PyTorch模型性能分析与优化 —— 第三部分
PyTorch模型性能分析与优化 —— 第三部分
如何减少“Cuda Memcpy Async”事件以及为什么应注意布尔掩码操作
这是有关使用PyTorch Profiler和TensorBoard分析和优化PyTorch模型的一系列文章的第三部分。我们的目的是强调GPU训练工作负载的性能分析和优化对训练速度和成本的潜在影响。特别是,我们希望展示像PyTorch Profiler和TensorBoard这样的性能分析工具对所有机器学习开发人员的可访问性。从我们在文章中讨论的技术中,您不需要成为CUDA专家就可以获得有意义的性能提升。
在我们的第一篇文章中,我们演示了如何使用PyTorch Profiler TensorBoard插件的不同视图来识别性能问题,并回顾了一些常用的加速训练技术。在第二篇文章中,我们展示了如何使用TensorBoard插件的Trace View来识别从CPU到GPU的张量复制以及反向复制的情况。这种数据移动会导致同步点,并且会大大降低训练速度,通常情况下是无意的,有时可以很容易地避免。本文的主题是我们在GPU和CPU之间遇到的与张量复制无关的同步点。与张量复制的情况一样,这些同步点会导致训练步骤停滞,并且大大降低训练总时间。我们将演示这些情况的存在,以及如何使用PyTorch Profiler和PyTorch Profiler TensorBoard插件的Trace View来识别它们,以及在构建模型时最小化此类同步事件可能带来的性能优势。
与我们之前的文章一样,我们将定义一个玩具PyTorch模型,然后迭代地分析其性能,识别瓶颈,并尝试解决它们。我们将在亚马逊EC2 g5.2xlarge实例上运行实验(包含一个NVIDIA A10G GPU和8个虚拟CPU),并使用官方的AWS PyTorch 2.0 Docker镜像。请记住,我们描述的某些行为可能在不同版本的PyTorch之间有所不同。
玩具例子
在以下区块中,我们介绍一个玩具PyTorch模型,该模型对256×256的输入图像执行语义分割,即,它接收一个256×256的RGB图像,并输出一个256×256的“每像素”标签映射到十个语义类别之一。
import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optimimport torch.profilerimport torch.utils.datafrom torch import Tensorclass Net(nn.Module): def __init__(self, num_hidden=10, num_classes=10): super().__init__() self.conv_in = nn.Conv2d(3, 10, 3, padding='same') hidden = [] for i in range(num_hidden): hidden.append(nn.Conv2d(10, 10, 3, padding='same')) hidden.append(nn.ReLU()) self.hidden = nn.Sequential(*hidden) self.conv_out = nn.Conv2d(10, num_classes, 3, padding='same') def forward(self, x): x = F.relu(self.conv_in(x)) x = self.hidden(x) x = self.conv_out(x) return x为了训练我们的模型,我们将使用标准的交叉熵损失,并进行一些修改:
- 我们假设目标标签包含一个表示我们要从损失计算中排除的像素的忽略值。
- 我们假设其中一个语义标签将某些像素标识为图像的“背景”。我们定义我们的损失函数将这些标签视为忽略标签。
- 我们仅在遇到包含至少两个唯一值的目标张量的批次时更新模型权重。
虽然我们选择了这些修改来进行演示,但这些类型的操作并不罕见,可以在许多“标准”PyTorch模型中找到。由于我们已经是性能分析的“专家”,我们已经在损失函数中的每个操作周围使用了torch.profiler.record_function上下文管理器(如我们在第二篇文章中所述)。
“`html
class MaskedLoss(nn.Module): def __init__(self, ignore_val=-1, num_classes=10): super().__init__() self.ignore_val = ignore_val self.num_classes = num_classes self.loss = torch.nn.CrossEntropyLoss() def cross_entropy(self, pred: Tensor, target: Tensor) -> Tensor: # create a boolean mask of valid labels with torch.profiler.record_function('create mask'): mask = target != self.ignore_val # permute the logits in preparation for masking with torch.profiler.record_function('permute'): permuted_pred = torch.permute(pred, [0, 2, 3, 1]) # apply the boolean mask to the targets and logits with torch.profiler.record_function('mask'): masked_target = target[mask] masked_pred = permuted_pred[mask.unsqueeze(-1).expand(-1, -1, -1, self.num_classes)] masked_pred = masked_pred.reshape(-1, self.num_classes) # calculate the cross-entropy loss with torch.profiler.record_function('calc loss'): loss = self.loss(masked_pred, masked_target) return loss def ignore_background(self, target: Tensor) -> Tensor: # discover all indices where target label is "background" with torch.profiler.record_function('non_zero'): inds = torch.nonzero(target == self.num_classes - 1, as_tuple=True) # reset all "background" labels to the ignore index with torch.profiler.record_function('index assignment'): target[inds] = self.ignore_val return target def forward(self, pred: Tensor, target: Tensor) -> Tensor: # ignore background labels target = self.ignore_background(target) # retrieve a list of unique elements in target with torch.profiler.record_function('unique'): unique = torch.unique(target) # check if the number of unique items pass the threshold with torch.profiler.record_function('numel'): ignore_loss = torch.numel(unique) < 2 # calculate the cross-entropy loss loss = self.cross_entropy(pred, target) # zero the loss in the case that the number of unique elements # is below the threshold if ignore_loss: loss = 0. * loss return loss我们的损失函数看起来很简单,对吗?错!接下来我们将会看到,损失函数中包含了一些会触发主机和设备同步事件的操作,这些操作会大大降低训练速度,而这些操作并不涉及将张量从GPU中拷贝出来或拷贝进去。和我们之前的文章一样,我们在读下去之前向你提出一个挑战,试着在阅读之前找出三个性能优化的机会。
为了我们的演示目的,我们使用了随机生成的图像和像素级别的标签映射,如下所示。
from torch.utils.data import Dataset# 一个包含随机图像和标签映射的数据集class FakeDataset(Dataset): def __init__(self, num_classes=10): super().__init__() self.num_classes = num_classes self.img_size = [256, 256] def __len__(self): return 1000000 def __getitem__(self, index): rand_image = torch.randn([3]+self.img_size, dtype=torch.float32) rand_label = torch.randint(low=-1, high=self.num_classes, size=self.img_size) return rand_image, rand_labeltrain_set = FakeDataset()train_loader = torch.utils.data.DataLoader(train_set, batch_size=256, shuffle=True, num_workers=8, pin_memory=True)最后,我们定义了训练步骤,并配置了PyTorch Profiler:
device = torch.device("cuda:0")model = Net().cuda(device)criterion = MaskedLoss().cuda(device)optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)model.train()# 用性能分析器包装的训练循环with torch.profiler.profile( schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1), on_trace_ready=torch.profiler.tensorboard_trace_handler('/tmp/prof'), record_shapes=True, profile_memory=True, with_stack=True) as prof: for step, data in enumerate(train_loader): inputs = data[0].to(device=device, non_blocking=True) labels = data[1].to(device=device, non_blocking=True) if step >= (1 + 4 + 3) * 1: break outputs = model(inputs) loss = criterion(outputs, labels) optimizer.zero_grad(set_to_none=True) loss.backward() optimizer.step() prof.step()如果你简单地运行这个训练脚本,你可能会看到高的GPU利用率(约90%),而不知道有什么问题。只有通过性能分析,我们才能确定潜在的性能瓶颈和训练加速的潜在机会。因此,废话不多说,让我们来看看我们的模型表现如何。
初始性能结果
在本文中,我们将重点介绍PyTorch Profiler TensorBoard插件的Trace View。请参考我们之前的文章,了解如何使用插件支持的其他视图。
在下面的图像中,我们展示了我们玩具模型的单个训练步骤的Trace View。
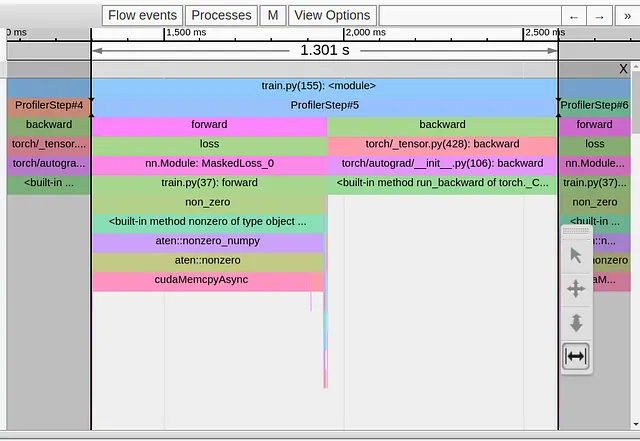
我们可以清楚地看到,我们的1.3秒长的训练步骤完全被第一行loss函数中的torch.nonzero操作所主导。所有其他的操作都集中在巨大的cudaMemcpyAsyn事件的两侧。发生了什么?!为什么这样一个看似无害的操作会引起如此巨大的问题?
