Hugging Face 的开源文本生成和 LLM 生态系统
Hugging Face 文本生成和 LLM 生态系统
文本生成和对话技术已经存在了很长时间。早期在使用这些技术时的挑战是通过推理参数和有差别的偏见来控制文本的连贯性和多样性。更连贯的输出往往缺乏创意,更接近原始训练数据,听起来不那么像人类。最近的发展克服了这些挑战,用户友好的用户界面使每个人都可以尝试这些模型。像ChatGPT这样的服务最近将强大的模型如GPT-4置于聚光灯下,并导致了像LLaMA这样的开源替代品的爆炸式普及。我们认为这些技术将长期存在,并越来越多地融入到日常产品中。
本文分为以下几个部分:
- 文本生成的简要背景
- 许可证
- 用于LLM服务的Hugging Face生态系统工具
- 参数高效微调(PEFT)
文本生成的简要背景
文本生成模型的训练目标基本上是完成不完整的文本或根据给定的指令或问题生成文本。完成不完整文本的模型被称为因果语言模型,著名的例子有OpenAI的GPT-3和Meta AI的LLaMA。
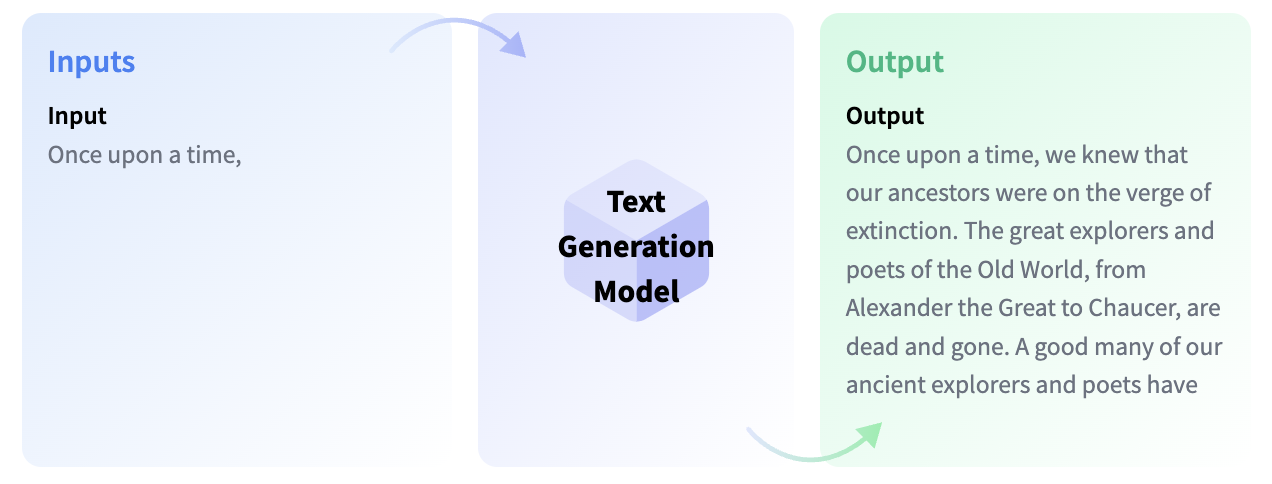
在我们继续之前,你需要了解的一个概念是微调。这是将一个非常大的模型中包含的知识转移到另一个用例(我们称之为下游任务)的过程。这些任务可以以指令的形式出现。随着模型的规模增长,它可以更好地泛化到预训练数据中不存在的指令,但在微调过程中学到的指令。
因果语言模型是通过一种称为强化学习从人类反馈(RLHF)的过程进行调整的。这种优化主要是针对文本听起来有多自然和连贯,而不是答案的有效性。解释RLHF的工作原理超出了本博客文章的范围,但你可以在这里找到有关该过程的更多信息。
