全面指南:排名评估指标
全面指南:排名评估指标
探索丰富的度量选择,找到最适合您问题的度量方法
介绍
排序是机器学习中的一个问题,其目标是以最合适的方式对一组文档进行排序,以便最相关的文档出现在顶部。排序出现在数据科学的几个领域,从推荐系统开始,其中算法建议一组购买物品,到自然语言处理搜索引擎结束,其中系统尝试返回最相关的搜索结果。
自然而然地,我们会问如何评估排序算法的质量。与经典机器学习一样,不存在适用于任何类型任务的单一通用度量标准。为什么呢?简单地说,每个度量标准都有其适用范围,这取决于给定问题的性质和数据特征。
这就是为什么了解所有主要的度量标准对于成功解决任何机器学习问题至关重要。这正是我们将在本文中要做的。
然而,在继续之前,让我们先了解为什么某些常用的度量标准通常不适用于排序评估。通过考虑这些信息,我们将更容易理解其他更复杂度量标准的存在的必要性。
注意:本文和使用的公式基于Ilya Markov关于离线评估的演讲。
度量标准
本文将讨论几种信息检索度量标准:
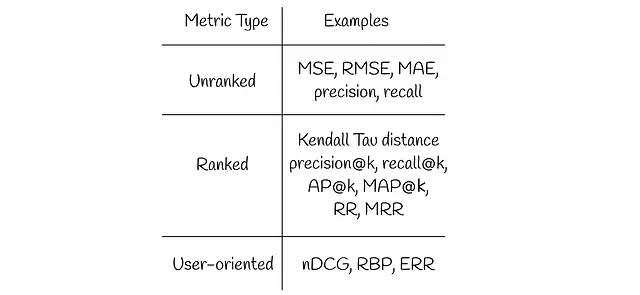
未排序的度量标准
想象一个推荐系统,预测电影的评分并向用户展示最相关的电影。评分通常表示为正实数。乍一看,回归度量标准如均方误差(RMSE、MAE等)似乎是评估系统在留存数据集上的质量的合理选择。
均方误差考虑了所有预测的电影,并测量了真实标签和预测标签之间的平均平方误差。然而,最终用户通常只对出现在网站首页的前几个结果感兴趣。这表明他们对于在搜索结果末尾出现的评分较低的电影并不真正感兴趣,这些电影同样被标准回归度量标准等估计得到。
下面的一个简单例子演示了一对搜索结果,并测量了每个结果中的均方误差值。

尽管第二个搜索结果的均方误差较低,但用户不会对这样的推荐感到满意。通过首先仅查看非相关项,用户必须滚动到底部才能找到第一个相关项。这就是为什么从用户体验的角度来看,第一个搜索结果要好得多:用户只对顶部的项目感到满意,并继续操作,不关心其他项目。
相同的逻辑也适用于分类度量标准(精确度、召回率),它们同样考虑所有项。

所描述的度量标准有什么共同点?所有这些度量标准都平等对待所有项,不考虑高相关和低相关结果之间的任何区别。这就是它们被称为未排序的原因。
通过上面这两个类似的问题示例,设计排名指标时我们应该关注的方面更加清晰:
排名指标应该更加重视相关性更高的结果,而降低或忽略不相关的结果。
