我们训练机器,然后他们再训练我们:构建人工智能的递归性质
机器训练,再训练我们:构建人工智能的递归性质
1941年5月10日,德国的炸弹将备受赞誉的英国下议院变成了一片燃烧的废墟;这座著名的哥特式复兴建筑群已经屹立了两个多世纪,作为激烈政治辩论的背景,然而现在这个建筑象征却变成了灰烬。在烟雾中,一个紧迫的问题浮现出来-重建与过去完全相同,还是拥抱像国外那种宽敞的半圆形大厅这样的现代设计?对于温斯顿·丘吉尔来说,答案是明确的。在1943年的一次演讲中,他说:“我们塑造我们的建筑物,然后我们的建筑物塑造我们”,他相信旧议院的对抗性亲密感融入了英国民主的喧嚣灵魂。

与广阔的外国立法空间(如美国国会大厦的半圆形布局)不同,旧的下议院把427个座位紧密地挤在一起,把相对立的派系面对面地安排在一个狭窄的过道上,无处可躲。民主精神是由直接对抗而推动的,这导致了问责制。尽管可能喧闹而混乱,但它是真实的。尽管对功能的改进持开放态度,但丘吉尔推动恢复竞技场。尽管遭受了破坏,保留曾经容纳了几个世纪喧闹辩论的形状是首要任务。
丘吉尔的观点-建筑空间塑造了集体生活-超越了建筑设计。这种观念有时被称为“建筑决定论”,它认为我们的建筑环境深刻地影响人类行为。城市规划师有意识地应用这些原则,扩宽人行道以促进城市大道上的行人活动。或者考虑一座蜿蜒小溪上的古雅单车道桥-其狭窄促进了耐心和合作,驾驶员礼貌地等待轮到他们过桥。
在数字时代,建筑决定论通过在构建人工智能系统时做出的选择得以体现,这将塑造大型语言模型在社会中的结构。
塑造我们的助手:通过人类反馈教授人工智能
当OpenAI在2019年推出GPT-2时,这个自然语言模型代表了一个飞跃。通过无监督学习训练了40 GB的互联网文本,它的15亿个参数能够生成非常连贯的段落。然而,仍然存在不一致。没有人类的指导,GPT-2令人印象深刻但毫无目标的能力会产生冗长的胡言乱语,而不是有用的信息。
为了完善他们的创作,OpenAI开创了一种新的方法:通过人类反馈进行强化学习(RLHF)。这种技术在论文《通过人类反馈对语言模型进行微调》中详细介绍,将人类直觉与人工智能相结合,引导模型朝着更“有用”的行为方向发展。
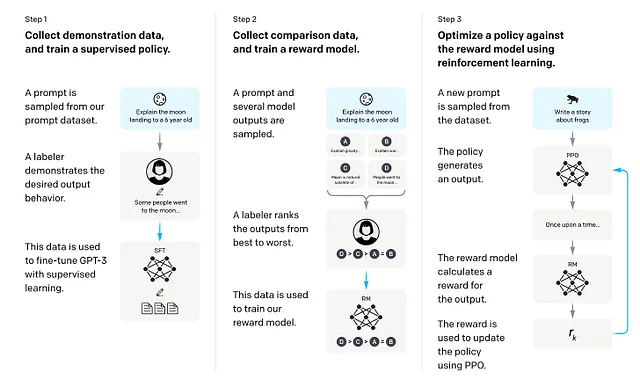
它的工作原理如下:从像GPT-2这样的基础模型开始,人类教练与系统进行互动,扮演用户和人工智能的角色。这种对话创造了反映人类偏好的数据集。然后,教练通过对模型的样本回答进行排名来进一步塑造模型,允许开发出一个根据质量评分输出的“奖励模型”。通过不断的反馈和改进循环,RLHF将曾经不稳定的模型塑造成更有帮助、更准确的伴侣。
这种方法的成果在2022年的ChatGPT中得到体现。通过使用RLHF进行训练,它以深思熟虑、对话性强的回应让用户惊叹不已。
人类智慧的高代价
在ChatGPT的突破之后,其他人工智能实验室迅速采用了通过人类反馈进行强化学习(RLHF)的方法。DeepMind、Anthropic和Meta等公司都依靠RLHF来打造像Sparrow、Claude和LLaMA-2-chat这样的助手。
