使用Amazon SageMaker上的联邦学习,使用分散的训练数据进行机器学习
在Amazon SageMaker上使用联邦学习,训练分散的数据进行机器学习
机器学习(ML)正在革新各个行业的解决方案,并从数据中驱动新形式的洞察力和智能。许多ML算法在大型数据集上进行训练,从中概括出数据中的模式,并在处理新的未见记录时从这些模式中推断结果。通常,如果数据集或模型太大,无法在单个实例上进行训练,则分布式训练允许在集群中使用多个实例,并在训练过程中在这些实例之间分发数据或模型分区。Amazon SageMaker SDK提供了对分布式训练的原生支持,以及流行框架的示例笔记本。
然而,有时由于组织内部或组织间的安全和隐私规定,数据分散在多个帐户或不同区域中,无法集中到一个帐户或跨区域。在这种情况下,应考虑使用联邦学习(FL)来获得整体数据上的广义模型。
在本文中,我们将讨论如何在Amazon SageMaker上实现联邦学习,以在分散的训练数据上运行ML。
什么是联邦学习?
联邦学习是一种ML方法,允许多个独立的训练会话并行地跨越较大的边界运行,并在过程中聚合结果以构建一个广义模型(全局模型)。更具体地说,每个训练会话使用自己的数据集并获得自己的本地模型。在训练过程中,不同训练会话中的本地模型将被聚合(例如,模型权重聚合)成一个全局模型。这种方法与集中式ML技术相对立,其中数据集被合并为一个训练会话。
联邦学习与云上分布式训练
当这两种方法在云上运行时,分布式训练发生在一个帐户的一个区域内,训练数据从一个集中的训练会话或作业开始。在分布式训练过程中,数据集被分割成较小的子集,并根据策略(数据并行或模型并行)将子集发送到不同的训练节点或通过训练集群中的节点,这意味着个别数据不一定保留在集群的一个节点中。
相比之下,联邦学习通常发生在多个独立的帐户或跨区域之间。每个帐户或区域都有自己的训练实例。训练数据从开始到结束都分散在帐户或区域之间,个别数据仅在联邦学习过程中在不同帐户或区域之间的各自训练会话或作业中被读取。
Flower联邦学习框架
有几个开源框架可供联邦学习使用,例如FATE、Flower、PySyft、OpenFL、FedML、NVFlare和Tensorflow Federated。选择FL框架时,通常考虑其对模型类别、ML框架和设备或操作系统的支持。我们还需要考虑FL框架的可扩展性和包大小,以便在云上高效运行。在本文中,我们选择了一个易于扩展、可定制和轻量级的框架Flower,使用SageMaker进行FL实现。
Flower是一个综合性的FL框架,通过提供新的设施来运行大规模的FL实验,并支持丰富的异构FL设备场景,与现有框架有所区别。FL解决了在不可能共享数据的情况下与数据隐私和可扩展性相关的挑战。
Flower FL的设计原则和实现
Flower FL在设计上是与语言无关和ML框架无关的,是完全可扩展的,并且可以整合新的算法、训练策略和通信协议。Flower是根据Apache 2.0许可证开源的。
FL实现的概念架构在论文《Flower: A friendly Federated Learning Framework》中进行了描述,并在下图中突出显示。
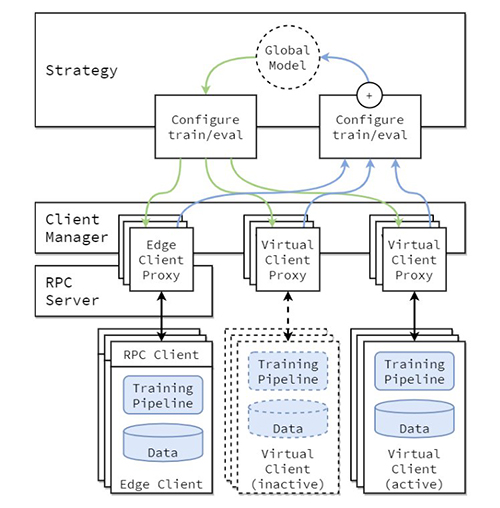
在这个架构中,边缘客户端位于实际的边缘设备上,并通过RPC与服务器通信。另一方面,虚拟客户端在不活动时几乎不消耗资源,仅在选择其进行训练或评估时将模型和数据加载到内存中。
Flower服务器构建策略和配置,将这些配置字典(或简称为配置字典)序列化为它们的ProtoBuf表示形式,使用gRPC将它们传输到客户端,然后将其反序列化回Python字典。
Flower FL 策略
Flower 允许通过策略抽象来自定义学习过程。策略定义了整个联邦学习过程,包括参数初始化(服务器初始化还是客户端初始化)、初始化运行所需的最小客户端数量、客户端贡献的权重以及训练和评估细节。
Flower 实现了广泛的联邦学习平均算法和强大的通信堆栈。有关实现的平均算法列表和相关研究论文,请参阅 Flower: A friendly Federated Learning Framework 中的以下表格。

使用 SageMaker 进行联邦学习:解决方案架构
使用 Flower 框架在 SageMaker 上实现的联邦学习架构基于双向 gRPC(基础)流。gRPC 定义了交换的消息类型,并使用编译器为 Python 生成有效的实现,但也可以为其他语言生成实现,如 Java 或 C++。
Flower 客户端通过网络接收原始字节数组形式的指令(消息)。然后客户端对指令进行反序列化和运行(在本地数据上进行训练)。然后将结果(模型参数和权重)序列化并发送回服务器。