也许我们不应该感到惊讶,因为torch.nonzero的文档中包含了以下注释:“当input在CUDA上时,torch.nonzero()会导致主机-设备同步。”同步的需要源于这样一个事实,与其他常见的PyTorch操作不同,torch.nonzero返回的张量的大小是不确定的。CPU不知道输入张量中有多少非零元素。它需要等待GPU发送同步事件,以便执行适当的GPU内存分配并正确准备后续的PyTorch操作。
请注意,cudaMempyAsync的长度并不反映torch.nonzero操作的复杂性,而是反映CPU需要等待GPU完成之前所有由CPU启动的内核的时间。例如,如果我们在第一个调用之后立即进行额外的torch.nonzero调用,我们的第二个cudaMempyAsync事件会比第一个事件的长度明显更短,因为CPU和GPU已经更或多或少地“同步”了。(请记住,这个解释是来自一个非CUDA专家,所以你可以根据自己的理解来理解它…)
优化 #1:减少torch.nonzero操作的使用
既然我们了解了瓶颈的来源,挑战就在于找到一个执行相同逻辑但不触发主机-设备同步事件的替代操作序列。在我们的损失函数的情况下,我们可以使用torch.where操作轻松实现这一点,如下面的代码块所示:
def ignore_background(self, target: Tensor) -> Tensor: with torch.profiler.record_function('update background'): target = torch.where(target==self.num_classes-1, -1*torch.ones_like(target),target) return target在下面的图像中,我们展示了进行此更改后的Trace View。
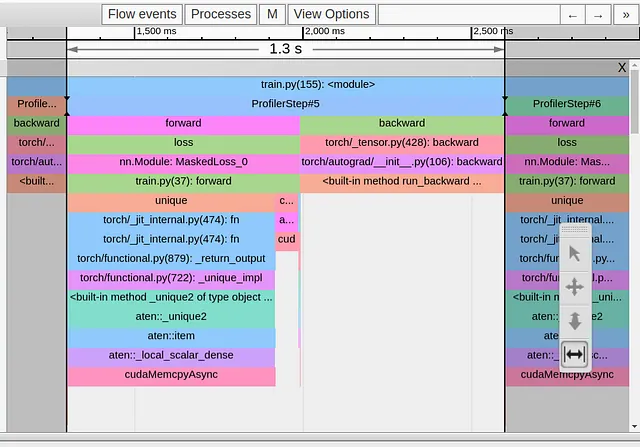
虽然我们成功地删除了由torch.nonzero操作引起的cudaMempyAsync,但它立即被torch.unique操作引起的一个替代操作所取代,而且我们的步骤时间没有改变。在这里,PyTorch的文档没有那么友好,但基于我们之前的经验,我们可以假设,一次又一次,我们都会因为使用大小不确定的张量而遭受主机-设备同步事件的困扰。
优化 #2:减少torch.unique操作的使用
将torch.unique操作符替换为等效的替代方案并不总是可能的。然而,在我们的情况下,我们实际上并不需要知道唯一标签的值,我们只需知道唯一标签的数量。这可以通过对扁平化的目标张量应用torch.sort操作并计算结果步函数中的步数来计算。
def forward(self, pred: Tensor, target: Tensor) -> Tensor: # 忽略背景标签 target = self.ignore_background(target) # 对标签列表进行排序 with torch.profiler.record_function('sort'): sorted,_ = torch.sort(target.flatten()) # 确定结果阶跃函数的步骤 with torch.profiler.record_function('deriv'): deriv = sorted[1:]-sorted[:-1] # 统计步数 with torch.profiler.record_function('count_nonzero'): num_unique = torch.count_nonzero(deriv)+1 # 计算交叉熵损失 loss = self.cross_entropy(pred, target) # 如果唯一元素数低于阈值,则将损失置零 with torch.profiler.record_function('where'): loss = torch.where(num_unique<2, 0.