然而,尽管有效,RLHF需要大量的资源。每一轮都涉及人类教练生成对话、评估回应并进行大规模的指导。对于GPT-3,OpenAI将这个费时费力的过程外包给了肯尼亚的承包商。这个“非营利组织”的财务支持使得这种人力驱动的方法成为可能,但这样的成本限制了许多人的可及性。
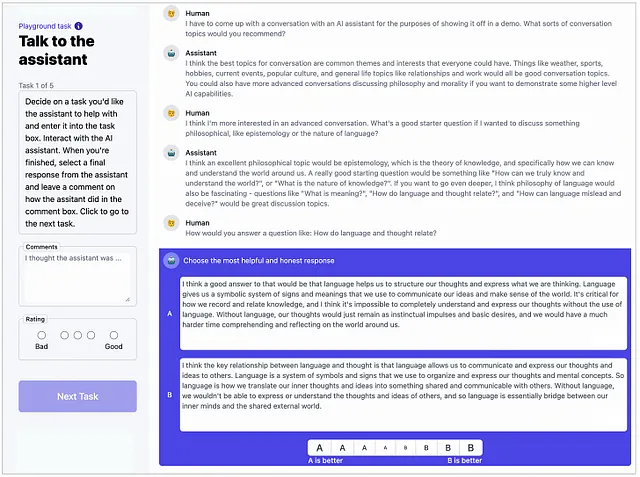
一些组织正在寻求创新方法来克服这个障碍。开放助手项目邀请公众通过众包平台直接参与模型训练。DataBricks在内部将这个过程进行了游戏化,鼓励其5000名员工通过一个有趣的网络界面来评判样本交互。这使他们能够快速构建自己的助手Dolly的数据集。像Scale AI这样的初创公司也提供管理强化学习人工标注所需的服务。
复制同学:使用LLMs相互启动
由于RLHF的高昂价格使许多人望而却步,一些研究人员正在通过用其他语言模型的输出替代人类反馈来降低成本。
斯坦福大学的人类中心AI小组展示了这种捷径。他们试图将Meta的70亿参数的LLaMA改造成一个更有能力的助手,比如ChatGPT,他们编写了175个种子任务,并使用OpenAI的DaVinci模型生成了一个包含52,000个示例的数据集,仅花费了500美元。与其费力地进行人工标注,DaVinci可以自动产生带标签的数据。在这个合成数据集上对LLaMA进行微调,所得到的Alpaca-7B是一个熟练的助手,总共只花费了600美元。
加州大学伯克利分校的研究人员合作使用从ShareGPT(一个人们分享ChatGPT对话的网站)中爬取的70,000个对话来训练具有130亿参数的Vicuna模型。Vicuna达到了ChatGPT性能的90%,而训练成本只是其一小部分。
与此同时,微软和北京大学开发了一种名为Evol-Instruct的新方法,使用LLM以指数级增长种子数据。他们所得到的WizardLM甚至在某些技能上超过了GPT-4,展示了合成数据集的强大之处。
像RedPajama的1.2万亿令牌的LLaMA的开源数据集也旨在使模型训练民主化。
我们变成我们所看到的。我们塑造我们的工具,然后我们的工具塑造我们
丘吉尔几个世纪前就认识到,构建的空间会塑造集体规范。随着LLMs通过合成训练循环的扩散,他的洞察一次又一次地被证明是正确的。在这些初始模型中做出的架构选择会传播到它们的输出训练新一代模型。早期的缺陷和偏见会悄然影响下一代,从而塑造了讨论本身。
当LLMs每天生成被数百万人阅读的文本时,它们的个性会渗透到人类表达中。当专门为引人入胜的聊天进行优化的模型为作家提供建议时,它们的倾向会融入到发布的内容中。我们的工具反映了我们的价值观,并且随着时间的推移,它们会以它们自己的形象改变我们。
但是创造者与创作之间的这种互动并不是异常的——这是人类进步的故事。从印刷机到电视,发明品总是回到影响它们创造者的圈子中。LLMs只是最新的发明,塑造了社会,同时也受到我们的塑造。