使用Transformer进行无OCR文档数据提取(2/2)
使用Transformer进行无OCR文档数据提取(2/2)' -> '使用Transformer进行无OCR文档数据提取(2/2)
Donut与Pix2Struct在自定义数据上的对比
这两个转换器模型对文档的理解程度如何?在第二部分中,我将展示如何训练它们,并比较它们在关键索引提取任务中的结果。
微调Donut
接下来我们从第一部分开始,我将解释如何准备自定义数据。我将数据集的两个文件夹压缩并上传到一个新的huggingface数据集中。我在这里使用的colab笔记本可以在这里找到。它将下载数据集,设置环境,加载Donut模型并进行训练。
微调了75分钟后,当验证指标(即编辑距离)达到0.116时,我停止了训练:
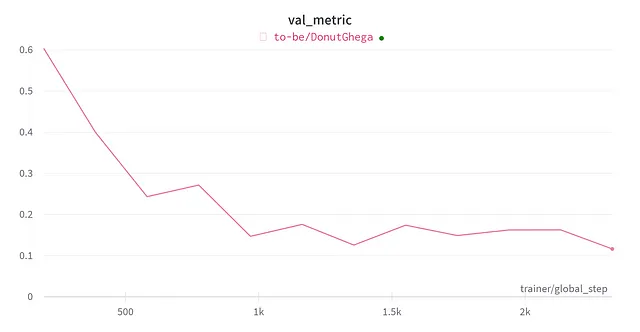
在字段级别上,我得到了验证集的以下结果:
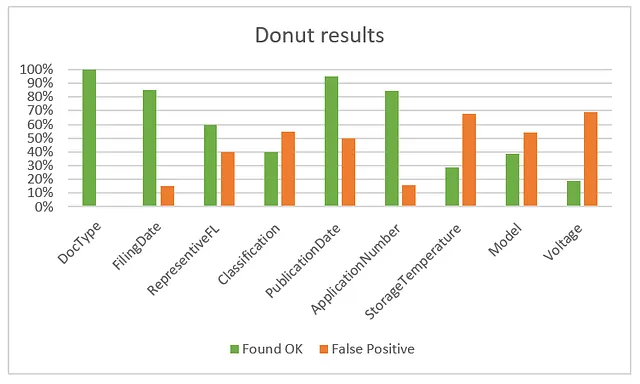
当我们看Doctype时,我们发现Donut总是正确地将文档识别为专利或数据表。因此,我们可以说分类达到了100%的准确率。此外,请注意,即使我们有一个类别为数据表,它也不需要确切的词出现在文档中才能将其分类为数据表。对于Donut来说,这并不重要,因为它被微调为这样识别。
其他字段的得分也相当不错,但仅凭这张图很难说出其中的内部情况。我想看到模型在特定情况下的正确和错误结果。因此,我在我的笔记本中创建了一个例程,用于生成一个HTML格式的报告表格。对于验证集中的每个文档,我有一个如下的行条目:

在左侧是识别出的(推断出的)数据以及其真实值。右侧是图片。我还使用了颜色代码来快速查看:






