使用Amazon SageMaker扩展数千个机器学习模型的训练和推理
使用Amazon SageMaker扩展机器学习训练和推理的规模
随着机器学习(ML)在各行各业中的普及,组织机构发现需要训练和提供大量的ML模型以满足客户的各种需求。对于特定的软件即服务(SaaS)提供商来说,高效、低成本地训练和提供成千上万个模型对于在快速发展的市场中保持竞争力至关重要。
训练和提供成千上万个模型需要一个强大且可扩展的基础设施,这就是Amazon SageMaker发挥作用的地方。SageMaker是一个完全托管的平台,使开发人员和数据科学家能够快速构建、训练和部署ML模型,同时还提供使用AWS云基础设施的成本节约优势。
在本文中,我们将探讨如何使用SageMaker的功能,包括Amazon SageMaker处理、SageMaker训练作业和SageMaker多模型端点(MMEs),以一种经济高效的方式训练和提供成千上万个模型。要开始使用描述的解决方案,您可以参考GitHub上的附带笔记本。
用例:能源预测
在本文中,我们扮演一个ISV公司的角色,该公司通过跟踪客户的能源消耗并提供预测帮助客户更加可持续发展。我们公司有1000个客户希望更好地了解他们的能源使用情况,并做出关于如何减少他们的环境影响的明智决策。为此,我们使用一个合成数据集,并为每个客户基于Prophet训练一个ML模型来进行能源消耗预测。借助SageMaker,我们可以高效地训练和提供这1000个模型,为我们的客户提供准确和可操作的关于能源使用情况的见解。
生成的数据集中有三个特征:
- customer_id – 对于每个客户,这是一个整数标识符,范围从0-999。
- timestamp – 这是一个日期/时间值,表示测量能源消耗的时间。时间戳在代码中指定的起始日期和结束日期之间随机生成。
- consumption – 这是一个浮点值,表示能源消耗,以某种任意单位测量。消耗值在0-1000之间以正弦曲线的季节性随机生成。
解决方案概述
为了高效地训练和提供成千上万个ML模型,我们可以使用以下SageMaker的功能:
- SageMaker处理 – SageMaker处理是一个完全托管的数据准备服务,使您能够在输入数据上执行数据处理和模型评估任务。您可以使用SageMaker处理将原始数据转换为训练和推理所需的格式,以及运行批处理和在线模型评估。
- SageMaker训练作业 – 您可以使用SageMaker训练作业在各种算法和输入数据类型上训练模型,并指定训练所需的计算资源。
- SageMaker MMEs – 多模型端点使您能够在单个端点上托管多个模型,这使得使用单个API从多个模型中提供预测变得容易。SageMaker MMEs可以通过减少提供来自多个模型的预测所需的端点数量来节省时间和资源。MMEs支持托管CPU和GPU支持的模型。请注意,在我们的场景中,我们使用了1000个模型,但这不是服务本身的限制。
下图说明了解决方案架构。
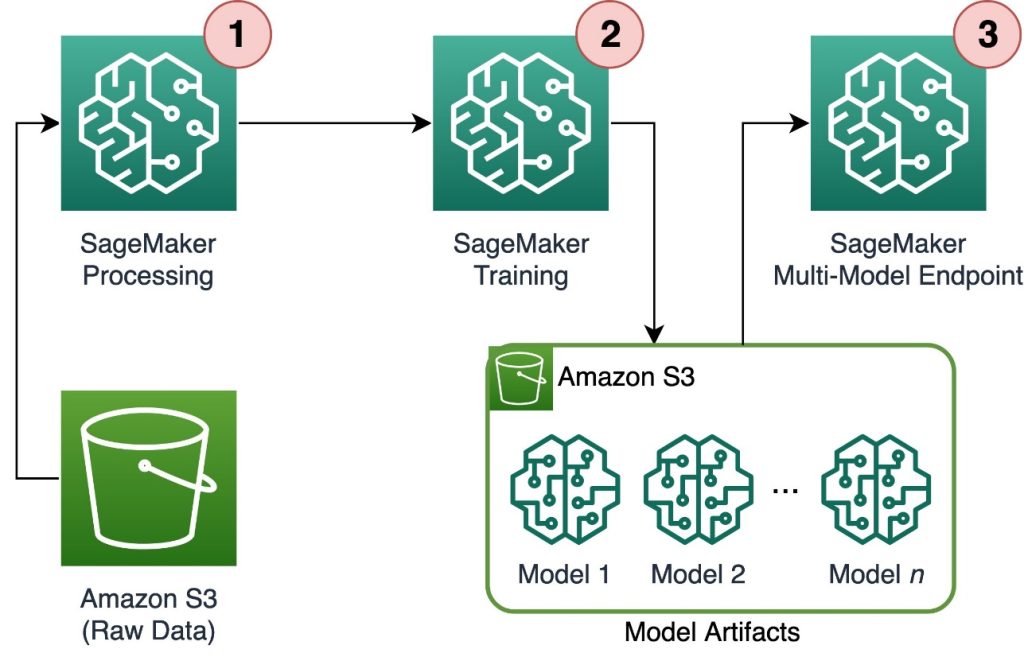
工作流包括以下步骤:
- 我们使用SageMaker处理对数据进行预处理,并为每个客户创建一个单独的CSV文件,并将其存储在Amazon简单存储服务(Amazon S3)中。
- SageMaker训练作业被配置为读取SageMaker处理作业的输出,并以轮询的方式将其分发给训练实例。请注意,这也可以通过Amazon SageMaker管道实现。
- 训练作业将模型工件存储在Amazon S3中,并直接从SageMaker MME提供。
将训练扩展到成千上万个模型
通过SageMaker Python SDK中的TrainingInput类的distribution参数,可以扩展对成千上万个模型的训练。该参数有三个选项:FullyReplicated,ShardedByS3Key和ShardedByRecord。 ShardedByS3Key选项意味着训练数据按S3对象键分片,每个训练实例接收数据的唯一子集,避免重复。在SageMaker将数据复制到训练容器之后,我们可以读取文件夹和文件结构来为每个客户文件训练唯一的模型。以下是一个示例代码片段:
# 假设训练数据已经存储在 S3 存储桶中,传入父文件夹
s3_input_train = sagemaker.inputs.TrainingInput(
s3_data='s3://my-bucket/customer_data',
distribution='ShardedByS3Key'
)
# 创建 SageMaker 估算器并设置训练输入
estimator = sagemaker.estimator.Estimator(...)
