基于Transformer的编码器-解码器模型
Transformer模型是一种基于自注意力机制的编码器-解码器架构它在自然语言处理和机器翻译等任务中取得了巨大成功
![]()
!pip install transformers==4.2.1
!pip install sentencepiece==0.1.95基于Transformer的编码器-解码器模型是由Vaswani等人在著名的Attention is all you need论文中引入的,如今已成为自然语言处理(NLP)中事实上的标准编码器-解码器架构。
最近,关于基于Transformer的编码器-解码器模型的不同预训练目标进行了大量研究,例如T5、Bart、Pegasus、ProphetNet、Marge等等,但模型架构基本保持不变。
本博文的目标是详细解释基于Transformer的编码器-解码器架构如何对序列到序列问题进行建模。我们将重点介绍架构定义的数学模型以及如何在推断中使用该模型。同时,我们还将对NLP中的序列到序列模型进行一些背景介绍,并将基于Transformer的编码器-解码器架构分解为其编码器和解码器部分。我们提供了许多插图,并建立了基于Transformer的编码器-解码器模型理论与实际应用在🤗Transformers推断中的联系。请注意,本博文不解释如何训练此类模型-这将是未来博文的主题。
- 使用Transformers和Ray Tune进行超参数搜索
- 我们如何将Transformer推理加速100倍,以满足🤗 API客户的需求
- Hugging Face在PyTorch / XLA TPUs上的应用
基于Transformer的编码器-解码器模型是多年来在表示学习和模型架构上的研究成果。本笔记本提供了神经编码器-解码器模型历史的简要概述。为了更多背景知识,建议读者阅读Sebastion Ruder的这篇精彩博文。此外,建议具备对自注意力架构的基本理解。Jay Alammar的以下博文是关于原始Transformer模型的很好的复习材料。
在撰写本笔记本时,🤗Transformers包括T5、Bart、MarianMT和Pegasus等编码器-解码器模型,这些模型在文档中有摘要。
本笔记本分为四个部分:
- 背景 – 简要介绍神经编码器-解码器模型的历史,重点放在基于RNN的模型上。
- 编码器-解码器 – 介绍基于Transformer的编码器-解码器模型,并解释该模型如何用于推断。
- 编码器 – 详细解释模型的编码器部分。
- 解码器 – 详细解释模型的解码器部分。
每个部分都建立在前一个部分的基础上,但也可以单独阅读。
背景
自然语言生成(NLG)任务是自然语言处理(NLP)的一个子领域,最好以序列到序列问题来表达。这样的任务可以定义为找到一个将输入词序列映射到目标词序列的模型。一些经典的例子是摘要和翻译。在接下来的内容中,我们假设每个词都被编码为一个向量表示。因此,n个输入词可以表示为一个n个输入向量的序列:
X1:n = {x1, …, xn}。
因此,序列到序列问题可以通过找到从输入序列X1:n到目标向量序列Y1:m的映射f来解决,其中目标向量的数量m未知,并且取决于输入序列:
- f : X1:n → Y1:m。
- X1:n → Y1:m。
Sutskever等人(2014)指出,深度神经网络(DNN)“尽管具有灵活性和强大性,但只能定义输入和目标可以用固定维度向量进行合理编码的映射。” 1 {}^1 1
使用DNN模型2 {}^2 2来解决序列到序列的问题,因此目标向量的数量m m m必须事先知道,并且必须与输入X 1 : n \mathbf{X}_{1:n} X 1 : n 无关。这是不够优化的,因为在NLG任务中,目标词的数量通常取决于输入X 1 : n \mathbf{X}_{1:n} X 1 : n ,而不仅仅取决于输入长度n n n。例如,一篇1000个单词的文章可以根据其内容被总结为200个单词或100个单词。
2014年,Cho等人和Sutskever等人提出使用基于循环神经网络(RNNs)的编码器-解码器模型来处理序列到序列任务。与DNN不同,RNN能够对可变数量的目标向量进行建模。让我们深入了解一下基于RNN的编码器-解码器模型的工作原理。
在推理过程中,编码器RNN通过连续更新其隐藏状态3 {}^3 3来对输入序列X 1 : n \mathbf{X}_{1:n} X 1 : n 进行编码。在处理完最后一个输入向量x n \mathbf{x}_n x n 后,编码器的隐藏状态定义了输入编码c \mathbf{c} c。因此,编码器定义了映射关系:
f θ e n c : X 1 : n → c . f_{\theta_{enc}}: \mathbf{X}_{1:n} \to \mathbf{c}. f θ e n c : X 1 : n → c .
然后,解码器的隐藏状态使用输入编码进行初始化,并且在推理过程中,解码器RNN用于自回归生成目标序列。让我们解释一下。
数学上,解码器定义了给定隐藏状态c \mathbf{c} c的目标序列Y 1 : m \mathbf{Y}_{1:m} Y 1 : m 的概率分布:
p θ d e c ( Y 1 : m ∣ c ) . p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c}). p θ d e c ( Y 1 : m ∣ c ) .
根据贝叶斯定理,可以将该分布分解为单个目标向量的条件分布,如下所示:
p θ d e c ( Y 1 : m ∣ c ) = ∏ i = 1 m p θ dec ( y i ∣ Y 0 : i − 1 , c ) . p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c}) = \prod_{i=1}^{m} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}). p θ d e c ( Y 1 : m ∣ c ) = i = 1 ∏ m p θ dec ( y i ∣ Y 0 : i − 1 , c ) .
因此,如果架构能够对下一个目标向量的条件分布进行建模,给定所有先前的目标向量:
p θ dec ( y i ∣ Y 0 : i − 1 , c ) , ∀ i ∈ { 1 , … , m } , p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}), \forall i \in \{1, \ldots, m\}, p θ dec ( y i ∣ Y 0 : i − 1 , c ) , ∀ i ∈ { 1 , … , m } ,
那么它可以通过简单地将所有条件概率相乘来建模给定隐藏状态c \mathbf{c} c的任何目标向量序列的分布。
- 那么基于RNN的解码器架构如何建模p θ dec ( y i ∣ Y 0
- i − 1 , c ) p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}) p θ dec ( y i ∣ Y 0 : i − 1 , c ) ?
在计算上,该模型按顺序将先前的内部隐藏状态 c i − 1 \mathbf{c}_{i-1} c i − 1 和先前的目标向量 y i − 1 \mathbf{y}_{i-1} y i − 1 映射到当前的内部隐藏状态 c i \mathbf{c}_i c i 和一个逻辑向量 l i \mathbf{l}_i l i (在下面的深红色中显示):
f θ dec ( y i − 1 , c i − 1 ) → l i , c i . f_{\theta_{\text{dec}}}(\mathbf{y}_{i-1}, \mathbf{c}_{i-1}) \to \mathbf{l}_i, \mathbf{c}_i. f θ dec ( y i − 1 , c i − 1 ) → l i , c i . 因此将 c 0 \mathbf{c}_0 c 0 定义为 c \mathbf{c} c 是基于 RNN 的编码器的输出隐藏状态。随后,使用 softmax 操作将逻辑向量 l i \mathbf{l}_i l i 转换为下一个目标向量的条件概率分布:
p ( y i ∣ l i ) = Softmax ( l i ) ,其中 l i = f θ dec ( y i − 1 , c prev ) . p(\mathbf{y}_i | \mathbf{l}_i) = \textbf{Softmax}(\mathbf{l}_i), \text{ with } \mathbf{l}_i = f_{\theta_{\text{dec}}}(\mathbf{y}_{i-1}, \mathbf{c}_{\text{prev}}). p ( y i ∣ l i ) = Softmax ( l i ) ,其中 l i = f θ dec ( y i − 1 , c prev ) .