Flower FL 的服务器/客户端架构在 SageMaker 中使用不同账户中的笔记本实例来定义,并与 Flower 服务器和 Flower 客户端位于同一区域。训练和评估策略以及全局参数在服务器上定义,然后将配置序列化并通过 VPC 对等连接发送到客户端。
笔记本实例客户端启动一个 SageMaker 训练作业,运行一个自定义脚本来触发 Flower 客户端的实例化,客户端反序列化并读取服务器配置,触发训练作业,并发送参数响应。
最后一步发生在服务器上,当服务器策略中指定的运行次数和客户端数量完成时,触发对新聚合参数的评估。评估只在服务器上存在的测试数据集上进行,产生新的改进的准确性指标。
以下图示了在 SageMaker 上使用 Flower 包设置的 FL 架构。
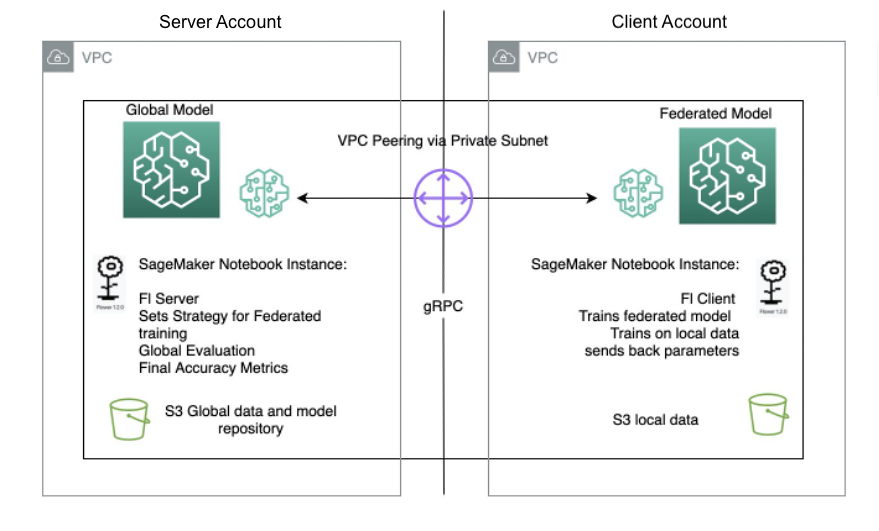
使用 SageMaker 实现联邦学习
SageMaker 是一个全面托管的机器学习服务。使用 SageMaker,数据科学家和开发人员可以快速构建和训练机器学习模型,然后将其部署到生产就绪的托管环境中。
在本文中,我们演示如何使用托管的机器学习平台提供笔记本体验环境,并使用 SageMaker 训练作业在 AWS 账户之间执行联邦学习。原始训练数据永远不会离开拥有数据的账户,只有派生权重会通过对等连接发送。
本文中我们强调以下核心组件:
- 网络 – SageMaker 允许快速设置默认的网络配置,同时也允许您完全自定义网络配置,以满足组织的要求。在本示例中,我们在区域内使用 VPC 对等连接配置。
- 跨账户访问设置 – 为了允许服务器账户中的用户在客户端账户中启动模型训练作业,我们使用 AWS Identity and Access Management (IAM) 角色在账户之间委托访问权限。这样,服务器账户中的用户无需退出账户并登录客户端账户即可在 SageMaker 上执行操作。此设置仅用于启动 SageMaker 训练作业,并不具有任何跨账户数据访问权限或共享。
- 在客户端账户中实现联邦学习客户端代码,在服务器账户中实现服务器代码 – 我们使用 Flower 包和 SageMaker 托管训练在客户端账户中实现联邦学习客户端代码。同时,我们使用 Flower 包在服务器账户中实现服务器代码。
设置 VPC 对等连接
虚拟私有云对等连接是两个虚拟私有云之间的网络连接,使您能够使用私有IPv4地址或IPv6地址在它们之间路由流量。任一VPC中的实例可以像在同一网络中一样相互通信。
要设置虚拟私有云对等连接,首先创建一个与另一个VPC进行对等连接的请求。您可以请求与同一帐户中的另一个VPC进行虚拟私有云对等连接,或者在我们的用例中,连接到不同AWS帐户中的VPC。要激活该请求,VPC的所有者必须接受该请求。有关虚拟私有云对等连接的更多详细信息,请参阅创建虚拟私有云对等连接。
在VPC中启动SageMaker笔记本实例
SageMaker笔记本实例通过完全托管的ML Amazon Elastic Compute Cloud(Amazon EC2)实例提供Jupyter笔记本应用程序。SageMaker Jupyter笔记本用于进行高级数据探索、创建训练作业、将模型部署到SageMaker托管环境以及测试或验证您的模型。
笔记本实例有多种可用的网络配置。在此设置中,我们将笔记本实例运行在VPC的私有子网中,并且没有直接的互联网访问。
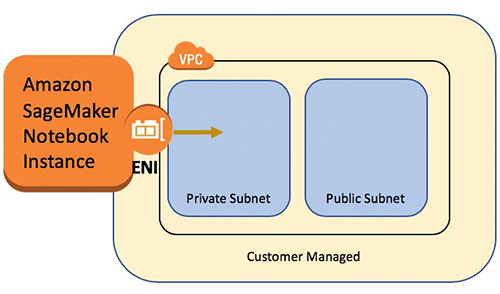
配置跨帐户访问设置
跨帐户访问设置包括两个步骤,通过使用IAM角色将访问权限从服务器帐户委派给客户端帐户:
- 在客户端帐户中创建IAM角色。
- 在服务器帐户中授予该角色的访问权限。
有关设置类似场景的详细步骤,请参阅使用IAM角色在AWS帐户之间委派访问权限。
在客户端帐户中,我们创建一个名为FL-kickoff-client-job的IAM角色,并附加策略FL-sagemaker-actions。策略FL-sagemaker-actions的JSON内容如下:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"sagemaker:CreateTrainingJob",
"sagemaker:DescribeTrainingJob",
"sagemaker:StopTrainingJob",
"sagemaker:UpdateTrainingJob"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"ec2:DescribeSubnets",
"ec2:DescribeVpcs",
