使用Scikit-Learn管道自动化机器学习模型的训练和预测
使用Scikit-Learn管道自动化机器学习模型的训练和预测
在本文中,我将尝试通过交叉验证和超参数调整的编码示例,解释Scikit-Learn的管道类的理论和用法。
Scikit-Learn的管道用于在我们的机器学习生命周期中链接多个操作(主要是数据预处理、模型创建和对测试数据的预测)。它们通过减少大量手动编码来帮助我们进行交叉验证和超参数调整。
在深入了解Scikit-Learn的管道之前,让我们首先了解使用这些管道的优势。
便利性和封装性
在将Scikit-Learn的管道纳入到您的代码中之后,您只需要在数据上调用fit和predict方法,就可以对整个预处理和模型训练操作进行拟合。此外,Scikit-Learn的管道使我们可以轻松尝试不同的机器学习算法。
联合参数选择
您可以一次对管道中估计器的所有参数进行网格搜索。
安全性
Scikit-Learn的管道避免了统计数据从交叉验证的测试数据泄漏到训练模型中。这是通过确保用于训练变换器和预测器的数据是相同的来实现的。
我们将使用Kaggle Spaceship Titanic数据集来演示使用Scikit-Learn的管道的用法。在本文中,我将从数据科学项目生命周期的预处理步骤开始。如果您想要查看数据的探索性数据分析,请查看我的其他文章。
使用Python进行探索性数据分析(EDA)的实用指南
在本文中,我将解释数据科学项目生命周期中最重要的部分之一,即…
VoAGI.com
这个问题的数据需要以下预处理:
- 缺失值填充
- 分类数据编码
- 数值数据缩放
- 异常值移除
- 对数正态转换(可选)
Scikit-Learn对于大多数基本预处理操作都有内置的变换器,例如分类数据编码、缺失值填充、缩放等等。但是有时,我们需要对数据执行某些操作,而没有内置的Scikit-Learn变换器。在这种情况下,我们根据自己的需求创建自定义变换器。
Scikit-Learn没有用于异常值移除和对数正态转换的内置变换器。因此,我们将自己创建一个。由于本文的范围是了解如何使用Scikit-Learn的管道,我在这里不会解释如何创建自定义变换器。但是,您仍然可以查看我的其他文章,其中只讨论了自定义变换器。
使用Scikit-Learn类创建自定义变换器的简单方法
在本文中,我将解释如何根据我们的处理需求使用Scikit-Learn创建变换器…
VoAGI.com
创建一个用于异常值移除的自定义变换器
## 创建一个自定义变换器来处理数据中的异常值from sklearn.base import BaseEstimator, TransformerMixinclass Outlier_Remover(BaseEstimator, TransformerMixin): def __init__(self,list_of_feature_names = num_feat): self.list_of_feature_names = list_of_feature_names def fit(self, X, y=None): return self def transform(self, X, y=None): quantiles = X[num_feat].quantile(np.arange(0,1,0.25)).T quantiles = quantiles.rename(columns={0.25:'Q1', 0.50: 'Q2', 0.75:'Q3'}) quantiles['IQR'] = quantiles['Q3'] - quantiles['Q1'] quantiles['Lower_Limit'] = quantiles['Q1'] - 1.5*quantiles['IQR'] quantiles['Upper_Limit'] = quantiles['Q3'] + 1.5*quantiles['IQR'] for feature in num_feat: X[feature] = np.where((X[feature] < quantiles.loc[feature,'Lower_Limit']) | (X[feature] > quantiles.loc[feature,'Upper_Limit']) & (X[feature] is not np.nan), X[feature].median(), X[feature]) return X这里,num_feat是数据中数值特征的名称列表。
创建一个用于对数正态分布的自定义转换器
## 创建一个自定义转换器,用于对特征值执行对数变换class Log_Transformer(BaseEstimator, TransformerMixin): def __init__(self): pass def fit(self, X, y=None): return self def transform(self, X, y=None): for feature in num_feat: X[feature] = np.where(X[feature]==0,np.log(X[feature]+0.0002),np.log(X[feature])) return X创建一个用于数值特征预处理的流水线
Scikit-Learn有一个Pipeline类用于创建流水线。
我们的数值流水线将包含三个步骤。它们是:
- 使用上述创建的转换器进行异常值去除
- 用于删除缺失值的转换器:在这里,我们将使用Scikit-Learn的SimpleImputer转换器执行此任务。
- 用于对数值特征进行缩放的转换器:在这里,我们将使用Scikit-Learn的StandardScaler转换器。
Scikit-Learn的Pipeline对象接受一个元组列表作为参数。每个元组将专门用于一个处理步骤,并且每个处理步骤都有两个参数。第一个参数是步骤的名称,第二个参数是转换器或估计器对象。
Pipeline ([
(process1_name, process1_object),
(process2_name, process2_object),
