出的总人口值:
print(sum(df_pop_distr_2.district_population))print(sum(df_pop_cens_2.census_district_population))这两个值应该都提供相同的结果 —— 1931593人。
3.1. 准备地理空间数据文件
现在,我们已经完成了统计文件的基本数据准备工作,是时候将绿地多边形与行政区域多边形匹配起来了。然后,让我们计算每个行政区域的总绿地覆盖面积。此外,出于好奇,我将添加每个行政区域的相对绿地覆盖面积。
为了获得以国际单位表示的面积,我们需要切换到所谓的本地坐标系,对于维也纳来说是EPSG:31282。您可以在这里和这里阅读更多关于这个主题、地图投影和坐标参考系统的内容。
# 将所有GeoDataFrames转换为本地坐标系admin_district_2 = \ admin_district[['district_id', 'geometry']].to_crs(31282)admin_census_2 = \ admin_census[['census_district_id', 'geometry']].to_crs(31282)gdf_green_2 = gdf_green.to_crs(31282)计算以国际单位表示的行政单位面积:
admin_district_2['admin_area'] = \ admin_district_2.geometry.apply(lambda g: g.area)admin_census_2['admin_area'] = \ admin_census_2.geometry.apply(lambda g: g.area)display(admin_district_2.head(1))display(admin_census_2.head(1))4. 计算人均绿地面积比例
4.1 计算每个行政单位的绿地覆盖率
我将使用GeoPandas的叠加函数将这两个行政边界GeoDataFrame与包含绿地多边形的GeoDataFrame叠加。然后,计算每个绿地区域落入不同行政区域的面积。接下来,将这些面积汇总到每个行政区域的级别,包括区和人口普查区。在最后一步中,对于每个分辨率单位,我将添加先前计算的行政官方单位面积,并计算每个区和人口普查区的总面积与绿地面积之比。
gdf_green_mapped_distr = gpd.overlay(gdf_green_2, admin_district_2)gdf_green_mapped_distr['green_area'] = \ gdf_green_mapped_distr.geometry.apply(lambda g: g.area) gdf_green_mapped_distr = \ gdf_green_mapped_distr.groupby(by = 'district_id').sum()[['green_area']]gdf_green_mapped_distr = \ gpd.GeoDataFrame(admin_district_2.merge(gdf_green_mapped_distr, left_on = 'district_id', right_index = True))gdf_green_mapped_distr['green_ratio'] = \ gdf_green_mapped_distr.green_area / gdf_green_mapped_distr.admin_areagdf_green_mapped_distr.head(3)
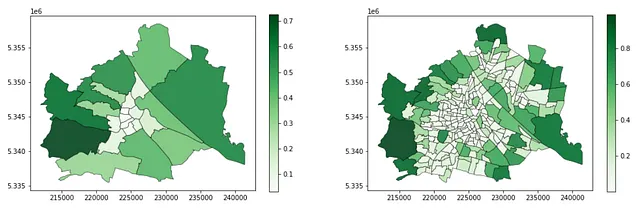
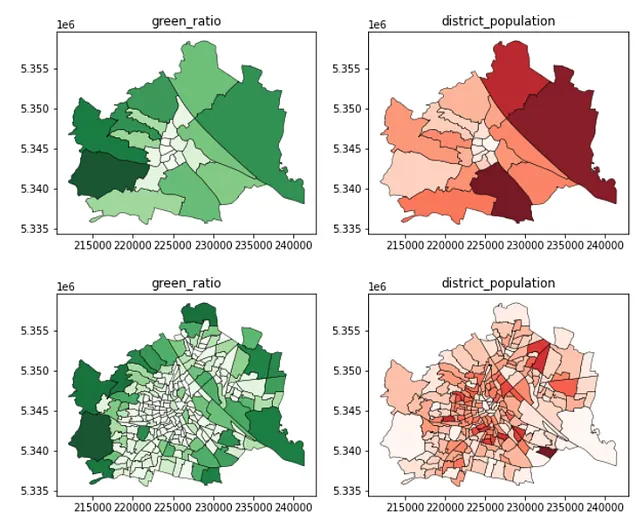
gdf_green_mapped_cens = gpd.overlay(gdf_green_2, admin_census_2)gdf_green_mapped_cens['green_area'] = \ gdf_green_mapped_cens.geometry.apply(lambda g: g.area)gdf_green_mapped_cens = \ gdf_green_mapped_cens.groupby(by = 'census_district_id').sum()[['green_area']]gdf_green_mapped_cens = \ gpd.GeoDataFrame(admin_census_2.merge(gdf_green_mapped_cens, left_on = 'census_district_id', right_index = True))gdf_green_mapped_cens['green_ratio'] = gdf_green_mapped_cens.green_area / gdf_green_mapped_cens.admin_areagdf_green_mapped_cens.head(3)最后,可视化每个区和人口普查区的绿地比例!结果似乎非常有意义,外围地区的绿化程度较高,中心地区则较低。此外,250个人口普查区清楚地展示了不同社区特征的更详细、更精细的图像,为城市规划者提供了更深入、更局部的见解。另一方面,区级信息只有十分之一的空间单位,显示的是总体平均值。