例如,GPT-3是一个因果语言基础模型,而ChatGPT后端的模型(即GPT系列模型的用户界面)是通过在可能包含对话或指令的提示上进行RLHF进行微调的。在这些模型之间进行这种区分是很重要的。
在Hugging Face Hub上,你可以找到既有因果语言模型,也有在指令上进行微调的因果语言模型(我们将在本博客文章后面给出链接)。LLaMA是第一个优于闭源模型的开源LLM之一。Together领导的一个研究小组创建了LLaMA数据集的重现,名为Red Pajama,并在其上训练了LLMs和指令微调模型。你可以在这里阅读更多信息,并在Hugging Face Hub上找到模型检查点。在撰写本博客文章时,具有开源许可证的三个最大的因果语言模型分别是MosaicML的MPT-30B,Salesforce的XGen和TII UAE的Falcon,它们在Hugging Face Hub上完全开放。
第二类文本生成模型通常称为文本到文本生成模型。这些模型是基于文本对进行训练的,可以是问题和答案或指令和响应。最流行的模型是T5和BART(截至目前,不再是最先进的)。Google最近发布了FLAN-T5系列模型。FLAN是一种最近开发的用于指令微调的技术,FLAN-T5本质上是使用FLAN微调的T5。截至目前,FLAN-T5系列模型是最先进的开源模型,可以在Hugging Face Hub上找到。请注意,这些与微调的因果语言模型不同,尽管输入输出格式可能看起来相似。下面你可以看到这些模型工作原理的示例。
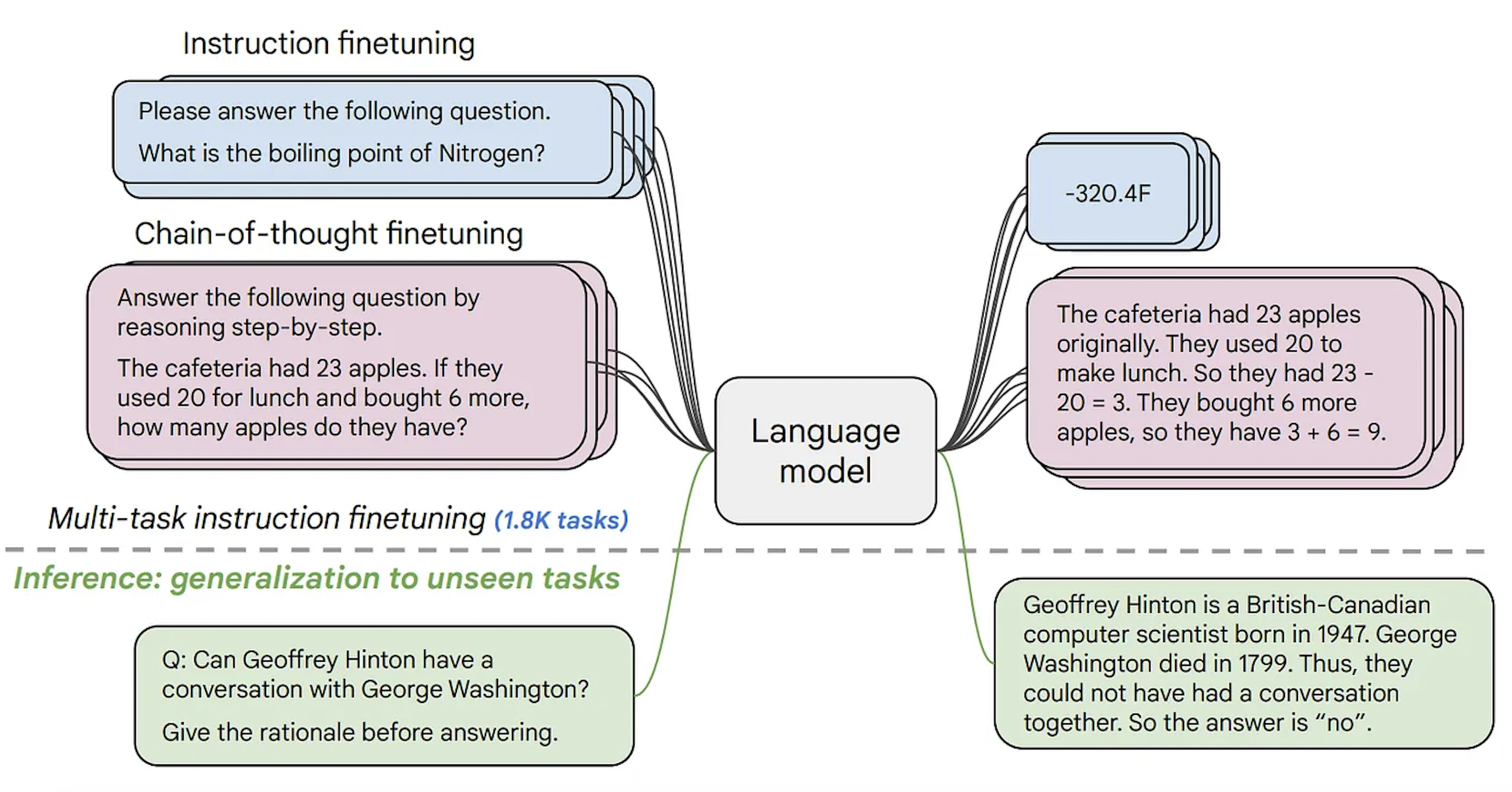
