发挥知识图谱的力量:用结构化数据丰富LLM
利用知识图谱丰富LLM的结构化数据
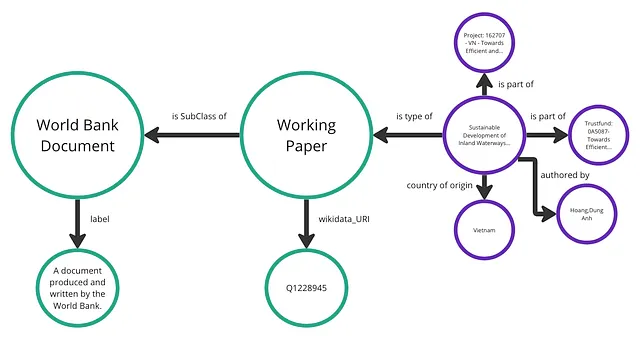
创建知识图谱并探索其提升LLM潜力的逐步指南
有关相关代码,请在此处查看笔记本。
近年来,大型语言模型(LLMs)已经无处不在。其中最著名的LLM可能是ChatGPT,它于2022年11月由OpenAI发布。ChatGPT能够生成想法、提供个性化建议、理解复杂的主题、充当写作助手,或帮助您构建一个模型来预测学院奖项。Meta宣布了他们自己的LLM,名为LLaMA,Google有LaMDA,甚至还有一个开源替代品BLOOM。
LLMs在自然语言处理(NLP)任务中表现出色,如上述任务,因为LLMs历来专注于非结构化数据 —— 没有预定义结构且通常以文本为主的数据。我问ChatGPT:“为什么LLMs历来专注于非结构化数据?”回答是:
“由于非结构化数据的丰富性、可用性和挑战性,LLMs历来专注于非结构化数据。非结构化数据为训练语言模型提供了丰富的资源,使其能够学习模式、上下文和语义。LLMs擅长处理非结构化数据的复杂性和微妙之处,捕捉语言的细微差别,并利用其中包含的丰富上下文、观点和创造性表达。虽然正在努力弥合LLMs和结构化数据之间的差距,但对非结构化数据的历史性重视源于其独特的特征和所提供的宝贵信息,使LLMs能够提供更加人性化的回应。”
结构化数据通常是定量的和良好组织的,通常以行和列的方式组织,正如ChatGPT所指出的,LLMs和结构化数据之间仍存在差距。
另一方面,知识图谱(KG)在查询结构化数据方面表现出色。知识图谱是一个:
“有向标记图,其中将特定领域的含义与节点和边相关联。节点可以表示任何现实世界的实体,例如人、公司、计算机等。边标签捕捉了关系…