"ec2:DescribeNetworkInterfaces"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"iam:GetRole",
"iam:PassRole"
],
"Resource": "arn:aws:iam::<client-account-number>:role/service-role/AmazonSageMaker-ExecutionRole-<xxxxxxxxxxxxxxx>"
}
]
}然后我们修改FL-kickoff-client-job角色的信任策略:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<server-account-number>:root"
},
"Action": "sts:AssumeRole",
"Condition": {}
}
]
}在服务器帐户中,向现有用户(例如developer)添加权限,以允许切换到客户端帐户中的FL-kickoff-client-job角色。为此,我们创建一个名为FL-allow-kickoff-client-job的内联策略,并将其附加到该用户。以下是策略的JSON内容:
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::<client-account-number>:role/FL-kickoff-client-job"
}
}样本数据集和数据准备
在本文中,我们使用由美国医疗保险和医疗补助服务中心(CMS)发布的医疗保险供应商数据中的欺诈检测策划数据集进行训练。数据集被分为训练数据集和测试数据集。由于大部分数据都是非欺诈数据,我们使用SMOTE方法来平衡训练数据集,并将训练数据集进一步分割为训练部分和验证部分。训练和验证数据都被上传到亚马逊简单存储服务(Amazon S3)桶中,用于客户账户中的模型训练,而测试数据集仅用于服务器账户进行测试。数据准备代码的详细信息在以下的笔记本中。
使用SageMaker预构建的scikit-learn框架和SageMaker管理的训练过程,我们在这个数据集上使用联邦学习进行训练,训练一个逻辑回归模型。
在客户账户中实现联邦学习客户端
在客户账户的SageMaker笔记本实例中,我们准备了一个client.py脚本和一个utils.py脚本。client.py文件包含了客户端的代码,而utils.py文件包含了一些在训练过程中需要的实用函数的代码。我们使用scikit-learn包来构建逻辑回归模型。
在client.py中,我们定义了一个Flower客户端。客户端是从fl.client.NumPyClient类派生出来的。它需要定义以下三个方法:
- get_parameters – 它返回当前本地模型的参数。实用函数
get_model_parameters会完成这个任务。 - fit – 它定义了在客户端账户的训练数据上训练模型的步骤。它还从服务器接收全局模型参数和其他配置信息。我们使用接收到的全局参数更新本地模型的参数,并继续在客户账户的数据集上训练模型。这个方法还会将训练后的本地模型参数、训练集的大小以及一个传递任意值的字典发送回服务器。
- evaluate – 它使用客户账户中的验证数据评估提供的参数。它返回损失和其他详细信息,比如验证集的大小和准确率,发送给服务器。
下面是Flower客户端定义的代码片段:
"""客户端接口"""
class FlowerClient(fl.client.NumPyClient):
def get_parameters(self, config):
return utils.get_model_parameters(model)
def fit(self, parameters, config):
utils.set_model_params(model, parameters)
with warnings.catch_warnings():
warnings.simplefilter("ignore")
model.fit(X_train, y_train)
return utils.get_model_parameters(model), len(X_train), {}
def evaluate(self, parameters, config):
utils.set_model_params(model, parameters)
loss = log_loss(y_test, model.predict_proba(X_test))
accuracy = model.score(X_test, y_test)