so on…
])
## 使用sklearn Pipeline类创建一个数值特征预处理流水线from sklearn.pipeline import Pipelinefrom sklearn.impute import SimpleImputerfrom sklearn.preprocessing import MinMaxScalernum_pipe = Pipeline(steps=[ ('outlier_removal',Outlier_Remover()), ('log_transformation',Log_Transformer()), ('replacing_num_missing_values',SimpleImputer(strategy='median', missing_values=np.nan)), ('scaling',MinMaxScaler())]如上面的代码块中所示,outlier_removal、replacing_num_missing_values、log_transformation和scaling是转换器的名称。在每个名称旁边,都提到了相应的转换器对象。
创建一个用于类别特征预处理的流水线
与数值特征类似,我们还将为类别特征创建一个流水线。类别特征在预处理中需要以下步骤:
- 删除无用特征
- 用特征的最频繁值替换缺失值
- 将特征值编码为整数
- 用特征的最频繁值替换缺失值
## 使用sklearn Pipeline类创建一个类别特征预处理流水线from sklearn.preprocessing import OrdinalEncoderfrom sklearn.impute import SimpleImputercat_pipe = Pipeline(steps=[ ('remove_useless_features',Remove_Useless_Features()), ('replacing_cat_missing_values', SimpleImputer(strategy='most_frequent', missing_values=np.nan)), ('encoding', OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=np.nan)), ('replacing_cat_missing_values2', SimpleImputer(strategy='most_frequent', missing_values=np.nan)) # 此步骤是为了确保填充编码步骤中创建的缺失值])在这里,我们在特征值编码之后再次执行缺失值插补。这是因为我们的编码器设计成遇到任何新的类别时都将其编码为null值(如果不是训练数据,这种情况可能会发生在测试数据中)。
将数值和类别预处理流水线组合起来
在之前的步骤中,我们为数据的数值和类别特征分别创建了流水线。因此,现在我们将组合这两个之前创建的流水线,创建一个整体流水线,可以同时预处理所有特征。
Scikit-Learn有一个内置的类来完成这个任务。ColumnTransformer类用于此任务。Scikit-Learn的ColumnTransformer接受一个元组列表作为主要参数。每个元组中有三种信息。第一种是处理的名称,第二种是该操作所需的对象,第三种是需要对其执行此操作的特征名称列表。
## 使用sklearn ColumnTransformer类将数值和类别流水线组合起来preprocess_pipe = ColumnTransformer([ ('num_preprocessing',num_pipe, notable_num_feat), ('cat_preprocessing', cat_pipe, notable_cat_feat)], remainder='drop')这里,cat_preprocessing和num_preprocessing是两个处理过程的名称。cat_pipe和num_pipe是我们在前两步中创建的对象。cat_feat和num_feat是cat_pipe和num_pipe将应用于其上的特征名称列表。
ColumnTransformer ([
(process1_name, process1_object, feature_names1),
(process2_name, process2_object, feature_names2),
等等…
])
请注意,ColumnTransformer还有一个名为remainder的第二个参数。在这里,remainder的’drop’值将删除数据中不在num_feat列表或cat_feat列表中的所有特征。在这种情况下,如果我们将参数remainder的值设置为’pass’,则在预处理步骤中将忽略不在num_feat列表或cat_feat列表中的所有特征,但不会从数据中删除它们。
现在我们已经创建了整个预处理流程,让我们创建一些机器学习模型。
创建一些机器学习模型
## 模型1:支持向量回归from sklearn.svm import SVRsvr = SVR()## 模型2:最近邻回归from sklearn.neighbors import KNeighborsRegressorknr = KNeighborsRegressor()## 模型3:决策树回归from sklearn.tree import DecisionTreeRegressordtr = DecisionTreeRegressor(max_depth=4,random_state=123)## 模型4:随机森林回归from sklearn.ensemble import RandomForestRegressorrfr = RandomForestRegressor()## 模型5:Xgboost回归from xgboost import XGBRegressorxgbr = XGBRegressor(seed=24324)## 模型6:AdaBoost回归from sklearn.ensemble import AdaBoostRegressorabr = AdaBoostRegressor(random_state=123)## 模型7:梯度提升回归from sklearn.ensemble import GradientBoostingRegressorgbr = GradientBoostingRegressor()## 模型8:模型1、模型2和模型4的投票回归from sklearn.ensemble import VotingRegressorvr = VotingRegressor(estimators = [('svr', svr), ('knr', knr), ('rfr', rfr)])## 模型9:light gbm回归from lightgbm import LGBMRegressorlgbmr = LGBMRegressor()## 模型10:catboost回归from catboost import CatBoostRegressorcbr = CatBoostRegressor(verbose=False)我们现在已经有了模型。下一步是将整个预处理流程与上述创建的每个机器学习模型结合起来。为了将预处理流程和模型结合起来,我们将再次使用Scikit-Learn的Pipeline类。
## svr pipeline svr_pipe = Pipeline(steps=[ ('preprocess_pipe', preprocess_pipe), ('svr_model', svr)])## knr pipeline knr_pipe = Pipeline(steps=[ ('preprocess_pipe', preprocess_pipe), ('knr_model', knr)])## dtr pipeline dtr_pipe = Pipeline(steps=[ ('preprocess_pipe', preprocess_pipe), ('dtr_model', dtr)])## rfr pipeline rfr_pipe = Pipeline(steps=[ ('preprocess_pipe', preprocess_pipe), ('rfr_model', rfr)])## xgbr pipeline xgbr_pipe = Pipeline(steps=[ ('preprocess_pipe', preprocess_pipe), ('xgbr_model', xgbr)])## abr pipeline abr_pipe = Pipeline(steps=[ ('preprocess_pipe', preprocess_pipe), ('abr_model', abr)])## gbr pipeline gbr_pipe = Pipeline(steps=[ ('preprocess_pipe', preprocess_pipe), ('gbr_model', gbr)])## vr pipeline vr_pipe = Pipeline(steps=[ ('preprocess_pipe', preprocess_pipe), ('vr_model', vr)])## lgbmr pipeline lgbmr_pipe = Pipeline(steps=[ ('preprocess_pipe', preprocess_pipe), ('lgbmr_model', lgbmr)])## cbr pipeline cbr_pipe = Pipeline(steps=[ ('preprocess_pipe', preprocess_pipe), ('cbr_model', cbr)])这就完成了流水线的创建。在上面的代码块中创建的流水线现在能够在单个fit方法调用中执行预处理和模型构建。要了解有关fit和fit_transform方法的正确使用方法,请查看我的另一篇文章:
scikit-learn fit、transform、fit_transform和predict方法的区别及使用时机…
本文将教您scikit-learn的fit和fit_transform方法之间的基本区别以及何时使用…
VoAGI.com
此外,我们还可以将这些管道用于交叉验证和超参数调优。让我们也看一些例子。
使用管道对数据进行交叉验证
## 从sklearn.model_selection导入KFold和cross_val_scorefrom sklearn.model_selection import KFoldfrom sklearn.model_selection import cross_val_scorepipelines = [svr_pipe, knr_pipe, dtr_pipe, rfr_pipe, xgbr_pipe, abr_pipe, gbr_pipe, vr_pipe, lgbmr_pipe, cbr_pipe]models = ['SupportVectorRegressor', 'KneighborsRegressor', 'DecisionTreeRegressor', 'RandomForestRegressor', 'XgboostRegressor', 'AdaboostRegressor', 'GradientBoostRegressor', 'VotingRegressor', 'LGBMRegressor', 'CatBoostRegressor']cv = KFold(n_splits=10)for index, pipeline in enumerate(pipelines): mean = np.round(cross_val_score(estimator=pipeline, X=X, y=y,cv=cv,scoring='r2').mean(),3) std = np.round(cross_val_score(estimator=pipeline, X=X, y=y,cv=cv,scoring='r2').std(),3) print(f"模型{models[index]}的交叉验证分数为{mean} +/- {std}.")