*loss, loss) return loss在下面的图片中,我们捕捉了第二次优化后的Trace View:
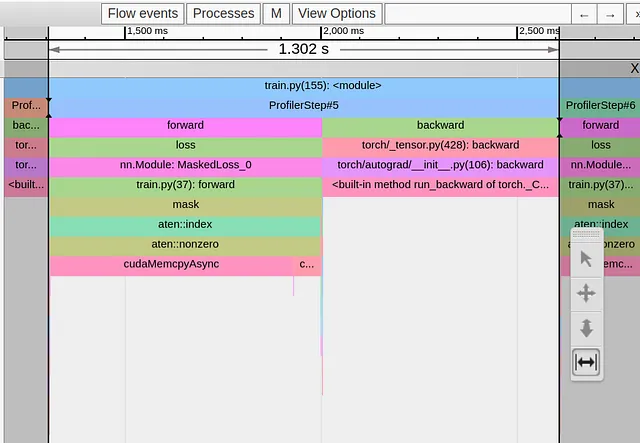
再一次,我们解决了一个瓶颈,却面临着一个新的瓶颈,这次是来自布尔掩码例程。
布尔掩码是我们常常使用的一种例程,它可以减少所需的总机器操作数量。在我们的例子中,我们的意图是通过去除“忽略”的像素并将交叉熵计算限制在感兴趣的像素上来减少计算量。显然,这种做法失败了。与之前一样,在应用布尔掩码时会得到一个大小不确定的张量,并且它触发的cudaMempyAsync远远超过了从排除“忽略”像素中节省下来的任何开销。
优化 #3:小心布尔掩码操作
在我们的例子中,修复这个问题相当简单,因为PyTorch的CrossEntropyLoss内置了一个设置ignore_index的选项。
class MaskedLoss(nn.Module): def __init__(self, ignore_val=-1, num_classes=10): super().__init__() self.ignore_val = ignore_val self.num_classes = num_classes self.loss = torch.nn.CrossEntropyLoss(ignore_index=-1) def cross_entropy(self, pred: Tensor, target: Tensor) -> Tensor: with torch.profiler.record_function('calc loss'): loss = self.loss(pred, target) return loss在下面的图片中,我们展示了结果的Trace View:

天啊!!我们的步时已经降到了5.4毫秒。这比我们开始时快了240倍。通过简单地改变几个函数调用,而不对损失函数逻辑进行任何修改,我们能够显著优化训练步骤的性能。
重要说明:在我们选择的示例中,我们采取的减少cudaMempyAsync事件的步骤对训练步骤时间产生了明显影响。然而,在某些情况下,相同类型的更改可能会损害性能而不是改善性能。例如,在布尔掩码的情况下,如果我们的掩码非常稀疏,原始张量非常大,则应用掩码的计算节省可能超过主机-设备同步的代价。重要的是,每个优化的影响都应该根据具体情况进行评估。
总结
本文主要讨论了由主机-设备同步事件引起的训练应用程序性能问题。我们展示了几个触发此类事件的PyTorch运算符的示例,它们的共同特点是它们输出的张量大小取决于输入。您可能还会遇到其他未在本文中涵盖的运算符引起的同步事件。我们演示了如何使用PyTorch Profiler及其相关的TensorBoard插件来识别这类事件。
在我们的玩具例子中,我们能够找到等效的替代方法来使用固定大小的张量,避免了同步事件的需要。这些改进大大提高了训练时间。然而,在实践中,你可能会发现解决这些瓶颈要困难得多,甚至是不可能的。有时候,克服这些问题可能需要重新设计模型的部分。