排名指标
Kendall Tau距离
Kendall Tau距离是基于排名逆序的数量。
一个逆序是指文档对(i, j),其中文档i的相关性大于文档j,但在搜索结果中出现在j之后。
Kendall Tau距离计算排名中所有逆序的数量。逆序数量越少,搜索结果越好。尽管这个指标看起来很合理,但在下面的示例中仍然存在一个缺点。
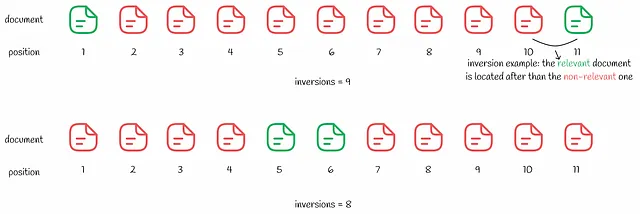
看起来第二个搜索结果只有8个逆序,而第一个搜索结果有9个逆序,所以第二个搜索结果更好。与上面的MSE示例类似,用户只关注第一个相关的结果。通过浏览第二种情况下的几个非相关搜索结果,用户体验将比第一种情况更差。
Precision@k & Recall@k
与通常的精确度和召回率不同,可以只考虑前k个推荐结果。这样,指标不关心排名较低的结果。根据选择的k值,相应的指标分别称为precision@k(“精确度@k”)和recall@k(“召回率@k”)。它们的公式如下所示。

假设前k个结果显示给用户,其中每个结果可能相关或不相关。precision@k衡量前k个结果中相关结果所占的百分比。与此同时,recall@k评估前k个结果中相关结果与整个数据集中相关项的比例。
为了更好地理解这些指标的计算过程,让我们参考下面的示例。
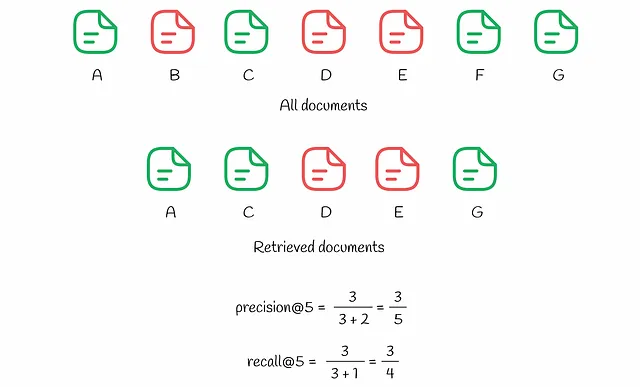
系统中有7个文档(从A到G)。基于其预测,算法从中选择k = 5个文档给用户。我们可以看到,在前k = 5个文档中有3个相关文档(A、C、G),因此precision@5等于3/5。与此同时,recall@5考虑了整个数据集中的相关项:共有4个(A、C、F和G),所以recall@5 = 3/4。
recall@k随着k的增长而增加,使得该指标在某些情况下不太客观。在系统中的所有项都显示给用户的边缘情况下,recall@k的值等于100%。precision@k与recall@k不具有相同的单调性,因为它衡量的是与前k个结果相关的排名质量,而不是与整个系统中相关项的数量相关。客观性是precision@k通常优于recall@k的原因之一。
AP@k(平均精确度)和MAP@k(平均平均精确度)