return loss, len(X_test), {"accuracy": accuracy}然后我们使用SageMaker脚本模式来准备client.py文件的其余部分。这包括定义将传递给SageMaker训练的参数、加载训练和验证数据、在客户端上初始化和训练模型、设置Flower客户端与服务器通信,并最后保存训练好的模型。
utils.py包含了一些在client.py中调用的实用函数:
- get_model_parameters – 它返回scikit-learn逻辑回归模型的参数。
- set_model_params – 它设置模型的参数。
- set_initial_params – 它将模型的参数初始化为零。这是因为服务器在启动时需要从客户端获取初始模型参数。然而,在scikit-learn框架中,只有在调用
model.fit()之后模型参数才会被初始化。 - load_data – 它加载训练和测试数据。
- save_model – 它将模型保存为
.joblib文件。
由于Flower不是SageMaker预构建的scikit-learn Docker容器中安装的软件包,我们在requirements.txt文件中列出flwr==1.3.0。
我们将所有三个文件(client.py、utils.py和requirements.txt)放在一个文件夹下并进行tar压缩。然后将.tar.gz文件(在本文中命名为source.tar.gz)上传到客户端账户的S3存储桶中。
在服务器账户中实现联邦学习服务器
在服务器账户中,我们在Jupyter笔记本上准备代码。这包括两个部分:服务器首先扮演一个角色,在客户端账户中启动一个训练作业,然后服务器使用Flower进行模型联邦。
扮演角色来在客户端账户中运行训练作业
我们使用Boto3 Python SDK设置AWS安全令牌服务(AWS STS)客户端来扮演FL-kickoff-client-job角色,并设置SageMaker客户端,以便通过使用SageMaker管理的训练过程在客户端账户中运行训练作业:
sts_client = boto3.client('sts')
assumed_role_object = sts_client.assume_role(
RoleArn = "arn:aws:iam::<client-account-number>:role/FL-kickoff-client-job",
RoleSessionName = "AssumeRoleSession1"
)
credentials = assumed_role_object['Credentials']
sagemaker_client = boto3.client(
'sagemaker',
aws_access_key_id = credentials['AccessKeyId'],
aws_secret_access_key = credentials['SecretAccessKey'],
aws_session_token = credentials['SessionToken'],
)使用扮演的角色,我们在客户端账户中创建一个SageMaker训练作业。该训练作业使用SageMaker内置的scikit-learn框架。请注意,以下代码段中的所有S3存储桶和SageMaker IAM角色都与客户端账户相关:
sagemaker_client.create_training_job(
TrainingJobName = training_job_name,
HyperParameters = {
"penalty": "l2",
"max-iter": "10",
"server-address":"<server-ip-address>:8080",
"sagemaker_program": "client.py",
"sagemaker_submit_directory": "s3://<client-account-s3-code-bucket>/client_code/source.tar.gz",
},
AlgorithmSpecification = {
"TrainingImage": training_image,
"TrainingInputMode": "File",
},
RoleArn = "arn:aws:iam::<client-account-number>:role/service-role/AmazonSageMaker-ExecutionRole-<xxxxxxxxxxxxxxx>",
InputDataConfig=[
{
"ChannelName": "train",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "s3://<client-account-s3-data-bucket>/data_prep/",