有关逻辑向量和结果概率分布的更多细节,请参见脚注4 {}^4 4 。从上述方程可以看出,当前目标向量 y i \mathbf{y}_i y i 的分布直接取决于先前的目标向量 y i − 1 \mathbf{y}_{i-1} y i − 1 和先前的隐藏状态 c i − 1 \mathbf{c}_{i-1} c i − 1 。因为先前的隐藏状态 c i − 1 \mathbf{c}_{i-1} c i − 1 依赖于所有先前的目标向量 y 0 , … , y i − 2 \mathbf{y}_0, \ldots, \mathbf{y}_{i-2} y 0 , … , y i − 2 ,所以可以说 RNN-based 解码器隐式(例如间接)地建模了条件分布 p θ dec ( y i ∣ Y 0 : i − 1 , c ) p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}) p θ dec ( y i ∣ Y 0 : i − 1 , c ) 。
目标向量序列 Y 1 : m \mathbf{Y}_{1:m} Y 1 : m 的可能空间非常大,因此在推断过程中,必须依靠高效采样从 p θ d e c ( Y 1 : m ∣ c ) p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c}) p θ d e c ( Y 1 : m ∣ c ) 中获得高概率目标向量序列的解码方法5 {}^5 5 。
在推断过程中,通过这样的解码方法,可以从 p θ dec ( y i ∣ Y 0 : i − 1 , c ) p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}) p θ dec ( y i ∣ Y 0 : i − 1 , c ) 中采样下一个输入向量 y i \mathbf{y}_i y i ,然后将其附加到输入序列中,以便解码器 RNN 可以模拟 p θ dec ( y i + 1 ∣ Y 0 : i , c ) p_{\theta_{\text{dec}}}(\mathbf{y}_{i+1} | \mathbf{Y}_{0: i}, \mathbf{c}) p θ dec ( y i + 1 ∣ Y 0 : i , c ) 以自回归的方式采样下一个输入向量 y i + 1 \mathbf{y}_{i+1} y i + 1 ,以此类推。
RNN-based编码器-解码器模型的一个重要特征是特殊向量的定义,例如EOS(结束)向量和BOS(开始)向量。EOS向量通常代表最后的输入向量x_n,用于“提示”编码器输入序列已经结束,并且定义目标序列的结束。一旦EOS从logit向量中被采样,生成就完成了。BOS向量代表输入向量y_0,在解码器RNN的第一个解码步骤中被提供。为了输出第一个logit向量l_1,需要一个输入,由于在第一步尚未生成输入,所以将特殊的BOS输入向量提供给解码器RNN。好的 – 相当复杂!让我们通过一个例子来说明和演示。
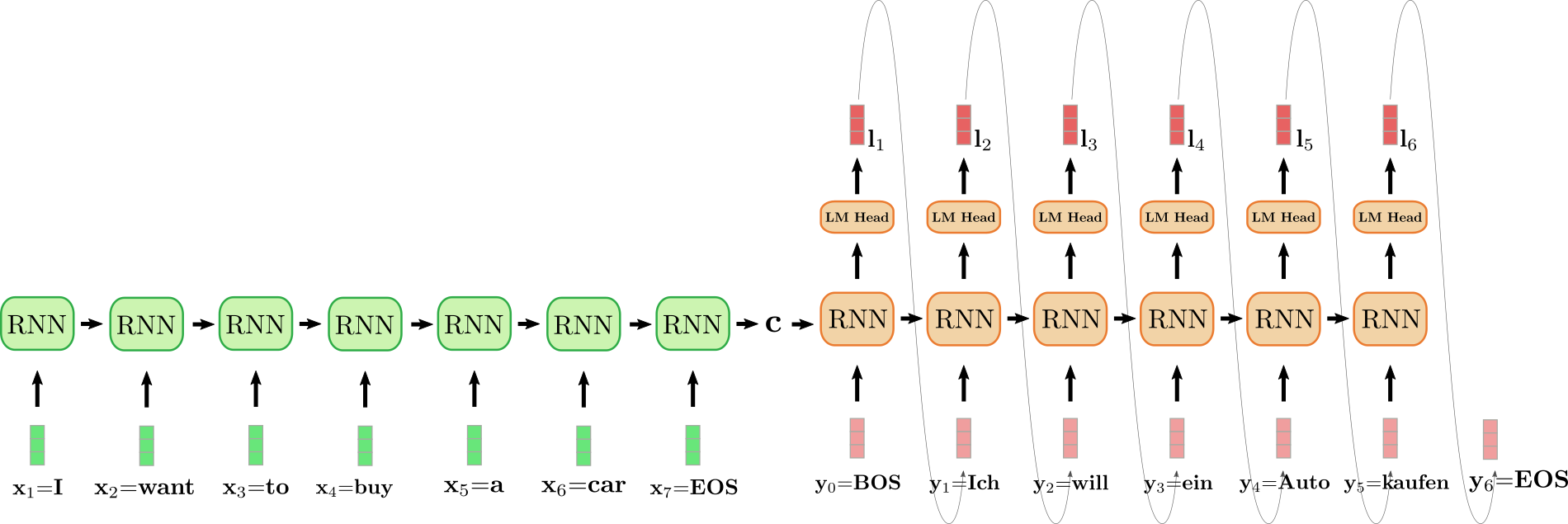
展开的RNN编码器以绿色表示,展开的RNN解码器以红色表示。
英语句子”I want to buy a car”,用x_1 = I,x_2 = want,x_3 = to,x_4 = buy,x_5 = a,x_6 = car和x_7 = EOS表示,被翻译成德语:”Ich will ein Auto kaufen”,定义为y_0 = BOS,y_1 = Ich,y_2 = will,y_3 = ein,y_4 = Auto,y_5 = kaufen和y_6 = EOS。首先,输入向量x_1 = I由编码器RNN处理,并更新其隐藏状态。注意,因为我们只对最终编码器的隐藏状态c感兴趣,所以我们可以忽略RNN编码器的目标向量。然后,编码器RNN以相同的方式处理输入句子的其余部分want,to,buy,a,car,EOS,每一步更新其隐藏状态,直到达到向量x_7 = EOS的6{}^6{}^6。在上面的插图中,连接展开的编码器RNN的水平箭头表示隐藏状态的顺序更新。编码器RNN的最终隐藏状态c完全定义了输入序列的编码,并用作解码器RNN的初始隐藏状态。可以将其视为将解码器RNN条件化于编码输入。
为了生成第一个目标向量,解码器被提供BOS向量,如上述设计中的y_0所示。然后,通过LM Head前馈层,将RNN的目标向量进一步映射到logit向量l_1,以定义第一个目标向量的条件分布,如上所述:
pθdec(y | BOS, c).
单词Ich是通过采样得到的(由灰色箭头表示,连接l1和y1),因此第二个目标向量可以采样得到:
will ∼ pθdec(y | BOS, Ich, c).
依此类推,直到在第i = 6步,从l6中采样得到EOS向量,解码过程结束。得到的目标序列为Y1:6 = {y1, …, y6},在我们的例子中为”Ich will ein Auto kaufen”。
总之,基于RNN的编码器-解码器模型,由fθenc和pθdec表示,通过因子分解定义了分布p(Y1:m | X1:n):
pθenc, θdec(Y1:m | X1:n) = ∏i=1m pθenc, θdec(yi | Y0:i-1, X1:n) = ∏i=1m pθdec(yi | Y0:i-1, c),其中c = fθenc(X)。
在推断过程中,可以使用高效的解码方法自回归地生成目标序列Y1:m。
基于RNN的编码器-解码器模型在自然语言生成(NLG)领域引起了轰动。2016年,Google宣布将完全用一个基于RNN的编码器-解码器模型来替代其大量特征工程的翻译服务(见此处)。
然而,基于RNN的编码器-解码器模型存在两个问题。首先,RNN遭受梯度消失问题,很难捕捉到长距离依赖关系,参见Hochreiter等人(2001)。其次,RNN的固有循环架构在编码时阻碍了有效的并行化处理,参见Vaswani等人(2017)。
1 {}^1 1 论文中的原始引用是“尽管深度神经网络具有灵活性和强大性,但只能应用于能够用固定维度的向量合理编码的问题”,这里稍作调整。
2 {}^2 2 同样的道理也适用于卷积神经网络(CNN)。虽然变长的输入序列可以输入到CNN中,但目标的维度始终取决于输入的维度或固定为特定值。
3 {}^3 3 在第一步中,隐藏状态被初始化为一个零向量,并与第一个输入向量 x 1 \mathbf{x}_1 x 1 一起输入到RNN中。
4 {}^4 4 神经网络可以定义一个关于所有单词的概率分布,即 p ( y ∣ c , Y 0 : i − 1 ) p(\mathbf{y} | \mathbf{c}, \mathbf{Y}_{0: i-1}) p ( y ∣ c , Y 0 : i − 1 ) 如下所示。首先,网络将输入 c , Y 0 : i − 1 \mathbf{c}, \mathbf{Y}_{0: i-1} c , Y 0 : i − 1 映射到嵌入向量表示 y ′ \mathbf{y’} y ′ ,它对应于RNN目标向量。然后,嵌入向量表示 y ′ \mathbf{y’} y ′ 被传递到“语言模型头”层,这意味着它与词嵌入矩阵相乘,即 Y vocab \mathbf{Y}^{\text{vocab}} Y vocab ,以计算 y ′ \mathbf{y’} y ′ 与每个编码向量 y ∈ Y vocab \mathbf{y} \in \mathbf{Y}^{\text{vocab}} y ∈ Y vocab 之间的得分。得到的向量称为对数向量 l = Y vocab y ′ \mathbf{l} = \mathbf{Y}^{\text{vocab}} \mathbf{y’} l = Y vocab y ′ ,可以通过应用 softmax 操作将其映射到所有单词的概率分布上:p ( y ∣ c ) = Softmax ( Y vocab y ′ ) = Softmax ( l ) p(\mathbf{y} | \mathbf{c}) = \text{Softmax}(\mathbf{Y}^{\text{vocab}} \mathbf{y’}) = \text{Softmax}(\mathbf{l}) p ( y ∣ c ) = Softmax ( Y vocab y ′ ) = Softmax ( l ) 。
5 {}^5 5 波束搜索解码就是这种解码方法的一个例子。其他解码方法超出了本笔记的范围。建议读者参考这篇关于解码方法的交互式笔记。
6 {}^6 6 Sutskever等人(2014)颠倒了输入的顺序,因此在上述示例中,输入向量将对应于 x 1 = car \mathbf{x}_1 = \text{car} x 1 = car ,x 2 = a \mathbf{x}_2 = \text{a} x 2 = a ,x 3 = buy \mathbf{x}_3 = \text{buy} x 3 = buy ,x 4 = to \mathbf{x}_4 = \text{to} x 4 = to ,x 5 = want \mathbf{x}_5 = \text{want} x 5 = want ,x 6 = I \mathbf{x}_6 = \text{I} x 6 = I 和 x 7 = EOS \mathbf{x}_7 = \text{EOS} x 7 = EOS 。其动机是为了允许相应的词对之间有更短的连接,例如 x 6 = I \mathbf{x}_6 = \text{I} x 6 = I 和 y 1 = Ich \mathbf{y}_1 = \text{Ich} y 1 = Ich 。研究小组强调,输入序列的颠倒是他们的模型在机器翻译上表现提高的关键原因。