传统的precision@k存在一个问题,即它不考虑在检索文档中相关项的顺序。例如,如果有10个检索到的文档中有2个相关的,无论这2个文档在10个文档中的位置如何,precision@10始终都是一样的。例如,如果相关项位于位置(1, 2)或(9, 10),该指标无法区分这两种情况,结果导致precision@10等于0.2。
然而,在现实生活中,系统应该给排在前面的相关文档比排在后面的相关文档更高的权重。这个问题可以通过另一个指标来解决,称为平均精度(AP)。和普通的精度一样,AP的取值范围在0到1之间。

AP@k计算的是对于那些第i个文档是相关文档的所有i的取值从1到k的precision@i的平均值。
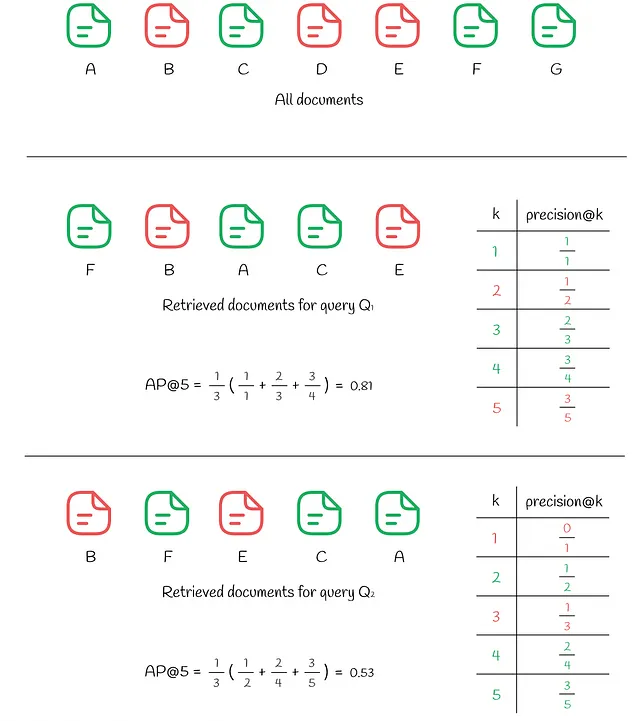
在上面的图中,我们可以看到相同的7个文档。对查询Q₁的响应导致k=5个检索到的文档,其中3个相关文档位于索引(1, 3, 4)。对于每个位置i,计算precision@i:
- precision@1 = 1 / 1
- precision@3 = 2 / 3
- precision@4 = 3 / 4
忽略所有其他不匹配的索引i。AP@5的最终值是上述精度的平均值:
- AP@5 = (precision@1 + precision@3 + precision@4) / 3 = 0.81
为了进行比较,让我们看看对另一个查询Q₂的响应,该查询也包含了k个前面的3个相关文档。然而,这次在前面的k个文档中有2个不相关的文档位于较高的位置(在位置(1, 3)),与之前的情况相比,导致较低的AP@5等于0.53。
有时需要评估算法的质量不仅仅是在单个查询上,而是在多个查询上。为此,使用的是平均平均精度 (MAP)。它简单地取多个查询Q的AP的平均值:
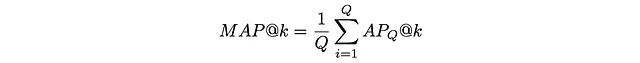
下面的示例显示了如何计算3个不同查询的MAP:

RR (Reciprocal Rank) & MRR (Mean Reciprocal Rank)
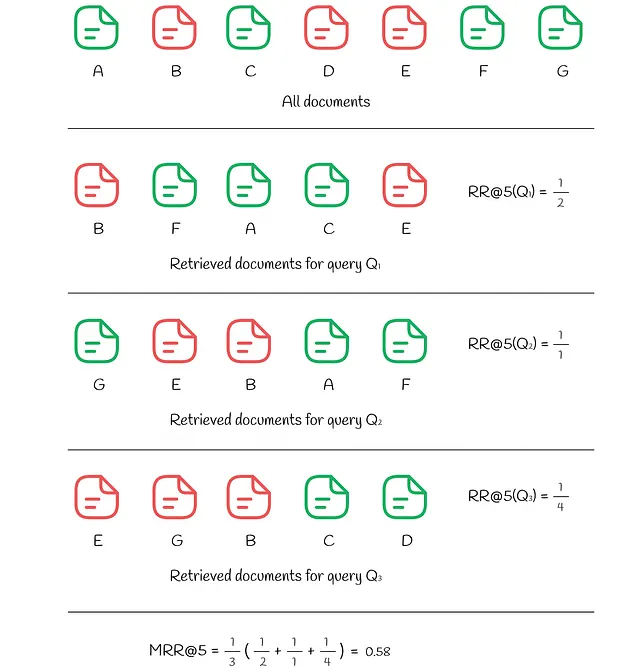
有时用户只对第一个相关结果感兴趣。倒数排名是一种指标,返回一个介于0和1之间的数字,表示第一个相关结果距离顶部有多远:如果文档位于位置k,那么RR的值为1 / k。
类似于AP和MAP,平均倒数排名 (MRR) 测量了多个查询的平均RR。

下面的示例展示了如何针对3个查询计算RR和MRR:
面向用户的指标
尽管排序指标考虑了项目的排序位置,因此比未排序的指标更可取,但它们仍然有一个重要的缺点:不考虑用户行为信息。
面向用户的方法对用户行为进行一定的假设,并基于此产生更适合排序问题的指标。
DCG(折现累积增益)和nDCG(归一化折现累积增益)
DCG指标的使用基于以下假设:
高度相关的文档在搜索引擎结果列表中提前出现(排名更高)更有用——维基百科
这个假设自然地表示了用户如何评估较高的搜索结果,相比于较低的搜索结果。
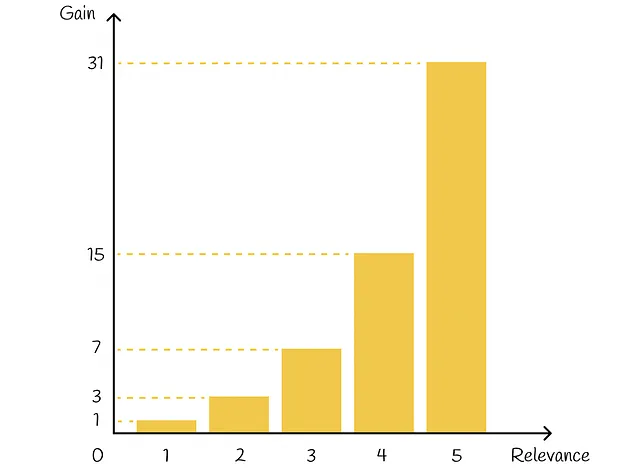
在DCG中,每个文档被分配一个增益值,表示特定文档的相关性。给定每个项目的真实相关性Rᵢ(真实值),有几种方法可以定义增益。其中最流行的之一是:
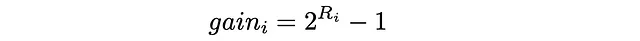
基本上,指数函数对相关项目进行了强调。例如,如果给电影的评级分配一个介于0和5之间的整数,那么每个具有相应评级的电影的重要性将大约是重要性减少1倍的电影的两倍:
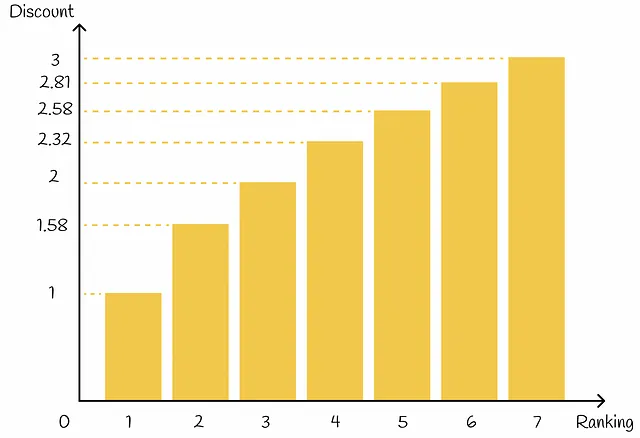
除此之外,基于其排序位置,每个项目都会接收一个折现值:项目的排序位置越高,相应的折现值也越高。折现作为一种惩罚,通过相应地减少项目的增益来进行比例调整。在实践中,折现通常被选择为排名指数的对数函数:
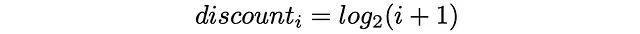
最后,DCG@k被定义为前k个检索到的项目的增益总和除以折现总和:
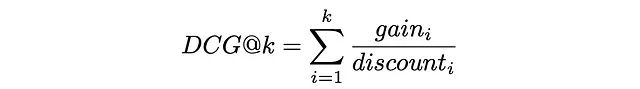
用上面的公式替换增益ᵢ和折现ᵢ,表达式的形式如下:
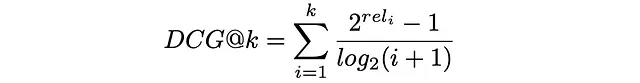
为了使DCG指标更易于解释,通常会通过理想排序时DCGₘₐₓ的最大可能值对其进行规范化,即当所有项目按其相关性正确排序时。得到的指标称为nDCG,取值介于0和1之间。
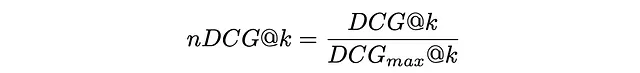
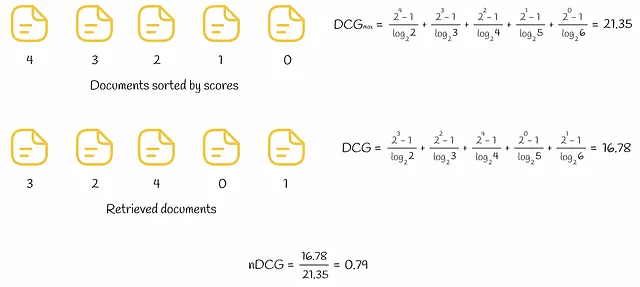
在下面的图中,展示了对5个文档进行DCG和nDCG计算的示例。
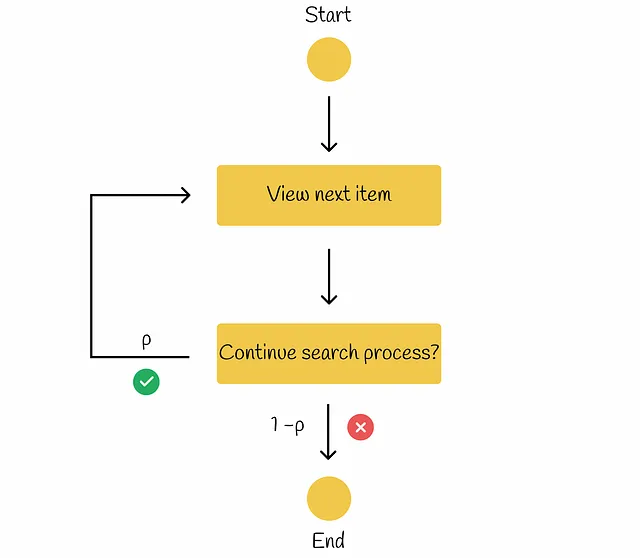