estimator.fit(inputs=s3_input_train)每个 SageMaker 训练作业都会在训练容器的 /opt/ml/model 文件夹中保存模型,并在训练作业完成后将其归档为 model.tar.gz 文件,然后将其上传到 Amazon S3。高级用户还可以使用 SageMaker Pipelines 自动化此过程。当通过同一训练作业存储多个模型时,SageMaker 会创建一个包含所有训练模型的单个 model.tar.gz 文件。这意味着为了提供模型服务,我们需要先解压缩存档。为了避免这种情况,我们使用检查点来保存每个模型的状态。SageMaker 提供了将训练作业期间创建的检查点复制到 Amazon S3 的功能。在这里,检查点需要保存在预先指定的位置,默认位置为 /opt/ml/checkpoints。这些检查点可以用于稍后恢复训练,或作为部署在端点上的模型。有关 SageMaker 训练平台如何在 AWS 云存储和 SageMaker 训练作业之间管理训练数据集、模型工件、检查点和输出的存储路径的高级摘要,请参阅 Amazon SageMaker 训练存储文件夹,用于训练数据集、检查点、模型工件和输出。
以下代码在包含训练逻辑的 train.py 脚本中使用了一个虚构的 model.save() 函数:
import tarfile
import boto3
import os
[ ... 解析参数 ... ]
for customer in os.list_dir(args.input_path):
# 在训练作业中本地读取数据
df = pd.read_csv(os.path.join(args.input_path, customer, 'data.csv'))
# 定义并训练模型
model = MyModel()
model.fit(df)
# 将模型保存到输出目录
with open(os.path.join(output_dir, 'model.json'), 'w') as fout:
fout.write(model_to_json(model))
# 创建包含模型和训练脚本的 model.tar.gz 存档
with tarfile.open(os.path.join(output_dir, '{customer}.tar.gz'), "w:gz") as tar:
tar.add(os.path.join(output_dir, 'model.json'), "model.json")
tar.add(os.path.join(args.code_dir, "training.py"), "training.py")使用 SageMaker MME 扩展推理至数千个模型
SageMaker MME 允许您同时服务多个模型,方法是创建一个包含要服务的所有模型列表的端点配置,然后使用该端点配置创建一个端点。每当您添加一个新模型时,无需重新部署端点,因为端点将自动服务于指定 S3 路径中存储的所有模型。这是通过 Multi Model Server (MMS) 实现的,它是一个用于提供 ML 模型的开源框架,可以在容器中安装以提供满足新 MME 容器 API 要求的前端。此外,您还可以使用其他模型服务器,包括 TorchServe 和 Triton。通过 SageMaker 推理工具包,可以将 MMS 安装在自定义容器中。有关如何配置 Dockerfile 以包含 MMS 并将其用于提供模型的详细信息,请参阅构建适用于 SageMaker 多模型端点的自定义容器。
以下代码片段展示了如何使用 SageMaker Python SDK 创建 MME:
from sagemaker.multidatamodel import MultiDataModel
# 创建 MultiDataModel 定义
multimodel = MultiDataModel(
name='customer-models',
model_data_prefix=f's3://{bucket}/scaling-thousand-models/models',
model=your_model,
)
# 部署实时端点
predictor = multimodel.deploy(
initial_instance_count=1,
instance_type='ml.c5.xlarge',
)当 MME 处于运行状态时,我们可以调用它生成预测。调用可以在任何 AWS SDK 中进行,也可以使用 SageMaker Python SDK,如下代码片段所示:
predictor.predict(
data='{"period": 7}', # 负载,此处为 JSON
target_model='{customer}.tar.gz' # 目标模型的名称
)在调用模型时,模型首先从Amazon S3加载到实例上,这可能会导致调用新模型时的冷启动。经常使用的模型会被缓存在内存和磁盘上,以提供低延迟的推断。
结论
SageMaker是一个强大且经济高效的平台,可用于训练和服务成千上万个机器学习模型。其功能包括SageMaker处理、训练作业和MME,使组织能够高效地训练和服务成千上万个模型,同时也从使用AWS云基础设施的节省成本优势中受益。要了解如何使用SageMaker进行训练和服务成千上万个模型的更多信息,请参阅处理数据,在Amazon SageMaker上训练模型和在一个端点后面的一个容器中托管多个模型。