编码器-解码器
2017年,Vaswani等人引入了Transformer模型,从而诞生了基于Transformer的编码器-解码器模型。
类似于基于RNN的编码器-解码器模型,基于transformer的编码器-解码器模型由编码器和解码器组成,两者都是残差注意力块的堆叠。基于transformer的编码器-解码器模型的关键创新在于这些残差注意力块可以处理变长输入序列X1:n而不需要循环结构。不依赖于循环结构使得基于transformer的编码器-解码器模型可以高度可并行化,这使得该模型在现代硬件上的计算效率比基于RNN的编码器-解码器模型高出数个数量级。
作为提醒,为了解决序列到序列的问题,我们需要找到一个将输入序列X1:n映射到变长输出序列Y1:m的映射。让我们看看如何使用基于transformer的编码器-解码器模型来找到这样的映射。
类似于基于RNN的编码器-解码器模型,基于transformer的编码器-解码器模型定义了给定输入序列X1:n条件下目标向量序列Y1:m的条件分布:
pθenc, θdec(Y1:m|X1:n)。
基于transformer的编码器部分将输入序列X1:n编码为一系列隐藏状态X̄1:n,从而定义了映射:
fθenc: X1:n → X̄1:n。
然后,基于transformer的解码器部分建模了在给定编码隐藏状态序列X̄1:n的情况下,目标向量序列Y1:n的条件概率分布:
pθdec(Y1:n|X̄1:n)。
根据贝叶斯定理,可以将这个分布分解为给定编码隐藏状态X̄1:n和所有先前目标向量Y0:i-1的目标向量yi的条件概率分布的乘积:
pθdec(Y1:n|X̄1:n) = ∏i=1n pθdec(yi|Y0:i-1, X̄1:n)。
基于Transformer的解码器将编码隐藏状态序列 X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n 和所有之前的目标向量 Y 0 : i − 1 \mathbf{Y}_{0:i-1} Y 0 : i − 1 映射到逻辑向量 l i \mathbf{l}_i l i 。然后,逻辑向量 l i \mathbf{l}_i l i 通过softmax操作处理,定义了条件分布 p θ dec ( y i ∣ Y 0 : i − 1 , X ‾ 1 : n ) p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}) p θ dec ( y i ∣ Y 0 : i − 1 , X 1 : n ) ,就像RNN-based解码器一样。然而,与基于RNN的解码器不同,目标向量 y i \mathbf{y}_i y i 的分布明确地(或直接地)取决于所有之前的目标向量 y 0 , … , y i − 1 \mathbf{y}_0, \ldots, \mathbf{y}_{i-1} y 0 , … , y i − 1 ,我们将在后面更详细地看到。第0个目标向量 y 0 \mathbf{y}_0 y 0 由特殊的“句子开始”BOS \text{BOS} BOS向量表示。
定义了条件分布 p θ dec ( y i ∣ Y 0 : i − 1 , X ‾ 1 : n ) p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}) p θ dec ( y i ∣ Y 0 : i − 1 , X 1 : n ) 之后,我们可以自回归地生成输出,从而定义了将输入序列 X 1 : n \mathbf{X}_{1:n} X 1 : n 映射到输出序列 Y 1 : m \mathbf{Y}_{1:m} Y 1 : m 的过程。
让我们可视化基于Transformer的编码器-解码器模型的自回归生成的完整过程。
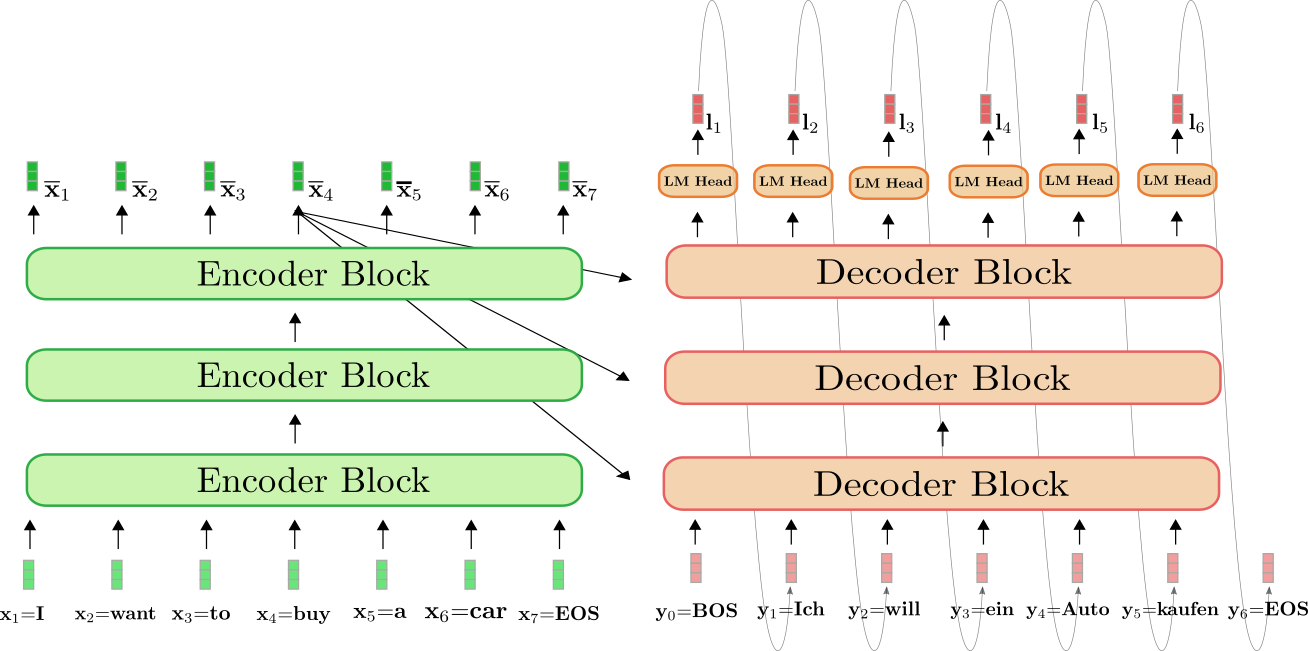
基于Transformer的编码器以绿色表示,基于Transformer的解码器以红色表示。与前一部分一样,我们展示了英文句子“I want to buy a car”,用 x 1 = I \mathbf{x}_1 = \text{I} x 1 = I , x 2 = want \mathbf{x}_2 = \text{want} x 2 = want , x 3 = to \mathbf{x}_3 = \text{to} x 3 = to , x 4 = buy \mathbf{x}_4 = \text{buy} x 4 = buy , x 5 = a \mathbf{x}_5 = \text{a} x 5 = a , x 6 = car \mathbf{x}_6 = \text{car} x 6 = car , 和 x 7 = EOS \mathbf{x}_7 = \text{EOS} x 7 = EOS 表示,被翻译成德语:“Ich will ein Auto kaufen”,定义为 y 0 = BOS \mathbf{y}_0 = \text{BOS} y 0 = BOS , y 1 = Ich \mathbf{y}_1 = \text{Ich} y 1 = Ich , y 2 = will \mathbf{y}_2 = \text{will} y 2 = will , y 3 = ein \mathbf{y}_3 = \text{ein} y 3 = ein , y 4 = Auto , y 5 = kaufen \mathbf{y}_4 = \text{Auto}, \mathbf{y}_5 = \text{kaufen} y 4 = Auto , y 5 = kaufen , 和 y 6 = EOS \mathbf{y}_6=\text{EOS} y 6 = EOS 。
首先,编码器处理完整的输入序列 X 1 : 7 \mathbf{X}_{1:7} X 1 : 7 = “我想买一辆车”(用浅绿色向量表示),得到上下文化的编码序列 X ‾ 1 : 7 \mathbf{\overline{X}}_{1:7} X 1 : 7 。例如,x ‾ 4 \mathbf{\overline{x}}_4 x 4 定义了一个编码,不仅依赖于输入 x 4 \mathbf{x}_4 x 4 = “买”,还依赖于所有其他词 “我”,”想”,”买”,”一辆”,”车” 和 “EOS”,即上下文。
接下来,将输入编码 X ‾ 1 : 7 \mathbf{\overline{X}}_{1:7} X 1 : 7 与 BOS 向量 y 0 \mathbf{y}_0 y 0 一起输入解码器。解码器处理输入 X ‾ 1 : 7 \mathbf{\overline{X}}_{1:7} X 1 : 7 和 y 0 \mathbf{y}_0 y 0 ,得到第一个逻辑值 l 1 \mathbf{l}_1 l 1 (用深红色表示),用于定义第一个目标向量 y 1 \mathbf{y}_1 y 1 的条件分布:
p θ e n c , d e c ( y ∣ y 0 , X 1 : 7 ) = p θ e n c , d e c ( y ∣ BOS , 我 想 买 一辆 车 EOS ) = p θ d e c ( y ∣ BOS , X ‾ 1 : 7 ) . p_{\theta_{enc, dec}}(\mathbf{y} | \mathbf{y}_0, \mathbf{X}_{1:7}) = p_{\theta_{enc, dec}}(\mathbf{y} | \text{BOS}, \text{我想买一辆车EOS}) = p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \mathbf{\overline{X}}_{1:7}). p θ e n c , d e c ( y ∣ y 0 , X 1 : 7 ) = p θ e n c , d e c ( y ∣ BOS , 我 想 买 一辆 车 EOS ) = p θ d e c ( y ∣ BOS , X 1 : 7 ) .
接下来,从分布中抽样得到第一个目标向量 y 1 \mathbf{y}_1 y 1 = “Ich”。现在,解码器再次处理 y 0 \mathbf{y}_0 y 0 = “BOS” 和 y 1 \mathbf{y}_1 y 1 = “Ich”,定义第二个目标向量 y 2 \mathbf{y}_2 y 2 的条件分布:
p θ d e c ( y ∣ BOS Ich , X ‾ 1 : 7 ) . p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich}, \mathbf{\overline{X}}_{1:7}). p θ d e c ( y ∣ BOS Ich , X 1 : 7 ) .
我们可以再次进行采样,得到目标向量 y 2 \mathbf{y}_2 y 2 = “will”。我们以自回归的方式继续,直到在第6步中从条件分布中抽样得到 EOS 向量:
EOS ∼ p θ d e c ( y ∣ BOS Ich will ein Auto kaufen , X ‾ 1 : 7 ) . EOS \sim p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}). EOS ∼ p θ d e c ( y ∣ BOS Ich will ein Auto kaufen , X 1 : 7 ) .
