使用Langchain和OpenAI为您的Google文档创建聊天机器人
使用Langchain和OpenAI创建Google文档聊天机器人
介绍
在这篇文章中,我们将使用OpenAI和Langchain为您的Google文档创建一个聊天机器人。为什么我们首先要这样做呢?将您的Google文档内容复制粘贴到OpenAI会变得很繁琐。OpenAI有一个字符令牌限制,您只能添加特定数量的信息。因此,如果您想要大规模进行操作,或者想以编程方式进行操作,您将需要一个帮助您的库;这时Langchain就派上用场了。您可以通过将Langchain与Google Drive和Open AI连接起来,创建商业影响,以便您可以对文档进行摘要并提出相关问题。这些文档可以是您的产品文档、研究文档或公司正在使用的内部知识库。
学习目标
- 您可以学习如何使用Langchain获取您的Google文档内容。
- 学习如何将Google文档内容与OpenAI LLM集成。
- 您可以学习如何对文档内容进行摘要和提问。
- 您可以学习如何创建一个根据您的文档回答问题的聊天机器人。
本文是数据科学博文马拉松的一部分。
加载您的文档
在开始之前,我们需要在Google Drive中设置我们的文档。关键部分是Langchain提供的一个名为GoogleDriveLoader的文档加载器。使用它,您可以初始化这个类,然后将一个文档ID列表传递给它。
from langchain.document_loaders import GoogleDriveLoader
import os
loader = GoogleDriveLoader(document_ids=["您的文档ID"],
credentials_path="credentials.json文件的路径")
docs = loader.load()您可以从文档链接中找到您的文档ID。在链接中的/d/之后的斜杠之间可以找到该ID。
例如,如果您的文档链接是https://docs.google.com/document/d/1zqC3_bYM8Jw4NgF,那么您的文档ID是“1zqC3_bYM8Jw4NgF”。
您可以将这些文档ID的列表传递给document_ids参数,而且很酷的是您还可以传递包含您的文档的Google Drive文件夹ID。如果您的文件夹链接是https://drive.google.com/drive/u/0/folders/OuKkeghlPiGgWZdM,则文件夹ID是“OuKkeghlPiGgWZdM1TzuzM”。
授权Google Drive凭据
步骤1:
使用此链接https://console.cloud.google.com/flows/enableapi?apiid=drive.googleapis.com启用GoogleDrive API。请确保您登录的Gmail帐户与您的文档存储在驱动器中的帐户相同。
步骤2:通过单击此链接转到Google Cloud控制台。选择“OAuth客户端ID”。将应用程序类型设置为桌面应用程序。
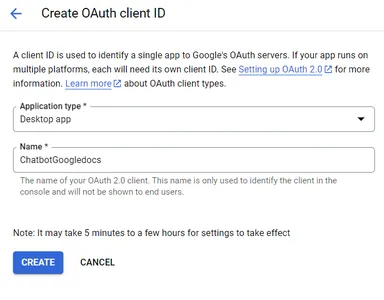
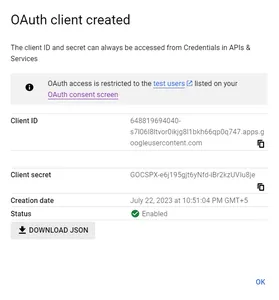
步骤3:创建OAuth客户端后,通过点击“DOWNLOAD JSON”下载凭据文件。如果在创建凭据文件时有任何疑问,您可以按照Google的步骤进行操作。
步骤4:通过运行以下pip命令升级您的Google API Python客户端
pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib然后我们需要将我们的json文件路径传递给GoogleDriveLoader。
总结您的文档
确保您有可用的OpenAI API密钥。如果没有,请按照以下步骤操作:
1.访问”https://openai.com/”并创建您的帐户。
2.登录您的帐户,并在仪表板上选择“API”。
3.现在点击您的个人资料图标,然后选择“查看API密钥”。
4.选择“创建新的秘密密钥”,复制并保存。
接下来,我们需要加载我们的OpenAI LLM。让我们使用OpenAI总结加载的文档。在下面的代码中,我们使用了一个称为summarize_chain的总结算法,该算法由langchain提供,用于创建一个总结过程,我们将其存储在一个名为chain的变量中,该变量使用map_reduce方法接受输入文档并生成简洁的摘要。请在下面的代码中替换您的API密钥。