请注意,在这里我们将管道作为cross_val_score方法的最终估计器。由于我们在最终管道中合并了预处理和模型创建,因此我们不需要进行任何处理。
现在,让我们看一个使用Scikit-Learn管道进行超参数调优的例子,该例子使用了得分最高的r2的算法。
使用Scikit-Learn管道进行超参数调优
让我们为上面创建的每个机器学习模型创建一个超参数字典。
在这里,我们将只对根据交叉验证表现最好的机器学习模型进行超参数调优。
## 要测试的随机森林回归器的超参数rfr_params = { 'n_estimators': np.arange(100,600,100), 'max_depth': np.arange(3,10,1), 'max_features': np.arange(9,28,3), 'bootstrap': [True, False]}## 要测试的梯度提升回归器的超参数gbr_params = { 'learning_rate': np.arange(0.1,1.1,0.1), 'n_estimators': np.arange(100,600,100), 'max_depth': np.arange(3,10,1), 'max_features': np.arange(9,28,3)}## 要测试的XGBoost回归器的超参数xgbr_params = { 'n_estimators': np.arange(100,600,100), 'max_depth': np.arange(2,10,1), 'learning_rate': np.arange(0.1,1.1,0.1)}## 要测试的LGBMRegressor的超参数lgbmr_params = { 'boosting_type': ['gbdt', 'dart'], 'num_leaves': [2,3,4], 'max_depth': np.arange(3,10,1), 'learning_rate': np.arange(0.1,1.1,0.1), 'n_estimators': np.arange(100,600,100)}## 要测试的CatBoost回归器的超参数cbr_params = { 'learning_rate': np.arange(0.1,1.1,0.1), 'max_depth': np.arange(3,10,1), 'n_estimators': np.arange(100,600,100)}现在,让我们进行超参数调优。
from sklearn.model_selection import RandomizedSearchCVtune_models = [rfr, xgbr, gbr, lgbmr, cbr]tune_model_names = ['随机森林回归器', 'XGBoost回归器', '梯度提升回归器', 'LGBM回归器', 'Catboost回归器']tuning_params = [rfr_params, xgbr_params, gbr_params, lgbmr_params, cbr_params]for index, model in enumerate(tune_models): grid = RandomizedSearchCV(model, tuning_params[index], cv=5, scoring='r2',random_state=2434) grid.fit(preprocess_pipe.fit_transform(X),y) print(f"经超参数调优后,模型{tune_model_names[index]}的最佳得分为{grid.best_score_}.") print(f"给出此最佳得分的参数为{grid.best_params_}.\n")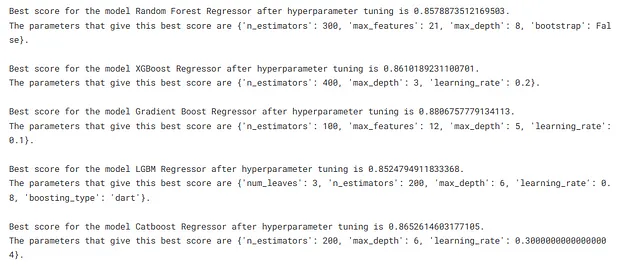
我们已经得到了使我们的模型性能较高的参数。接下来,让我们为我们的模型设置这些参数,并训练流水线。
rfr.set_params(bootstrap=False,max_depth=8,max_features=21,n_estimators=300,random_state=234)xgbr.set_params(learning_rate=0.2, max_depth=3, n_estimators=400)gbr.set_params(n_estimators=100, max_features=12, max_depth=5, learning_rate=0.1, random_state=23432)lgbmr.set_params(boosting_type='dart', learning_rate=0.8, max_depth=6, n_estimators=200, num_leaves=3, random_state=3423)cbr.set_params(learning_rate=0.3, max_depth=6, n_estimators=200, random_seed=2344)训练和保存流水线
我们将在上述创建的所有流水线上训练数据,并保存每个流水线。对于训练,我们只需要提供流水线名称和数据,所有的处理和训练步骤都将自动执行,这都归功于流水线。
import os, picklefor index,pipeline in enumerate(pipelines): model = pipeline.fit(X,y) with open(os.path.join('main_dir',str(models[index])+'.pkl'), 'wb') as f: pickle.dump(model,f)现在,最后一步就是加载新数据并使用高性能训练的流水线进行预测。
Scikit-Learn 的流水线在找到表现最佳的模型方面非常有用,因为它可以让我们同时尝试不同类型的机器学习算法。另外,正如您在上面所看到的,使用流水线在许多机器学习模型上执行交叉验证和超参数调整变得非常简单。基本上,这些流水线通过为我们节省一个个尝试多个算法所需的大量时间,使我们的生活变得更加便捷。
希望您对 Scikit-Learn 的流水线及其用途有了基本的了解。本文中的代码来自我的 Kaggle 个人资料。请查看完整的代码:
房价预测 – Scikit-Learn 流水线
使用 Kaggle 笔记本探索和运行机器学习代码 | 使用来自房价数据的数据 – 高级回归…
www.kaggle.com
有用的资源
Scikit-Learn 文档
名为《动手学习 Scikit-Learn、Keras 和 TensorFlow 的机器学习实战》的书籍
(2025) scikit-learn 技巧 — YouTube
结尾
希望您喜欢本文。关注我在 VoAGI 上阅读更多类似文章。
与我保持联系
网站
给我发邮件至 [email protected]