以自回归的方式进行。
需要理解的是,在第一次前向传递中,编码器仅用于将 X 1 : n \mathbf{X}_{1:n} X 1 : n 映射到 X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n 。从第二次前向传递开始,解码器可以直接使用先前计算的编码 X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n 。为了清晰起见,让我们对上述示例的第一次和第二次前向传递进行说明。
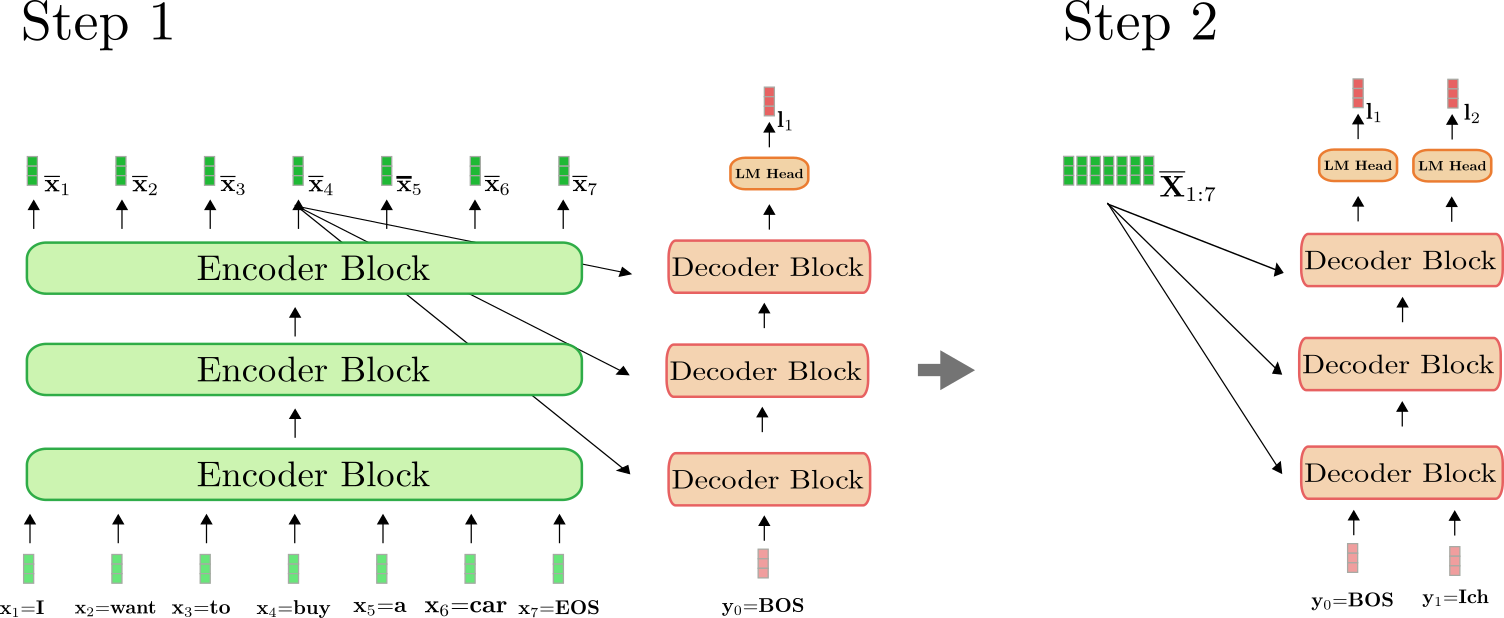
可以看到,只有在步骤 i = 1 i=1 i = 1 时,需要将 “I want to buy a car EOS” 编码为 X ‾ 1 : 7 \mathbf{\overline{X}}_{1:7} X 1 : 7 。在步骤 i = 2 i=2 i = 2 中,”I want to buy a car EOS” 的上下文编码仅被解码器重用。
在 🤗Transformers 中,当调用 .generate() 方法时,这种自回归生成在内部完成。让我们使用其中一个翻译模型来看看它的实际效果。
from transformers import MarianMTModel, MarianTokenizer
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
# 创建编码输入向量的 id
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# 翻译示例
output_ids = model.generate(input_ids)[0]
# 解码和打印
print(tokenizer.decode(output_ids))输出:
<pad> Ich will ein Auto kaufen调用 .generate() 执行许多操作。首先,它将 input_ids 传递给编码器。其次,它传递一个预定义的标记,这在 MarianMTModel 的情况下是 <pad> \text{<pad>} <pad> 符号,以及编码的 input_ids 到解码器。第三,它应用波束搜索解码机制,以自回归地取样最后一个解码器输出 1 {}^1 1 的下一个输出单词。有关波束搜索解码工作原理的更多细节,建议阅读这篇博文。
在附录中,我们包含了一个代码片段,展示了如何从头开始实现一个简单的生成方法。为了全面理解自回归生成在内部是如何工作的,强烈建议阅读附录。
总结一下:
- 基于 Transformer 的编码器将输入序列 X 1 : n \mathbf{X}_{1:n} X 1 : n 定义为上下文化的编码序列 X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n 。
- 基于 Transformer 的解码器将条件分布 p θ dec ( y i ∣ Y 0 : i − 1 , X ‾ 1 : n ) p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}) p θ dec ( y i ∣ Y 0 : i − 1 , X 1 : n ) 定义为。
- 在给定适当的解码机制的情况下,输出序列 Y 1 : m \mathbf{Y}_{1:m} Y 1 : m 可以从 p θ dec ( y i ∣ Y 0 : i − 1 , X ‾ 1 : n ) , ∀ i ∈ { 1 , … , m } p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}), \forall i \in \{1, \ldots, m\} p θ dec ( y i ∣ Y 0 : i − 1 , X 1 : n ) , ∀ i ∈ { 1 , … , m } 自回归地采样。
很好,现在我们已经对基于Transformer的编码器-解码器模型的工作原理有了一个总体的概述,我们可以更深入地了解模型的编码器和解码器部分。具体来说,我们将看到编码器如何利用自注意力层生成一系列上下文相关的向量编码,以及自注意力层如何实现高效的并行计算。然后,我们将详细解释解码器模型中的自注意力层的工作原理,以及解码器如何通过交叉注意力层对编码器的输出进行条件化,从而定义条件分布pθdec(yi∣Y0:i−1,X‾1:n)。在此过程中,我们将清楚地看到基于Transformer的编码器-解码器模型如何解决基于RNN的编码器-解码器模型中的长程依赖问题。
1 {}^1 1 在"Helsinki-NLP/opus-mt-en-de"的情况下,可以在这里访问解码参数,我们可以看到模型应用了具有num_beams=6的beam搜索算法。
编码器
如前一节所述,基于Transformer的编码器将输入序列映射为上下文化的编码序列:
fθenc:X1:n→X‾1:n。f_{\theta_{\text{enc}}}: \mathbf{X}_{1:n} \to \mathbf{\overline{X}}_{1:n}。fθenc:X1:n→X1:n。
更详细地看一下架构,基于Transformer的编码器是一堆残差编码器块。每个编码器块由一个双向自注意力层和两个前馈层组成。为简单起见,在本笔记本中我们忽略了归一化层。此外,我们不会进一步讨论两个前馈层的作用,只是将其看作每个编码器块中所需的最终向量到向量映射1 {}^1 1 。双向自注意力层将每个输入向量x′j,∀j∈{1,…,n}与所有输入向量x′1,…,x′n关联起来,从而将输入向量x′j转换为其自身的更“精炼”的上下文表示,定义为x′′j。因此,第一个编码器块将输入序列X1:n的每个输入向量(在下面的浅绿色中显示)从上下文无关的向量表示转换为上下文相关的向量表示,后续的编码器块进一步细化这个上下文表示,直到最后一个编码器块输出最终的上下文编码X‾1:n(在下面的深绿色中显示)。
让我们看看编码器如何将输入序列“I want to buy a car EOS”处理成上下文化的编码序列。与基于RNN的编码器类似,基于Transformer的编码器也将一个特殊的“end-of-sequence”输入向量添加到输入序列中,以提示模型输入向量序列已经结束2 {}^2 2 。
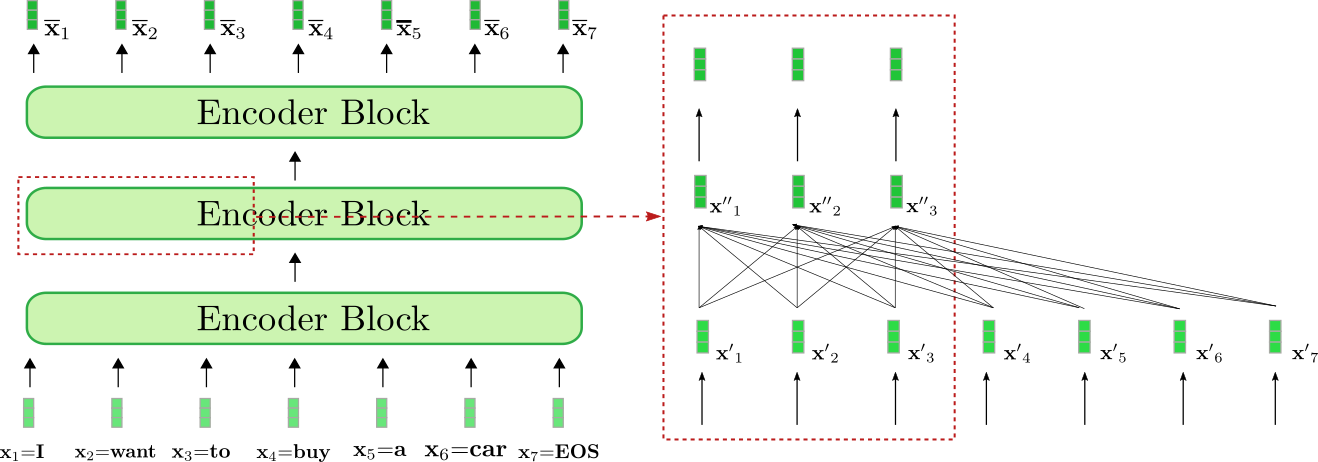
我们示例的基于Transformer的编码器由三个编码器块组成,其中第二个编码器块在右侧的红色框中对前三个输入向量x1,x2和x3进行了更详细的展示。双向自注意力机制通过红色框下部的全连接图表示,两个前馈层显示在红色框的上部。如前所述,我们只关注双向自注意力机制。
从中可以看出,自注意力层的每个输出向量 x ′ ′ i ,∀ i ∈ { 1 , … , 7 } \mathbf{x”}_i, \forall i \in \{1, \ldots, 7\} x ′ ′ i , ∀ i ∈ { 1 , … , 7 } 直接依赖于所有输入向量 x ′ 1 , … , x ′ 7 \mathbf{x’}_1, \ldots, \mathbf{x’}_7 x ′ 1 , … , x ′ 7 。这意味着,例如单词 “want” 的输入向量表示,即 x ′ 2 \mathbf{x’}_2 x ′ 2 ,与单词 “buy” 的输入向量表示,即 x ′ 4 \mathbf{x’}_4 x ′ 4 ,以及单词 “I” 的输入向量表示,即 x ′ 1 \mathbf{x’}_1 x ′ 1 ,存在直接关系。因此,”want” 的输出向量表示,即 x ′ ′ 2 \mathbf{x”}_2 x ′ ′ 2 ,代表了单词 “want” 的更精细的上下文表示。
让我们深入了解双向自注意力是如何工作的。输入序列 X ′ 1 : n \mathbf{X’}_{1:n} X ′ 1 : n 的每个输入向量 x ′ i \mathbf{x’}_i x ′ i ,通过三个可训练的权重矩阵 W q , W v , W k \mathbf{W}_q, \mathbf{W}_v, \mathbf{W}_k W q , W v , W k (如下图所示的橙色、蓝色和紫色)被投影为一个键向量 k i \mathbf{k}_i k i ,一个值向量 v i \mathbf{v}_i v i ,一个查询向量 q i \mathbf{q}_i q i :
q i = W q x ′ i , \mathbf{q}_i = \mathbf{W}_q \mathbf{x’}_i, q i = W q x ′ i , v i = W v x ′ i , \mathbf{v}_i = \mathbf{W}_v \mathbf{x’}_i, v i = W v x ′ i , k i = W k x ′ i , \mathbf{k}_i = \mathbf{W}_k \mathbf{x’}_i, k i = W k x ′ i , ∀ i ∈ { 1 , … n } . \forall i \in \{1, \ldots n \}. ∀ i ∈ { 1 , … n } .