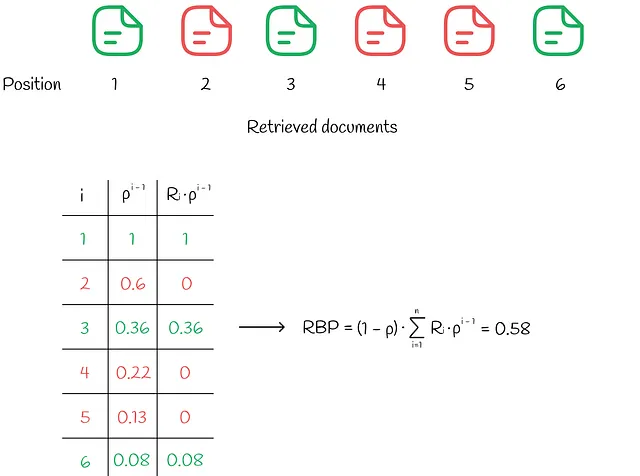
RBP(Rank-Biased Precision)
在RBP的工作流程中,用户并不打算检查每个可能的项目。相反,他或她以概率p从一个文档顺序进行检查,以概率1-p终止当前文档的搜索过程。每个终止决策是独立进行的,不依赖于搜索的深度。根据进行的研究,这种用户行为在许多实验中都有观察到。根据《用于度量检索效果的Rank-Biased Precision》,该工作流程可以在下图中说明。
参数p称为持久性。
在这个范例中,用户总是先看第1个文档,然后以概率p看第2个文档,以概率p²看第3个文档,以此类推。最终,看第i个文档的概率变为:
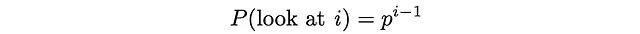
用户只有在刚刚查看了文档i并且搜索过程立即终止的情况下才会检查文档i。
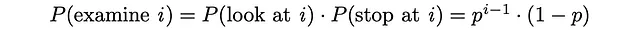
之后,可以估计已检查文档的期望数量。由于0 ≤ p ≤ 1,下面的级数是收敛的,可以将表达式转化为以下格式:

同样,给定每个文档的相关性Rᵢ,我们可以找到期望的文档相关性。较高的期望相关性值表示用户对选择检查的文档更满意。
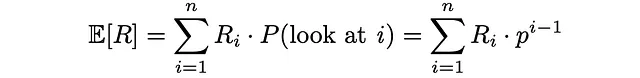
最后,RPB被计算为期望文档相关性(效用)与期望检查文档数量的比值:
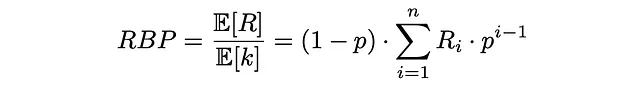
RPB的公式确保它的取值在0和1之间。通常,相关性分数是二进制类型的(如果文档相关则为1,否则为0),但也可以取0到1之间的实数值。
应根据用户在系统中的持久性选择适当的p值。较小的p值(小于0.5)在排名中更加强调排名靠前的文档。较大的p值会减少对前几个位置的权重,并将其分配给较低的位置。有时很难找到一个好的持久性p值,因此最好运行几个实验并选择最有效的p值。
ERR(期望互惠排名)
顾名思义,这个指标测量了许多查询的平均互惠排名。
该模型与RPB类似,但有一点不同:如果当前项目对用户来说是相关的(Rᵢ),则搜索过程结束。否则,如果项目不相关(1 — Rᵢ),则用户以概率p决定是否继续搜索过程。如果是,则搜索进入下一个项目。否则,用户结束搜索过程。
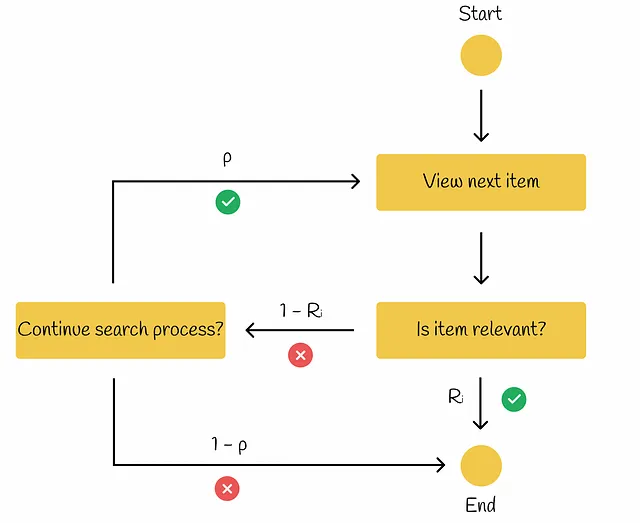