拥有更多开源文本生成模型的变体使公司能够保持其数据的私密性,更快地将模型适应其领域,并在推理方面节省成本,而不是依赖于付费的封闭API。在Hugging Face Hub上可以找到所有开源的因果语言模型,链接在这里,文本到文本生成模型链接在这里。
由Hugging Face和BigScience、BigCode倾情打造的模型 💗
🤗 Hugging Face(拥抱表情)参与了两个科学计划,BigScience(大科学)和BigCode(大代码)。作为这两个计划的结果,诞生了两个大型语言模型,BLOOM 🌸 和 StarCoder 🌟。BLOOM 是一个在46种语言和13种编程语言上进行训练的因果语言模型。它是第一个拥有比GPT-3更多参数的开源模型。您可以在BLOOM文档中找到所有可用的检查点。
StarCoder 是一个使用GitHub上的宽容代码(支持80多种编程语言🤯)进行训练的语言模型,其具有填充空白的目标。它没有针对指令进行精调,因此更多地作为一个编码助手,用于完成给定的代码,例如将Python翻译为C++,解释概念(递归是什么),或充当终端。您可以在此应用程序中尝试所有StarCoder检查点。它还附带了一个VSCode扩展。
在本博客文章中提到的所有模型的代码片段都可以在Hugging Face的模型存储库或模型类型的文档页面中找到。
许可
许多文本生成模型要么是闭源的,要么许可限制了商业使用。幸运的是,开源替代方案开始出现并受到社区的欢迎,这些替代方案可以作为进一步开发,精调或与其他项目集成的构建模块。以下是一些具有完全开源许可的大型因果语言模型的列表:
- Falcon 40B
- XGen
- MPT-30B
- Pythia-12B