请注意,相同的权重矩阵应用于每个输入向量 x i , ∀ i ∈ { i , … , n } \mathbf{x}_i, \forall i \in \{i, \ldots, n\} x i , ∀ i ∈ { i , … , n } . 将每个输入向量 x i \mathbf{x}_i x i 投影为查询、键和值向量后,将每个查询向量 q j , ∀ j ∈ { 1 , … , n } \mathbf{q}_j, \forall j \in \{1, \ldots, n\} q j , ∀ j ∈ { 1 , … , n } 与所有键向量 k 1 , … , k n \mathbf{k}_1, \ldots, \mathbf{k}_n k 1 , … , k n 进行比较。查询向量 q j \mathbf{q}_j q j 与键向量 k 1 , … k n \mathbf{k}_1, \ldots \mathbf{k}_n k 1 , … k n 的相似程度越高,对应的值向量 v j \mathbf{v}_j v j 对于输出向量 x ′ ′ j \mathbf{x”}_j x ′ ′ j 的重要性也越高。具体而言,输出向量 x ′ ′ j \mathbf{x”}_j x ′ ′ j 定义为所有值向量 v 1 , … , v n \mathbf{v}_1, \ldots, \mathbf{v}_n v 1 , … , v n 的加权和加上输入向量 x ′ j \mathbf{x’}_j x ′ j 。权重与查询向量 q j \mathbf{q}_j q j 和相应的键向量 k 1 , … , k n \mathbf{k}_1, \ldots, \mathbf{k}_n k 1 , … , k n 的余弦相似度成比例,这在以下方程中用 Softmax ( K 1 : n ⊺ q j ) \textbf{Softmax}(\mathbf{K}_{1:n}^\intercal \mathbf{q}_j) Softmax ( K 1 : n ⊺ q j ) 数学表达。有关自注意力层的完整描述,请读者参考此博文或原始论文。
好的,这听起来相当复杂。让我们为上面例子中的一个查询向量说明双向自注意力层。为了简单起见,假设我们的示例基于Transformer的解码器只使用一个注意力头config.num_heads = 1,并且没有应用归一化。
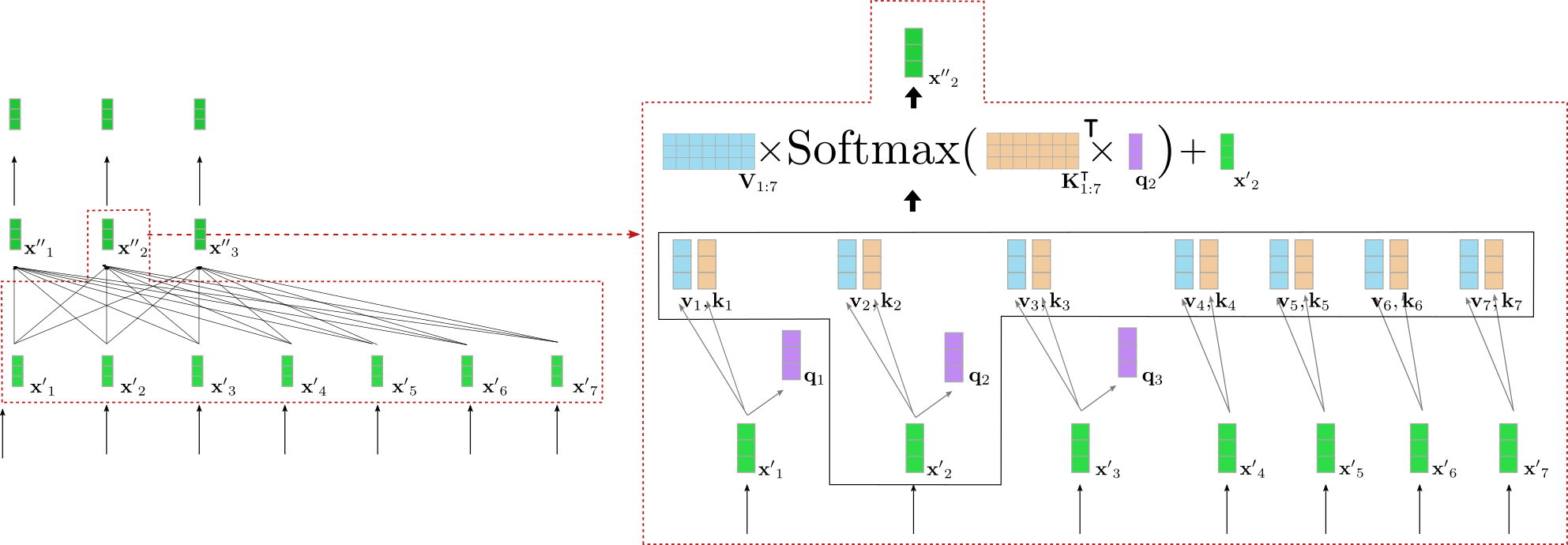
左侧再次显示了之前说明的第二个编码器块,右侧详细展示了第二个输入向量x ′ 2 \mathbf{x’}_2 x ′ 2 对应于输入词”want”的双向自注意力机制。首先,所有输入向量x ′ 1 , … , x ′ 7 \mathbf{x’}_1, \ldots, \mathbf{x’}_7 x ′ 1 , … , x ′ 7 被投影到它们相应的查询向量q 1 , … , q 7 \mathbf{q}_1, \ldots, \mathbf{q}_7 q 1 , … , q 7 (只显示了前三个紫色的查询向量),值向量v 1 , … , v 7 \mathbf{v}_1, \ldots, \mathbf{v}_7 v 1 , … , v 7 (蓝色显示),以及键向量k 1 , … , k 7 \mathbf{k}_1, \ldots, \mathbf{k}_7 k 1 , … , k 7 (橙色显示)。然后,查询向量q 2 \mathbf{q}_2 q 2 与所有键向量的转置相乘,即 K 1 : 7 ⊺ \mathbf{K}_{1:7}^{\intercal} K 1 : 7 ⊺ ,然后进行softmax操作,得到自注意力权重。最后,自注意力权重与相应的值向量相乘,并将输入向量x ′ 2 \mathbf{x’}_2 x ′ 2 加到一起,输出单词”want”的”精炼”表示,即 x ′ ′ 2 \mathbf{x”}_2 x ′ ′ 2 (右侧深绿色显示)。整个等式在右侧方框的上部进行了说明。K 1 : 7 ⊺ \mathbf{K}_{1:7}^{\intercal} K 1 : 7 ⊺ 和q 2 \mathbf{q}_2 q 2 的乘法使得我们可以将”want”的向量表示与其他所有输入向量表示”I”,”to”,”buy”,”a”,”car”,”EOS”进行比较,以使自注意力权重反映出其他输入向量表示x ′ j , 其中 j ≠ 2 \mathbf{x’}_j \text{, with } j \ne 2 x ′ j , 其中 j = 2 ,用于表示单词”want”的”精炼”表示x ′ ′ 2 \mathbf{x”}_2 x ′ ′ 2 的重要性。
为了进一步理解双向自注意力层的影响,假设处理以下句子:” The house is beautiful and well located in the middle of the city where it is easily accessible by public transport “。单词”it”指的是”house”,它与之间相隔了12个位置。在基于Transformer的编码器中,双向自注意力层执行单一的数学操作,将”house”的输入向量与”it”的输入向量相关联(与本节的第一个示例相比)。相比之下,在基于RNN的编码器中,距离为12个位置的单词将需要至少12个数学操作,这意味着在基于RNN的编码器中需要线性数量的数学操作。这使得基于RNN的编码器更难有效地编码输入单词之间的长程依赖关系。
除了使长程依赖更容易学习外,我们可以看到Transformer架构能够并行处理文本。从数学上讲,可以将自注意力公式写成查询、键和值矩阵的乘积:
X ′ ′ 1 : n = V 1 : n Softmax ( Q 1 : n ⊺ K 1 : n ) + X ′ 1 : n .