from langchain.llms import OpenAI
from langchain.chains.summarize import load_summarize_chain
llm = OpenAI(temperature=0, openai_api_key=os.environ['OPENAI_API_KEY'])
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=False)
chain.run(docs)如果运行此代码,您将获得文档的摘要。如果您想查看LangChain在底层执行了什么操作,请将verbose更改为True,然后您可以看到Langchain正在使用的逻辑和思考方式。您可以观察到LangChain将自动插入查询以总结您的文档,并且整个文本(查询+文档内容)将传递给OpenAI。现在OpenAI将生成摘要。
下面是一个用例,我发送了一个与产品SecondaryEquityHub相关的Google Drive文档,并使用map_reduce链类型和load_summarize_chain()函数对文档进行了摘要。我将verbose设置为True,以查看Langchain在内部的工作方式。
from langchain.document_loaders import GoogleDriveLoader
import os
loader = GoogleDriveLoader(document_ids=["ceHbuZXVTJKe1BT5apJMTUvG9_59-yyknQsz9ZNIEwQ8"],
credentials_path="../../desktop_credetnaisl.json")
docs = loader.load()
from langchain.llms import OpenAI
from langchain.chains.summarize import load_summarize_chain
llm = OpenAI(temperature=0, openai_api_key=os.environ['OPENAI_API_KEY'])
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=True)
chain.run(docs)输出:
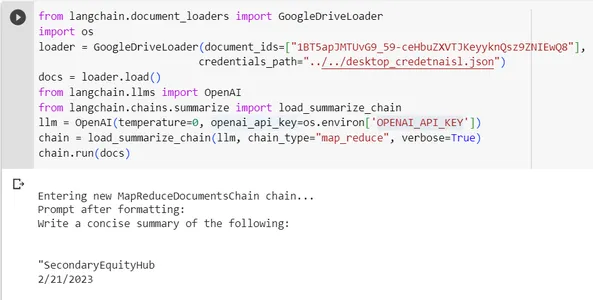
我们可以观察到Langchain插入了提示,以生成给定文档的摘要。

我们可以看到Langchain使用OpenAI LLM生成的简洁摘要和文档中的产品特点。
更多用例
1.研究:在进行研究时,我们可以使用此功能。我们可以使用总结功能快速浏览研究论文,而不是逐字逐句地进行密集阅读。
2.教育:教育机构可以从大量数据、学术书籍和论文中获取策划的教科书内容摘要。
3.业务智能:数据分析师必须阅读大量文件才能从中提取见解。使用此功能,他们可以减少大量的工作量。
4.法律案例分析:法律专业人士可以使用此功能从他们大量的以前类似的案例文件中更快地获取关键论点。
与您的文档相关的问题
假设我们想针对给定文档中的内容提出问题,我们需要加载一个名为load_qa_chain的不同链。接下来,我们使用chain_type参数初始化此链。在我们的例子中,我们使用chain_type作为“stuff”。这是一种直接的链类型;它将所有内容连接起来并传递给LLM。
其他链式类型:
- map_reduce: 在开始时,模型会逐个查看每个文档并存储其洞察力,最后,它会将所有这些洞察力合并起来,再次查看这些合并后的洞察力以获取最终的响应。
- refine:它会迭代地查看给定在document_id列表中的每个文档,然后随着进行,它会使用在文档中找到的最新信息来完善答案。
- Map re-rank:该模型会单独查看每个文档并为洞察力分配一个分数。最后,它将返回得分最高的那个。
接下来,我们通过传递输入文档和查询来运行我们的链式模型。
from langchain.chains.question_answering import load_qa_chain
query = "谁是analytics vidhya的创始人?"