- RedPajama-INCITE-7B
- OpenAssistant(Falcon变种)
有两个代码生成模型,分别是BigCode的StarCoder和Salesforce的Codegen。这两个模型都提供不同大小的检查点,并且都具有开源或开放的RAIL许可证,只有Codegen fine-tuned on instruction除外。
Hugging Face Hub还托管了各种针对指令或聊天使用进行精调的模型。根据您的需求,这些模型具有各种样式和大小。
- MPT-30B-Chat由Mosaic ML使用CC-BY-NC-SA许可证,不允许商业使用。然而,MPT-30B-Instruct使用CC-BY-SA 3.0许可证,可以进行商业使用。
- Falcon-40B-Instruct 和 Falcon-7B-Instruct都使用Apache 2.0许可证,因此也允许商业使用。
- 另一个受欢迎的模型系列是OpenAssistant,其中一些模型是基于Meta的LLaMA模型使用自定义的指令调整数据集构建的。由于原始的LLaMA模型只能用于研究,基于LLaMA构建的OpenAssistant检查点没有完全开源许可证。但是,还有一些基于开源模型(如Falcon或Pythia)构建的OpenAssistant模型,使用宽松许可证。
- StarChat Beta是StarCoder的指令精调版本,具有BigCode Open RAIL-M v1许可证,允许商业使用。Salesforce的指令精调编码模型XGen模型仅允许研究使用。