输出 X ′ ′ 1 : n = x ′ ′ 1 , … , x ′ ′ n 通过一系列矩阵乘法和softmax操作计算得到,可以有效地并行化。注意,在基于RNN的编码器模型中,隐藏状态 c 的计算必须按顺序进行:计算第一个输入向量 x 1 的隐藏状态,然后计算第二个输入向量的隐藏状态,该隐藏状态依赖于第一个隐藏向量的隐藏状态,依此类推。RNN的顺序性阻碍了有效的并行化,并使其在现代GPU硬件上比基于Transformer的编码器模型更低效。
太好了,现在我们应该更好地理解了a)基于Transformer的编码器模型如何有效地建模长程上下文表示,以及b)它们如何高效地处理长序列的输入向量。
现在,让我们编写一个简短的例子,验证我们的MarianMT编码器-解码器模型中编码器部分的理论是否在实践中成立。
1 {}^1 本笔记本不详细解释Transformer模型中前馈层的作用。云等人(2017)认为,前馈层对于将每个上下文向量x ′ i 个体映射到所需的输出空间是至关重要的,而自注意层本身无法做到这一点。值得注意的是,每个输出令牌x ′都由相同的前馈层处理。如需更多详细信息,请阅读该论文。
2 {}^2 然而,EOS输入向量不必附加到输入序列中,但在许多情况下已被证明可以提高性能。与基于Transformer的解码器的第0个BOS目标向量相反,它需要作为起始输入向量来预测第一个目标向量。
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
embeddings = model.get_input_embeddings()
# create ids of encoded input vectors
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# pass input_ids to encoder
encoder_hidden_states = model.base_model.encoder(input_ids, return_dict=True).last_hidden_state
# change the input slightly and pass to encoder
input_ids_perturbed = tokenizer("I want to buy a house", return_tensors="pt").input_ids
encoder_hidden_states_perturbed = model.base_model.encoder(input_ids_perturbed, return_dict=True).last_hidden_state
# compare shape and encoding of first vector
print(f"Length of input embeddings {embeddings(input_ids).shape[1]}. Length of encoder_hidden_states {encoder_hidden_states.shape[1]}")
# compare values of word embedding of "I" for input_ids and perturbed input_ids
print("Is encoding for `I` equal to its perturbed version?: ", torch.allclose(encoder_hidden_states[0, 0], encoder_hidden_states_perturbed[0, 0], atol=1e-3))输出:
输入嵌入的长度为7。编码器隐藏状态的长度为7。
“I” 的编码是否等于其扰动版本?:False我们比较输入词嵌入的长度,即对应于 X 1 : n 的 embeddings(input_ids),与编码器隐藏状态的长度,即对应于 X ‾ 1 : n 的 encoder_hidden_states。同时,我们将单词序列“I want to buy a car”和略微扰动的版本“I want to buy a house”通过编码器进行转发,以检查当输入序列中仅改变最后一个单词时,第一个输出的编码(对应于“I”)是否有所不同。
预期结果是输入词嵌入和编码器输出编码的长度,即 len(X 1 : n) 和 len(X ‾ 1 : n),是相等的。其次,可以注意到当将最后一个单词从“car”改为“house”时,“I”的编码输出向量的值是不同的。如果理解了双向自注意力的原理,这并不会令人惊讶。
顺便提一下,自编码模型(如BERT)与基于Transformer的编码器模型具有完全相同的架构。自编码模型利用这种架构对开放域文本数据进行大规模的自监督预训练,以便将任何单词序列映射到深度的双向表示。在Devlin等人(2018)的论文中,作者展示了一个预训练的BERT模型在一个特定任务的分类层上能够取得最先进的结果。🤗Transformers中的所有自编码模型可以在这里找到。
解码器
如Encoder-Decoder部分所述,基于Transformer的解码器定义了给定上下文编码序列的目标序列的条件概率分布:
p θ d e c ( Y 1 : m ∣ X ‾ 1 : n ),
根据贝叶斯定理,可以将其分解为给定上下文编码序列和所有先前目标向量的下一个目标向量的条件分布的乘积:
p θ d e c ( Y 1 : m ∣ X ‾ 1 : n ) = ∏ i = 1 m p θ d e c ( y i ∣ Y 0 : i − 1 , X ‾ 1 : n )。
首先,让我们了解一下基于Transformer的解码器如何定义概率分布。基于Transformer的解码器是一堆解码器块,后面跟着一个稠密层,即“语言模型头部”。解码器块的堆栈将上下文编码序列 X ‾ 1 : n 和一个目标向量序列(在前面加上了BOS向量并截取到最后一个目标向量),即 Y 0 : i − 1,映射到一个编码的目标向量序列 Y ‾ 0 : i − 1。然后,“语言模型头部”将编码的目标向量序列 Y ‾ 0 : i − 1 映射到一个logit向量序列 L 1 : n = l 1, …, l n,其中每个logit向量 l i 的维度对应于词汇表的大小。这样,对于每个 i ∈ {1, …, n},可以通过在 l i 上应用softmax操作来获得整个词汇表的概率分布。这些分布定义了条件分布:
分别是通过条件概率分布$p_{\theta_{dec}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n})$计算得到的。其中$i \in \{1, \ldots, n\}$。
“LM头”通常与词嵌入矩阵的转置相关联,即$W_{emb}^{\intercal} = [\mathbf{y}^1, \ldots, \mathbf{y}^{vocab}]^{\intercal}$。即对于所有$i \in \{0, \ldots, n – 1\}$,“LM头”层将编码输出向量$\mathbf{\overline{y}}_i$与词汇表中的所有词嵌入$y^1, \ldots, y^{vocab}$进行比较,得到相似性得分向量$\mathbf{l}_{i+1}$。Softmax操作将相似性得分转化为概率分布。对于每个$i \in \{1, \ldots, n\}$,以下方程成立:
$p_{\theta_{dec}}(\mathbf{y} | \mathbf{\overline{X}}_{1:n}, \mathbf{Y}_{0:i-1}) = \text{Softmax}(f_{\theta_{dec}}(\mathbf{\overline{X}}_{1:n}, \mathbf{Y}_{0:i-1})) = \text{Softmax}(\mathbf{W}_{emb}^{\intercal} \mathbf{\overline{y}}_{i-1}) = \text{Softmax}(\mathbf{l}_i)$。
将上述内容综合起来,为了建模目标向量序列$\mathbf{Y}_{1:m}$的条件分布,首先将目标向量$\mathbf{Y}_{1:m-1}$(前缀为特殊的BOS向量$\mathbf{y}_0$)与上下文化编码序列$\mathbf{\overline{X}}_{1:n}$一起映射到得到的相似性得分向量序列$\mathbf{L}_{1:m}$。随后,将每个相似性得分向量$\mathbf{l}_i$通过Softmax操作转化为目标向量$\mathbf{y}_i$的条件概率分布。最后,将所有目标向量$\mathbf{y}_1, \ldots, \mathbf{y}_m$的条件概率相乘得到完整目标向量序列的条件概率。
pθdec(Y1:m | Ā1:n) = ∏i=1m pθdec(yi | Y0:i-1, Ā1:n)。
与基于Transformer的编码器不同,基于Transformer的解码器中,编码输出向量ŷi应该是下一个目标向量yi+1的良好表示,而不是输入向量本身。此外,编码输出向量ŷi应该在所有上下文化编码序列X̄1:n的条件下。为了满足这些要求,每个解码器块由一个单向自注意层、一个交叉注意层和两个前馈层组成。单向自注意层仅将其输入向量ŷ’j与所有先前输入向量ŷ’i(其中i≤j)相关联,以对下一个目标向量的概率分布进行建模。交叉注意层将其输入向量ŷ”j与所有上下文化的编码向量X̄1:n相关联,以在编码器的输入上调节下一个目标向量的概率分布。
好的,现在让我们来可视化一下我们的英文到德文翻译示例中的基于Transformer的解码器。
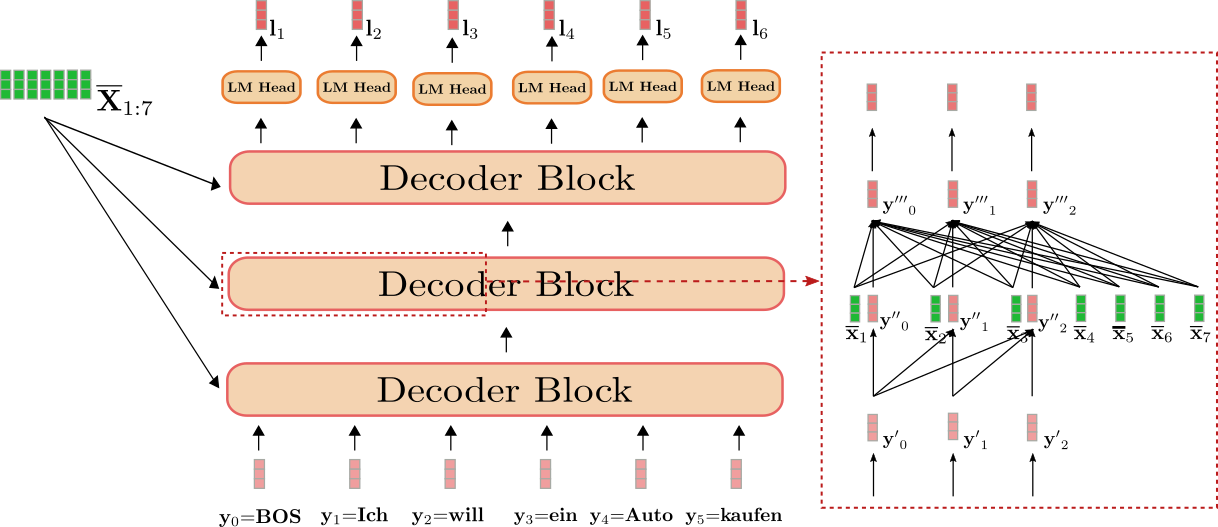
我们可以看到解码器将输入Y0:5(”BOS”, “Ich”, “will”, “ein”, “Auto”, “kaufen”,显示为浅红色)与上下文化的序列”I”, “want”, “to”, “buy”, “a”, “car”, “EOS”,即X̄1:7(显示为深绿色)映射到逻辑向量L1:6(显示为深红色)。
对每个l1,l2,…,l5应用softmax操作,可以定义条件概率分布:
pθdec(y | BOS, X̄1:7),pθdec(y | BOS Ich, X̄1:7),…,pθdec(y | BOS Ich will ein Auto kaufen, X̄1:7)。
因此,对于:
p θ d e c ( Ich will ein Auto kaufen EOS ∣ X ‾ 1 : n ) p_{\theta_{dec}}(\text{Ich will ein Auto kaufen EOS} | \mathbf{\overline{X}}_{1:n}) p θ d e c ( Ich will ein Auto kaufen EOS ∣ X 1 : n )
可以计算为以下乘积:
p θ d e c ( Ich ∣ BOS , X ‾ 1 : 7 ) × … × p θ d e c ( EOS ∣ BOS Ich will ein Auto kaufen , X ‾ 1 : 7 ) . p_{\theta_{dec}}(\text{Ich} | \text{BOS}, \mathbf{\overline{X}}_{1:7}) \times \ldots \times p_{\theta_{dec}}(\text{EOS} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}). p θ d e c ( Ich ∣ BOS , X 1 : 7 ) × … × p θ d e c ( EOS ∣ BOS Ich will ein Auto kaufen , X 1 : 7 ) .