chain = load_qa_chain(llm, chain_type="stuff")
chain.run(input_documents=docs, question=query)当你运行这段代码时,langchain会自动在将其发送给OpenAI LLM之前在你的文档内容前插入提示。在幕后,langchain通过提供优化的提示来帮助我们进行提示工程,以从文档中提取所需的内容。如果你想查看它们内部使用的提示,只需设置verbose=True,然后你可以在输出中看到提示。
from langchain.chains.question_answering import load_qa_chain
query = "谁是analytics vidhya的创始人?"
chain = load_qa_chain(llm, chain_type="stuff", verbose=True)
chain.run(input_documents=docs, question=query)构建你的聊天机器人
现在我们需要找到一种方法将这个模型变成一个问答机器人。主要需要遵循以下三个步骤来创建一个聊天机器人。
1. 聊天机器人应该记住聊天历史,以理解正在进行的对话的上下文。
2. 每次用户询问机器人时,聊天历史应该更新。
3. 聊天机器人应该一直工作,直到用户想要退出对话为止。
from langchain.chains.question_answering import load_qa_chain
# 加载Langchain问答链的函数
def load_langchain_qa():
llm = OpenAI(temperature=0, openai_api_key=os.environ['OPENAI_API_KEY'])
chain = load_qa_chain(llm, chain_type="stuff", verbose=True)
return chain
# 处理用户输入并生成回复的函数
def chatbot():
print("Chatbot: 你好!我是你友好的聊天机器人。问我任何问题或输入'exit'结束对话。")
from langchain.document_loaders import GoogleDriveLoader
loader = GoogleDriveLoader(document_ids=["YOUR DOCUMENT ID's'"],
credentials_path="PATH TO credentials.json FILE")
docs = loader
# 初始化Langchain问答链
chain = load_langchain_qa()
# 用于存储聊天历史的列表
chat_history = []
while True:
user_input = input("You: ")
if user_input.lower() == "exit":
print("Chatbot: 再见!祝你有美好的一天。")
break
# 将用户的问题添加到聊天历史中
chat_history.append(user_input)
# 使用问答链处理用户的问题
response = chain.run(input_documents=chat_history, question=user_input)
# 从响应中提取答案
answer = response['answers'][0]['answer'] if response['answers'] else "我找不到你的问题的答案。"
# 将聊天机器人的回复添加到聊天历史中
chat_history.append("Chatbot: " + answer)
# 打印聊天机器人的回复
print("Chatbot:", answer)
if __name__ == "__main__":
chatbot()我们初始化了谷歌云端文档和OpenAI LLM。接下来,我们创建了一个列表来存储聊天历史,并在每次提示后更新列表。然后,我们创建了一个无限循环,当用户输入“exit”时停止。
结论
在本文中,我们看到了如何创建一个关于你的谷歌文档内容提供洞察的聊天机器人。集成Langchain、OpenAI和谷歌云端是任何领域中最有益的用例之一,无论是医疗、研究、工业还是工程。我们可以实现这项技术来自动化描述、汇总、分析和从我们的数据文件中提取洞察力,而不是阅读整个数据并分析数据以获取洞察力,这需要大量的人力和时间。
要点
- 使用Python的GoogleDriveLoader类和Google Drive API凭据,可以将Google文档获取到Python中。
- 通过将OpenAI LLM与Langchain集成,我们可以对文档进行摘要,并提出与文档相关的问题。
- 通过选择适当的链类型(如map_reduce、stuff、refine和map rerank),我们可以从多个文档中获得洞察力。
常见问题
本文中显示的媒体不归Analytics Vidhya所有,而是根据作者的自由裁量使用。