根据Ilya Markov关于离线评估的演示,让我们找到ERR计算的公式。
首先,让我们计算用户查看文档i的概率。基本上,这意味着所有i-1个先前文档都不相关,并且在每次迭代中,用户以概率p继续下一个项目:
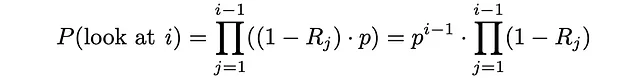
如果用户在文档i处停止,这意味着该文档已经被查看,并且以概率Rᵢ,用户决定终止搜索过程。对应于此事件的概率实际上与互惠排名等于1 / i相同。
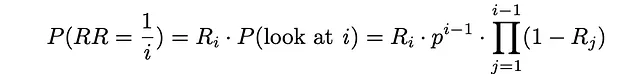
从现在开始,通过简单地使用期望值公式,可以估计期望互惠排名:
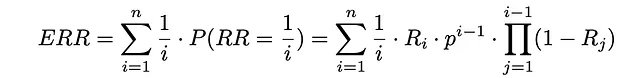
参数p通常选择接近1的值。
与RBP的情况一样,Rᵢ的值可以是二进制或在0到1的范围内的实数。下图演示了对一组6个文档进行ERR计算的示例。
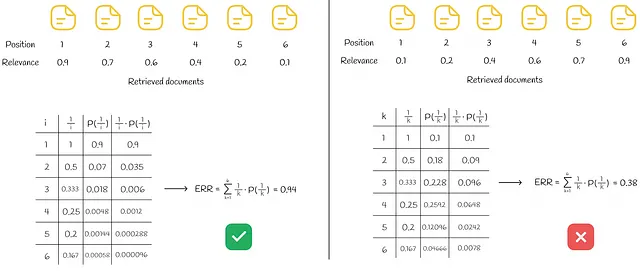
在左侧,所有检索到的文档按其相关性的降序排列,导致最佳的ERR。与右侧的情况相反,文档按其相关性的升序排列,导致最差的ERR。
ERR公式假定所有相关性分数在0到1的范围内。如果初始相关性分数超出该范围,则需要对其进行归一化。其中一种最流行的方法是对其进行指数归一化:
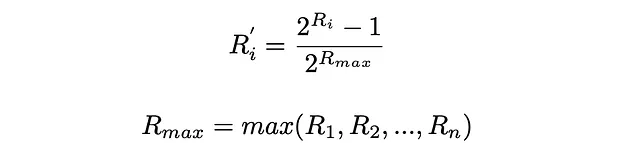
结论
我们已经讨论了信息检索中用于质量评估的所有主要指标。面向用户的度量更常用,因为它们反映了实际用户行为。此外,nDCG、BPR和ERR指标相对于我们迄今为止看到的其他指标具有优势:它们可以处理多个相关性级别,使它们比AP、MAP或MRR等仅适用于二进制相关性级别的指标更加灵活。
不幸的是,所有描述的指标都是不连续或平坦的,导致问题点处的梯度等于0甚至未定义。因此,大多数排名算法很难直接优化这些指标。然而,在这个领域已经进行了大量的研究,并且在最流行的排名算法的内部出现了许多先进的启发式方法来解决这个问题。
资源
- Kendall Tau距离 | 维基百科
- 用于测量检索效果的Rank-Biased Precision
- 折扣累积增益 | 维基百科
- Rank-Biased Precision中的不确定性
- 信息检索,离线评估 | Ilya Markov
除非另有注明,所有图片均为作者所拍摄。