右侧红框显示了前三个目标向量 y 0 , y 1 , y 2 的解码器块。在下部,展示了单向自注意力机制;在中间,展示了交叉注意力机制。让我们首先关注单向自注意力。
与双向自注意力一样,在单向自注意力中,查询向量 q 0 , … , q m − 1 \mathbf{q}_0, \ldots, \mathbf{q}_{m-1} q 0 , … , q m − 1 (下方紫色显示),键向量 k 0 , … , k m − 1 \mathbf{k}_0, \ldots, \mathbf{k}_{m-1} k 0 , … , k m − 1 (下方橙色显示),以及值向量 v 0 , … , v m − 1 \mathbf{v}_0, \ldots, \mathbf{v}_{m-1} v 0 , … , v m − 1 (下方蓝色显示),都是从各自的输入向量 y ′ 0 , … , y ′ m − 1 \mathbf{y’}_0, \ldots, \mathbf{y’}_{m-1} y ′ 0 , … , y ′ m − 1 (下方浅红色显示)投影而来。然而,在单向自注意力中,每个查询向量 q i \mathbf{q}_i q i 仅与其相应的键向量和之前的键向量比较,即 k 0 , … , k i \mathbf{k}_0, \ldots, \mathbf{k}_i k 0 , … , k i ,以得到相应的注意力权重。这样可以防止输出向量 y ′ ′ j \mathbf{y”}_j y ′ ′ j (下方深红色显示)包含关于后续输入向量 y i \mathbf{y}_i y i (其中 i > j \mathbf{y}_i, \text{ with } i > j y i ,其中 i > j 对于所有 j ∈ { 0 , … , m − 1 } j \in \{0, \ldots, m – 1 \} j ∈ { 0 , … , m − 1 })的任何信息。与双向自注意力一样,注意力权重乘以其相应的值向量,然后求和。
我们可以总结单向自注意力如下:
y ′ ′ i = V 0 : i Softmax ( K 0 : i ⊺ q i ) + y ′ i . \mathbf{y”}_i = \mathbf{V}_{0: i} \textbf{Softmax}(\mathbf{K}_{0: i}^\intercal \mathbf{q}_i) + \mathbf{y’}_i. y ′ ′ i = V 0 : i Softmax ( K 0 : i ⊺ q i ) + y ′ i .
请注意,键和值向量的索引范围为0:i 0:i 0 : i,而不是0:m-1 0:m-1 0 : m − 1,后者是双向自注意力中键向量的范围。
让我们以示例中的输入向量y ′ 1 \mathbf{y’}_1 y ′ 1 说明单向自注意力。
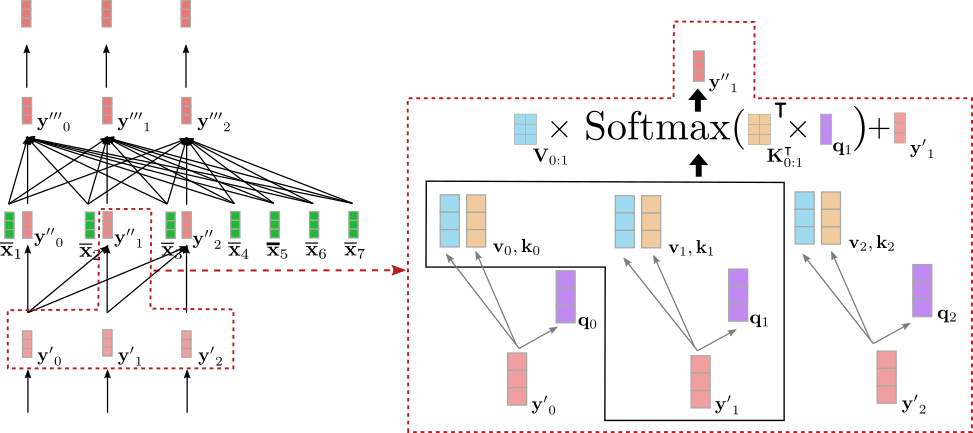
可以看到y ′ ′ 1 \mathbf{y”}_1 y ′ ′ 1 仅依赖于y ′ 0 \mathbf{y’}_0 y ′ 0 和y ′ 1 \mathbf{y’}_1 y ′ 1 。因此,我们将单词”Ich”的向量表示,即y ′ 1 \mathbf{y’}_1 y ′ 1 ,只与自身和”BOS”目标向量y ′ 0 \mathbf{y’}_0 y ′ 0 相关联,而不与单词”will”的向量表示y ′ 2 \mathbf{y’}_2 y ′ 2 相关联。
那么为什么在解码器中使用单向自注意力而不是双向自注意力很重要呢?如上所述,基于Transformer的解码器将一个输入向量序列Y 0:m-1 \mathbf{Y}_{0:m-1} Y 0:m-1 映射到对应于下一个解码器输入向量的逻辑值,即L 1:m \mathbf{L}_{1:m} L 1:m 。在我们的示例中,这意味着,例如,输入向量y 1 \mathbf{y}_1 y 1 = “Ich”被映射到逻辑向量l 2 \mathbf{l}_2 l 2 ,然后用于预测输入向量y 2 \mathbf{y}_2 y 2 。因此,如果y ′ 1 \mathbf{y’}_1 y ′ 1 可以访问以下输入向量Y ′ 2:5 \mathbf{Y’}_{2:5} Y ′ 2:5 ,解码器将简单地将”will”的向量表示,即y ′ 2 \mathbf{y’}_2 y ′ 2 ,复制为其输出y ′ ′ 1 \mathbf{y”}_1 y ′ ′ 1 。这将被转发到最后一层,使得编码输出向量y ‾ 1 \mathbf{\overline{y}}_1 y 1 基本上对应于向量表示y 2 \mathbf{y}_2 y 2 。
这显然是不利的,因为基于Transformer的解码器将永远不会学习到在给定所有先前单词的情况下预测下一个单词,而只是将目标向量y i \mathbf{y}_i y i 通过网络复制到y ‾ i − 1 \mathbf{\overline{y}}_{i-1} y i − 1 ,对于所有 i ∈ { 1 , … , m } i \in \{1, \ldots, m \} i ∈ { 1 , … , m }。为了定义下一个目标向量的条件分布,分布不能以目标向量本身为条件。从 p ( y ∣ Y 0 : i , X ‾ ) p(\mathbf{y} | \mathbf{Y}_{0:i}, \mathbf{\overline{X}}) p ( y ∣ Y 0 : i , X )预测 y i \mathbf{y}_i y i 并没有太多意义,因为该分布是以它所要建模的目标向量为条件的。因此,单向自注意力架构允许我们定义一个因果概率分布,这对于有效地建模下一个目标向量的条件分布是必要的。
太棒了!现在我们可以转向连接编码器和解码器的层——交叉注意力机制!
交叉注意力层以两个向量序列作为输入:单向自注意力层的输出,即Y ′ ′ 0:m-1 \mathbf{Y”}_{0:m-1} Y ′ ′ 0:m-1 和上下文编码向量X ‾ 1:n \mathbf{\overline{X}}_{1:n} X 1:n 。与自注意力层一样,查询向量q 0, … , q m-1 \mathbf{q}_0, \ldots, \mathbf{q}_{m-1} q 0 , … , q m − 1 是前一层的输出向量,即Y ′ ′ 0:m-1 \mathbf{Y”}_{0:m-1} Y ′ ′ 0:m-1 的投影。然而,键向量k 0, … , k m-1 \mathbf{k}_0, \ldots, \mathbf{k}_{m-1} k 0 , … , k m − 1 和值向量v 0, … , v m-1 \mathbf{v}_0, \ldots, \mathbf{v}_{m-1} v 0 , … , v m − 1 是上下文编码向量X ‾ 1:n \mathbf{\overline{X}}_{1:n} X 1:n 的投影。定义了键、值和查询向量之后,查询向量q i \mathbf{q}_i q i 与所有键向量进行比较,并使用相应的分数对值向量进行加权,就像双向自注意力的情况一样,为所有 i ∈ 0, … , m-1 i \in \{0, \ldots, m-1\} i ∈ 0, … , m − 1给出输出向量y ′ ′ ′ i \mathbf{y”’}_i y ′ ′ ′ i 。交叉注意力可以总结如下:
y ′ ′ ′ i = V 1 : n Softmax ( K 1 : n ⊺ q i ) + y ′ ′ i.