f, ax = plt.subplots(1,2,figsize=(17,5))gdf_green_mapped_distr.plot(ax = ax[0], column = 'green_ratio', edgecolor = 'k', linewidth = 0.5, alpha = 0.9, legend = True, cmap = 'Greens')gdf_green_mapped_cens.plot(ax = ax[1], column = 'green_ratio', edgecolor = 'k', linewidth = 0.5, alpha = 0.9, legend = True, cmap = 'Greens')这段代码输出以下地图:
4.2 为每个行政单位添加人口和收入信息
在本节的最后一步中,让我们将统计数据映射到行政区域。提醒:我们既有区级别的人口数据,也有人口普查区级别的人口数据。然而,我只能在区级别找到收入(社会经济水平指标)数据。这是地理空间数据科学中常见的权衡。虽然一个维度(绿地)在更高分辨率(人口普查区)上更具洞察力,但数据的限制可能会迫使我们仍然使用较低分辨率。
display(admin_census_2.head(2))display(df_pop_cens_2.head(2))
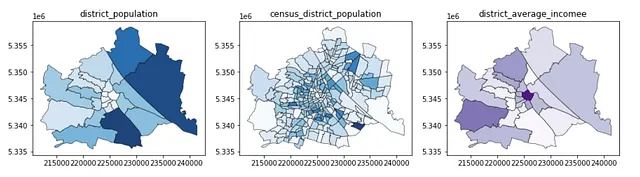
gdf_pop_mapped_distr = admin_district_2.merge(df_pop_distr_2, \ left_on = 'district_id', right_index = True)gdf_pop_mapped_cens = admin_census_2.merge(df_pop_cens_2, \ left_on = 'census_district_id', right_index = True)gdf_inc_mapped_distr = admin_district_2.merge(df_inc_distr_2, \ left_on = 'district_id', right_index = True)f, ax = plt.subplots(1,3,figsize=(15,5))gdf_pop_mapped_distr.plot(column = 'district_population', ax=ax[0], \ edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Blues')gdf_pop_mapped_cens.plot(column = 'census_district_population', ax=ax[1], \ edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Blues')gdf_inc_mapped_distr.plot(column = 'district_average_income', ax=ax[2], \ edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Purples')ax[0].set_title('district_population')ax[1].set_title('census_district_population')ax[2].set_title('district_average_incomee')这些代码块的结果如下图所示:
4.3. 每人绿地面积计算
现在让我们总结一下,所有这些都集成到对应维也纳地区和人口普查地区的合适的shapefiles中:
在地区级别上,我们有绿地比例、人口和收入数据
在人口普查地区级别上,我们有绿地比例和人口数据
为了简化绿地平等的捕捉,我合并了地区和人口普查地区中关于绿地面积绝对值和人口的信息,并计算了每人的总绿地面积。
让我们来看看我们的输入 – 绿地覆盖率和人口:
# 为区域绘制图表,ax = plt.subplots(1,2,figsize=(10,5))gdf_green_mapped_distr.plot( ax = ax[0], column = 'green_ratio', edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Greens')gdf_pop_mapped_distr.plot( ax = ax[1], column = 'district_population', edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Reds')ax[0].set_title('green_ratio')ax[1].set_title('district_population')# 为人口普查区绘制图表,ax = plt.subplots(1,2,figsize=(10,5))gdf_green_mapped_cens.plot( ax = ax[0], column = 'green_ratio', edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Greens')gdf_pop_mapped_cens.plot(ax = ax[1], column = 'census_district_population', edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Reds')ax[0].set_title('green_ratio')ax[1].set_title('district_population')这些代码块的结果如下图所示:
为了计算每人的绿地面积,我将首先在以下步骤中合并绿地和人口数据框。我将通过人口普查地区的例子来做这个示范,因为其更高的空间分辨率能够更好地观察到出现的模式(如果有的话)。确保我们不要除以零,并且遵循常识;让我们删除那些没有人口的区域。
gdf_green_pop_cens = \ gdf_green_mapped_cens.merge(gdf_pop_mapped_cens.drop( \ columns = ['geometry', 'admin_area']), left_on = 'census_district_id',\ right_on = 'census_district_id')[['census_district_id', \ 'green_area', 'census_district_population', 'geometry']]gdf_green_pop_cens['green_area_per_capita'] = \ gdf_green_pop_cens['green_area'] / \ gdf_green_pop_cens['census_district_population']gdf_green_pop_cens = \ gdf_green_pop_cens[gdf_green_pop_cens['census_district_population']>0]f, ax = plt.subplots(1,1,figsize=(10,7))gdf_green_pop_cens.plot( column = 'green_area_per_capita', ax=ax, cmap = 'RdYlGn', edgecolor = 'k', linewidth = 0.5)admin_district.to_crs(31282).plot(\ ax=ax, color = 'none', edgecolor = 'k', linewidth = 2.5)这些代码块的结果如下图所示:
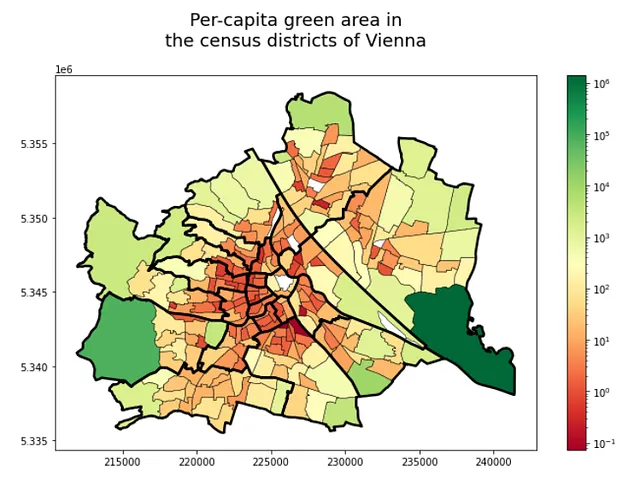
让我们稍微调整一下可视化效果:
f,ax = plt.subplots(1,1,figsize=(11,7))ax.set_title('维也纳人口普查区的人均绿地面积',fontsize = 18, pad = 30)gdf_green_pop_cens.plot(column = 'green_area_per_capita',ax=ax,cmap = 'RdYlGn',edgecolor = 'k',linewidth = 0.5,legend=True,norm=matplotlib.colors.LogNorm(vmin=gdf_green_pop_cens.green_area_per_capita.min(),vmax=gdf_green_pop_cens.green_area_per_capita.max()),)admin_district.to_crs(31282).plot(ax=ax,color = 'none',edgecolor = 'k',linewidth = 2.5)这段代码的结果如下图所示:
对于区域来说也是一样:
# 计算人均绿地面积得分gdf_green_pop_distr = gdf_green_mapped_distr.merge(gdf_pop_mapped_distr.drop(columns = ['geometry', 'admin_area']), left_on = 'district_id', right_on = 'district_id')[['district_id', 'green_area', 'district_population', 'geometry']]gdf_green_pop_distr = gdf_green_pop_distr[gdf_green_pop_distr.district_population>0]gdf_green_pop_distr['green_area_per_capita'] = gdf_green_pop_distr['green_area'] / gdf_green_pop_distr['district_population']# 可视化区域级地图f, ax = plt.subplots(1,1,figsize=(10,8))ax.set_title('维也纳各区的人均绿地面积',fontsize = 18, pad = 26)gdf_green_pop_distr.plot(column = 'green_area_per_capita', ax=ax,cmap = 'RdYlGn',edgecolor = 'k',linewidth = 0.5,legend=True,norm=matplotlib.colors.LogNorm(vmin=gdf_green_pop_cens.green_area_per_capita.min(),vmax=gdf_green_pop_cens.green_area_per_capita.max()),)admin_city.to_crs(31282).plot(ax=ax,color = 'none',edgecolor = 'k',linewidth = 2.5)这段代码的结果如下图所示:
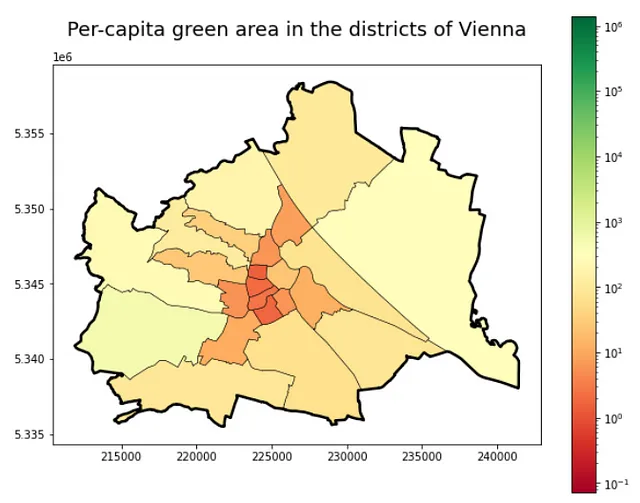
尽管重要的趋势很明显——外围地区每个人都有更多的绿地,内城区则相反。然而,这两个图,尤其是在人口普查区级别的更详细的图,清楚地显示了人们在不同地区享受的绿地面积的差异。进一步的研究和整合额外的数据来源,例如土地利用情况,可能有助于更好地解释为什么这些地区在绿地面积或人口方面更高。现在,让我们享受这张地图,并希望每个人都能在家中找到适量的绿地!
# 合并绿地、人口和财务数据gdf_district_green_pip_inc = gdf_green_pop_distr.merge(gdf_inc_mapped_distr.drop(columns = ['geometry']))可视化财务和绿地维度之间的关系:
f,ax = plt.subplots(1,1,figsize=(6,4))ax.plot(gdf_district_green_pip_inc.district_average_income, \ gdf_district_green_pip_inc.green_area_per_capita, 'o')ax.set_xscale('log')ax.set_yscale('log')ax.set_xlabel('district_average_income')ax.set_ylabel('green_area_per_capita')这段代码的结果是以下散点图:
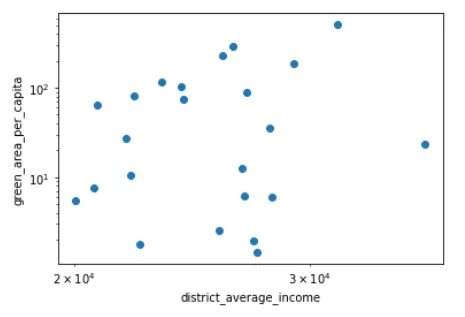
乍一看,这个散点图并没有特别强的证据表明财务状况决定了人们对绿地的接触。老实说,我对这些结果感到有些惊讶——然而,考虑到维也纳在绿化城市方面的有意识的、长期努力,这可能是我们在这里没有看到任何主要趋势的原因。为了确认,我还检查了这两个变量之间的相关性:
print(spearmanr(gdf_district_green_pip_inc.district_average_income, gdf_district_green_pip_inc.green_area_per_capita))print(pearsonr(gdf_district_green_pip_inc.district_average_income, gdf_district_green_pip_inc.green_area_per_capita))由于财务数据的重尾分布,我更认真地对待Spearman(0.13)相关性,在这里,即使Pearson相关性(0.30)也意味着相对较弱的趋势,与我之前的观察相吻合。