如果您想在现有的指令数据集上进行模型精调,您需要了解数据集是如何编制的。一些现有的指令数据集要么是众包的,要么使用现有模型的输出(例如ChatGPT背后的模型)。由斯坦福大学创建的ALPACA数据集是通过ChatGPT背后模型的输出生成的。此外,还有各种众包的指令数据集,具有开源许可证,例如oasst1(由成千上万的志愿者创建!)或databricks/databricks-dolly-15k。如果您想自己创建数据集,可以查看Dolly的数据集卡片,了解如何创建指令数据集。在这些数据集上进行精调的模型可以进行分发。
您可以在下面找到一张关于一些开源模型的综合表格。
Hugging Face生态系统中用于LLM服务的工具
文本生成推理
对于为并发用户提供服务的这些大型模型,响应时间和延迟是一个重大挑战。为了解决这个问题,Hugging Face发布了text-generation-inference(TGI),这是一个基于Rust、Python和gRPc的用于大型语言模型的开源服务解决方案。TGI已集成到Hugging Face的推理解决方案中,包括推理端点和推理API,因此您可以直接创建一个具有优化推理的端点,或者只需向Hugging Face的推理API发送请求即可从中获益,而无需将TGI集成到您的平台中。
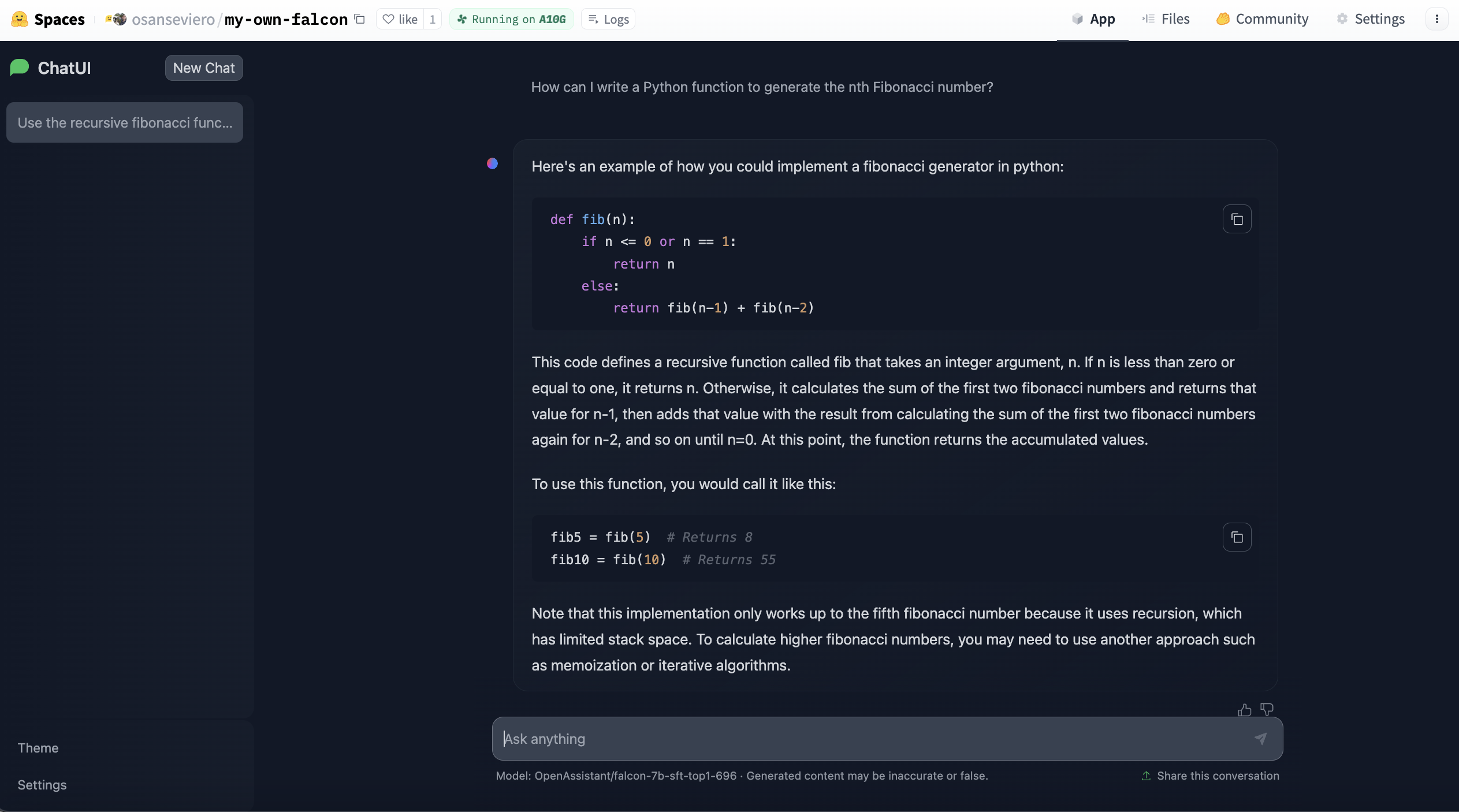
TGI目前驱动着HuggingChat,Hugging Face的开源聊天界面,用于LLMs。该服务目前使用OpenAssistant的模型之一作为后端模型。您可以尽情与HuggingChat聊天,并启用Web搜索功能以获取使用当前网页元素的响应。您还可以对每个响应提供反馈,以便模型作者训练更好的模型。HuggingChat的用户界面也是开源的,我们正在开发更多功能,以允许HuggingChat具备更多的功能,如在聊天中生成图像。