请注意,键和值向量的索引范围为 1 : n,对应于上下文编码向量的数量。
让我们为上述示例中的输入向量 y ′ ′ 1 可视化交叉注意力机制。
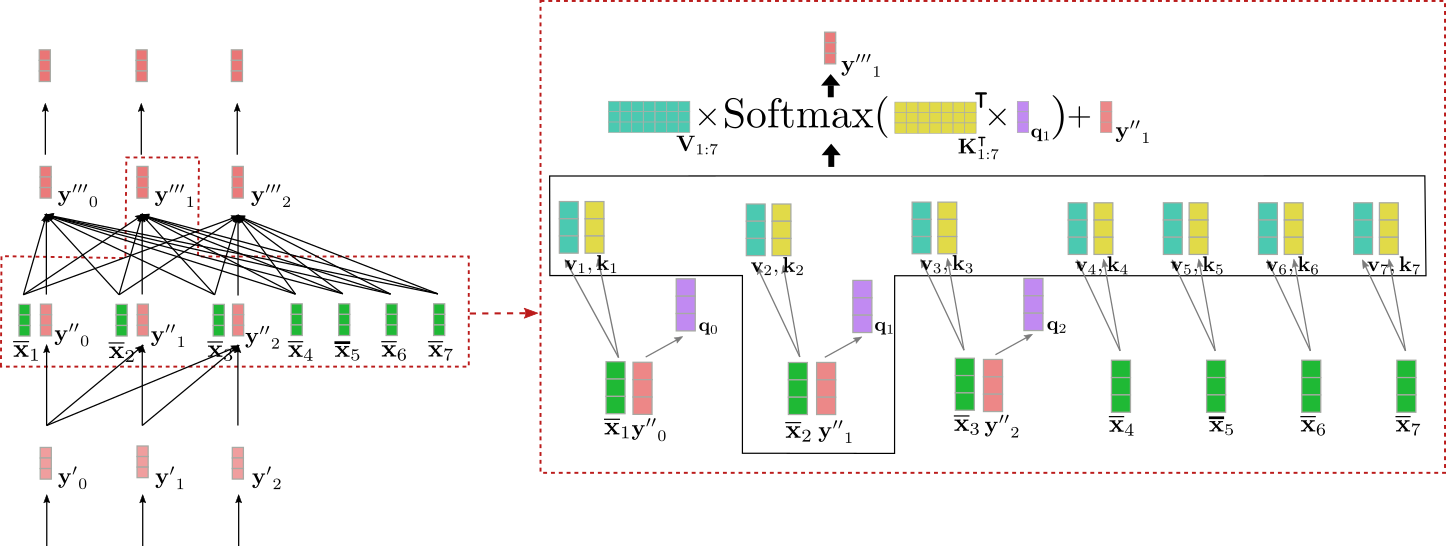
我们可以看到查询向量 q 1(显示为紫色)是从 y ′ ′ 1(显示为红色)派生出来的,因此依赖于单词 “Ich” 的向量表示。然后,查询向量 q 1 将与键向量 k 1 ,…,k 7(显示为黄色)进行比较,这些键向量对应于所有编码器输入向量 X 1 : n = “I want to buy a car EOS” 的上下文编码表示。这将直接将 “Ich” 的向量表示与所有编码器输入向量相关联。最后,注意权重与值向量 v 1 ,…,v 7(显示为青色)相乘,以得到除了输入向量 y ′ ′ 1 之外的输出向量 y ′ ′ ′ 1(显示为深红色)。
直观上,这里到底发生了什么?每个输出向量 y ′ ′ ′ i 是所有编码器输入值投影 v 1 ,…,v 7 的加权求和,再加上输入向量本身 y ′ ′ i(参见上面的公式)。要理解的关键机制是:根据输入解码器向量 q i 的查询投影与编码器输入向量 k j 的键投影的相似程度,编码器输入向量 v j 的值投影就越重要。简单地说,这意味着解码器输入表示与编码器输入表示越相关,输入表示对解码器输出表示的影响就越大。
太棒了!现在我们可以看到这种架构如何很好地将每个输出向量 y ′ ′ ′ i 与编码器输入向量 X ‾ 1 : n 和输入向量 y ′ ′ i 的交互条件化。此时的另一个重要观察是,该架构完全独立于上下文编码向量 X ‾ 1 : n 的数量 n。所有投影矩阵 W k cross 和 W v cross 用于派生键向量 k 1 ,…,k n 和值向量 v 1 ,…,v n 分别在位置 1 ,…,n 和所有值向量 v 1 ,…,v n 中共享。然后将所有值向量 v 1 ,…,v n 相加得到一个加权平均向量。现在也很明显,为什么基于 Transformer 的解码器不会遭受基于 RNN 的解码器所遇到的长距离依赖问题。因为每个解码器逻辑向量直接依赖于每个编码输出向量,比较第一个编码输出向量和最后一个解码器逻辑向量的数学运算数量基本上只有一个。
总结一下,单向自注意力层负责根据所有前一个解码器输入向量和当前输入向量来对每个输出向量进行条件编码,而交叉注意力层负责进一步对每个输出向量进行条件编码。
为了验证我们的理论理解,让我们继续上面编码器部分的代码示例。
1 {}^1 1 单词嵌入矩阵 W emb \mathbf{W}_{\text{emb}} W emb 为每个输入单词提供一个唯一的无上下文向量表示。该矩阵通常被固定为”LM Head”层。然而,”LM Head”层也可以完全独立于”编码向量到逻辑值”权重映射。
2 {}^2 2 对于基于Transformer的模型,详细解释前馈层在其中的作用超出了本笔记本的范围。Yun等人(2017)认为,前馈层对于将每个上下文向量 x ′ i \mathbf{x’}_i x ′ i 个别映射到期望的输出空间非常重要,而自注意力层本身无法做到这一点。需要注意的是,每个输出令牌 x ′ \mathbf{x’} x ′ 都由相同的前馈层处理。更多细节,请参阅论文。
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
embeddings = model.get_input_embeddings()
# create token ids for encoder input
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# pass input token ids to encoder
encoder_output_vectors = model.base_model.encoder(input_ids, return_dict=True).last_hidden_state
# create token ids for decoder input
decoder_input_ids = tokenizer("<pad> Ich will ein", return_tensors="pt", add_special_tokens=False).input_ids
# pass decoder input ids and encoded input vectors to decoder
decoder_output_vectors = model.base_model.decoder(decoder_input_ids, encoder_hidden_states=encoder_output_vectors).last_hidden_state
# derive embeddings by multiplying decoder outputs with embedding weights
lm_logits = torch.nn.functional.linear(decoder_output_vectors, embeddings.weight, bias=model.final_logits_bias)
# change the decoder input slightly
decoder_input_ids_perturbed = tokenizer("<pad> Ich will das", return_tensors="pt", add_special_tokens=False).input_ids
decoder_output_vectors_perturbed = model.base_model.decoder(decoder_input_ids_perturbed, encoder_hidden_states=encoder_output_vectors).last_hidden_state
lm_logits_perturbed = torch.nn.functional.linear(decoder_output_vectors_perturbed, embeddings.weight, bias=model.final_logits_bias)
# compare shape and encoding of first vector
print(f"Shape of decoder input vectors {embeddings(decoder_input_ids).shape}. Shape of decoder logits {lm_logits.shape}")
# compare values of word embedding of "I" for input_ids and perturbed input_ids
print("Is encoding for `Ich` equal to its perturbed version?: ", torch.allclose(lm_logits[0, 0], lm_logits_perturbed[0, 0], atol=1e-3))输出:
Shape of decoder input vectors torch.Size([1, 5, 512]). Shape of decoder logits torch.Size([1, 5, 58101])
Is encoding for `Ich` equal to its perturbed version?: True我们将解码器输入单词嵌入的输出形状(即embeddings(decoder_input_ids),对应于 Y 0 : 4 \mathbf{Y}_{0: 4} Y 0 : 4 ,这里 <pad> 对应于BOS,”Ich will das”被标记为4个令牌)与lm_logits的维度(对应于L 1 : 5 \mathbf{L}_{1:5} L 1 : 5 )进行了比较。此外,我们将单词序列”<pad> Ich will ein”和略微扰动的版本”<pad> Ich will das”连同encoder_output_vectors一起通过解码器传递,以检查当只有输入序列中的最后一个单词改变时(”ein” -> “das”),第二个lm_logit(对应于”Ich”)是否有所不同。
正如预期的那样,解码器输入词嵌入和lm_logits的输出形状,即Y0:4和L1:5的维度在最后一维上是不同的。虽然序列长度是相同的(=5),解码器输入词嵌入的维度对应于model.config.hidden_size,而lm_logit的维度对应于词汇表大小model.config.vocab_size,如上所述。其次,当将最后一个单词从”ein”更改为”das”时,编码输出向量l1 = “Ich”的值是相同的。然而,如果理解了单向自注意力,这应该不会令人惊讶。
最后一点,自回归模型(如GPT2)与基于Transformer的解码器模型具有相同的架构,前提是移除了交叉注意力层,因为独立的自回归模型不依赖于任何编码器输出。因此,自回归模型本质上与自编码模型相同,但是将双向注意力替换为单向注意力。这些模型还可以在大规模开放领域的文本数据上进行预训练,以在自然语言生成(NLG)任务上展现出令人印象深刻的性能。在Radford等人(2019)的论文中,作者展示了经过预训练的GPT2模型在各种NLG任务上可以实现SOTA或接近SOTA的结果,而不需要太多微调。所有🤗Transformers的自回归模型都可以在这里找到。
好了,就这些!现在,您应该对基于Transformer的编码器-解码器模型及其如何与🤗Transformers库一起使用有了很好的理解。
非常感谢Victor Sanh、Sasha Rush、Sam Shleifer、Oliver Åstrand、Ted Moskovitz和Kristian Kyvik提供宝贵的反馈。
附录
如上所述,以下代码片段展示了如何为基于Transformer的编码器-解码器模型编写一个简单的生成方法。在这里,我们使用torch.argmax实现了一个简单的贪婪解码方法来对目标向量进行采样。
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
# 创建编码输入向量的id
input_ids = tokenizer("我想买一辆车", return_tensors="pt").input_ids
# 创建BOS标记
decoder_input_ids = tokenizer("<pad>", add_special_tokens=False, return_tensors="pt").input_ids
assert decoder_input_ids[0, 0].item() == model.config.decoder_start_token_id, "`decoder_input_ids`应该对应于`model.config.decoder_start_token_id`"
# 步骤1
# 将input_ids传递给编码器和解码器,并将BOS标记传递给解码器以获取第一个logit
outputs = model(input_ids, decoder_input_ids=decoder_input_ids, return_dict=True)
# 获取编码序列
encoded_sequence = (outputs.encoder_last_hidden_state,)
# 获取logits
lm_logits = outputs.logits
# 用最高概率采样最后一个标记
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
# 连接
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# 步骤2
# 重用encoded_inputs,并将BOS + "Ich"传递给解码器以获取第二个logit
lm_logits = model(None, encoder_outputs=encoded_sequence, decoder_input_ids=decoder_input_ids, return_dict=True).logits
# 再次用最高概率采样最后一个标记
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
# 再次连接
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# 步骤3
lm_logits = model(None, encoder_outputs=encoded_sequence, decoder_input_ids=decoder_input_ids, return_dict=True).logits
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# 看看我们到目前为止生成了什么!
print(f"到目前为止生成的文本: {tokenizer.decode(decoder_input_ids[0], skip_special_tokens=True)}")
# 这也可以用循环来编写。输出:
已生成:Ich will ein在这个代码示例中,我们展示了之前描述的内容。我们将输入“我想买一辆车”与 BOS(开始标记)一起传递给编码器-解码器模型,并从第一个对数 l 1 1 1 (即第一个 lm_logits 行)中进行采样。在这里,我们的采样策略很简单:贪婪地选择具有最高概率的下一个解码器输入向量。以自回归的方式,我们将采样的解码器输入向量与先前的输入一起传递给编码器-解码器模型并再次进行采样。我们重复这个过程三次。结果是,模型生成了单词“Ich will ein”。结果非常准确 – 这是输入的正确翻译的开始部分。
在实践中,会使用更复杂的解码方法对 lm_logits 进行采样。其中大部分都在本博文中介绍。