"S3DataDistributionType": "FullyReplicated",
}
},
},
],
OutputDataConfig = {
"S3OutputPath": "s3://<client-account-s3-bucket-for-model-artifact>/client_artifact/"
},
ResourceConfig = {
"InstanceType": "ml.m5.xlarge",
"InstanceCount": 1,
"VolumeSizeInGB": 10,
},
VpcConfig={
'SecurityGroupIds': [
"<client-account-notebook-instance-security-group>",
],
'Subnets': [
"<client-account-notebook-instance-sunbet>",
]
},
StoppingCondition = {
"MaxRuntimeInSeconds": 86400
},
)使用Flower将本地模型合并为全局模型
我们准备在服务器上进行模型联邦的代码。这包括定义联邦策略及其初始化参数。我们使用先前描述的utils.py脚本中的实用函数来初始化和设置模型参数。Flower允许您定义自己的回调函数,以定制现有的策略。我们使用FedAvg策略,并使用自定义回调函数进行评估和适配配置。请参见以下代码:
"""初始化模型和联邦策略,然后启动服务器"""
model = LogisticRegression()
utils.set_initial_params(model)
strategy = fl.server.strategy.FedAvg(
min_available_clients = 1, # 在开始新的训练轮之前,需要连接到服务器的最小客户端数
min_fit_clients = 1, # 下一轮采样的最小客户端数
min_evaluate_clients = 1,
evaluate_fn = get_evaluate_fn(model, X_test, y_test),
on_fit_config_fn = fit_round,
)
fl.server.start_server(
server_address = args.server_address,
strategy = strategy,
config = fl.server.ServerConfig(num_rounds=3) # 运行3轮
)
utils.save_model(args.model_dir, model)前面的代码段中提到了以下两个函数:
- fit_round – 用于将轮次数发送给客户端。我们将此回调函数作为策略的
on_fit_config_fn参数传递。我们这样做只是为了演示on_fit_config_fn参数的使用。 - get_evaluate_fn – 用于在服务器上进行模型评估。
为了演示目的,我们使用在数据准备阶段设置的测试数据集来对来自客户端账户的联邦模型进行评估,并将结果传递回客户端。然而,值得注意的是,在几乎所有实际使用情况中,服务器账户中使用的数据并不是从客户端账户中使用的数据集中拆分出来的。
在联邦学习过程完成后,SageMaker会将一个model.tar.gz文件作为模型工件保存在客户端账户的S3存储桶中。与此同时,一个model.joblib文件会保存在服务器账户的SageMaker笔记本实例中。最后,我们使用测试数据集在服务器上测试最终模型(model.joblib)。最终模型的测试输出如下:
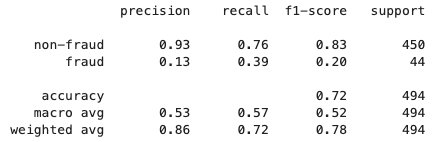
清理
完成后,请清理服务器账户和客户端账户中的资源,以避免额外的费用:
- 停止SageMaker笔记本实例。
- 删除VPC对等连接和相应的VPC。
- 清空并删除用于存储数据的S3存储桶。
结论
在本文中,我们通过使用Flower包在SageMaker上实现了联邦学习。我们展示了如何配置VPC对等连接,设置跨账户访问,并实现了FL客户端和服务器。本文对于那些需要使用受限数据共享的账户之间的分布式数据在SageMaker上训练机器学习模型的人来说非常有用。因为本文中的FL是使用SageMaker实现的,所以值得注意的是SageMaker中还有更多功能可以应用到这个过程中。
在SageMaker上实现联邦学习可以充分利用SageMaker在机器学习生命周期中提供的所有高级功能。在AWS云上还有其他实现或应用联邦学习的方式,例如使用EC2实例或边缘计算。有关这些替代方法的详细信息,请参阅使用FedML在AWS上进行联邦学习和应用边缘计算的机器学习的联邦学习。