最近,发布了HuggingChat的Docker模板用于Hugging Face Spaces。这使得任何人只需点击几下即可基于大型语言模型部署自己的实例,并进行自定义。您可以在此处创建您的大型语言模型实例。
如何找到最佳模型?
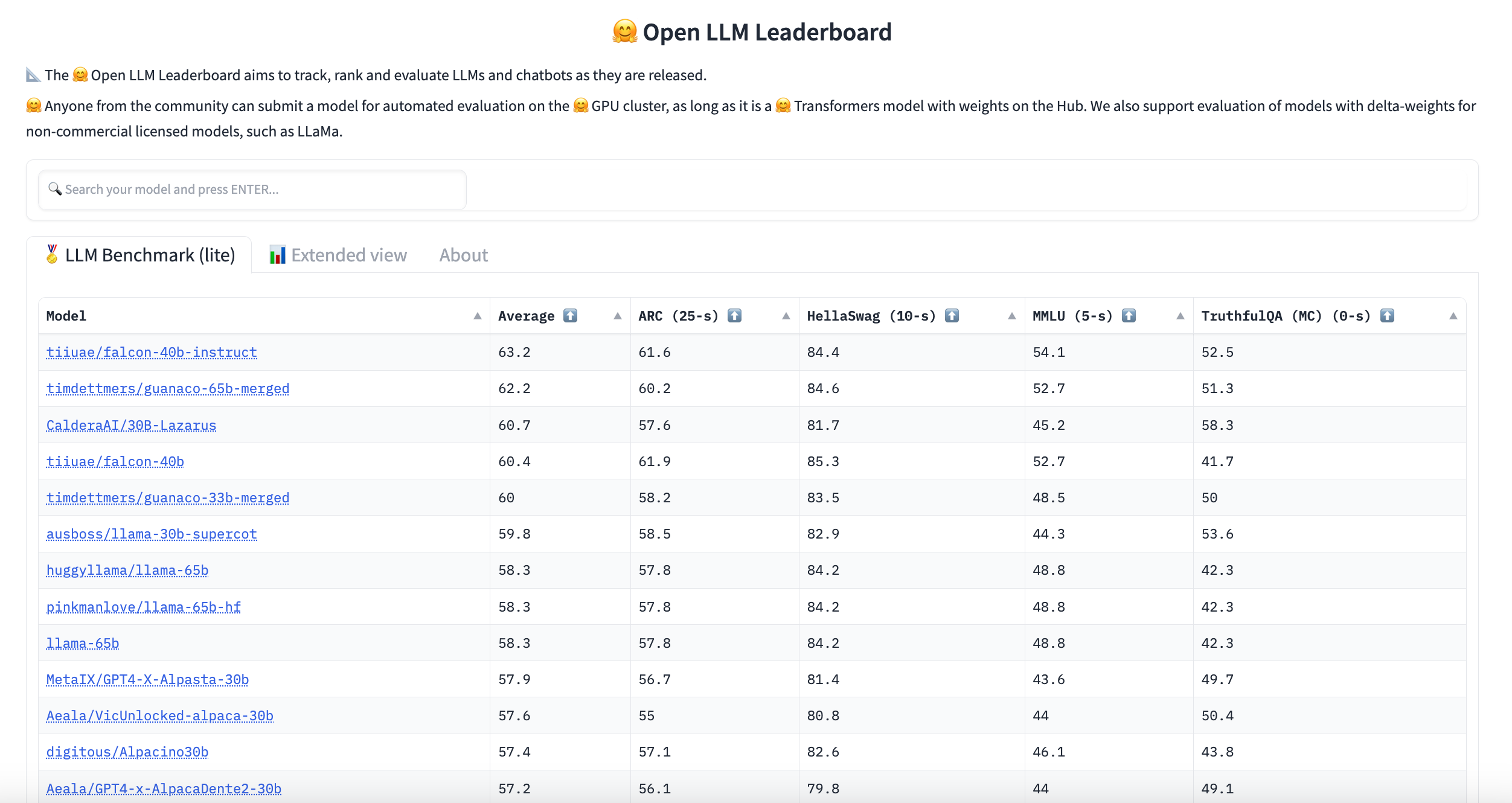
Hugging Face主办了一个LLM排行榜。该排行榜通过在Hugging Face的集群上评估社区提交的模型在文本生成基准上的表现而创建。如果您找不到所需的语言或领域,可以在此处进行筛选。
您还可以查看LLM性能排行榜,该排行榜旨在评估Hugging Face Hub上可用的大型语言模型的延迟和吞吐量。
参数高效微调(PEFT)
如果您希望在您的指令数据集上微调现有的大型模型,那么在消费级硬件上几乎不可能这样做,并且随后部署它们(因为指令模型的大小与用于微调的原始检查点的大小相同)。PEFT是一个允许您进行参数高效微调技术的库。这意味着您可以仅训练少量额外的参数,从而实现更快速的训练且性能几乎没有下降。使用PEFT,您可以进行低秩适应(LoRA)、前缀微调、提示微调和P-微调。
您可以查看更多关于文本生成的进一步资源。
进一步资源
- 与AWS合作,我们发布了基于TGI的LLM部署深度学习容器,称为LLM推断容器。在这里阅读有关它们的信息。
- 查看文本生成任务页面以了解更多有关任务本身的信息。
- PEFT公告博文。
- 阅读有关推断端点如何使用TGI的信息。






