AVIS内部:Google的新视觉信息搜索LLM
AVIS Internal Google's new visual information search LLM
新模型将LLMs与网络搜索、计算机视觉和图像搜索相结合,取得了显著的结果。

我最近开始了一个以人工智能为重点的教育性新闻简报,已经有超过16万名订阅者。TheSequence是一份没有废话(意思是没有炒作、没有新闻等)以机器学习为导向的简报,阅读只需5分钟。目标是让您了解机器学习项目、研究论文和概念的最新动态。请通过以下方式订阅,试一试:
TheSequence | Jesus Rodriguez | Substack
机器学习、人工智能和数据发展的最佳消息来源…
thesequence.substack.com
多模态是基础模型研究中最热门的领域之一。尽管像GPT-4这样的模型在多模态场景中展示了惊人的进展,但在这个领域仍然存在许多挑战。其中一个领域是需要外部知识来回答特定问题的视觉信息搜索任务。在题为“利用大型语言模型(LLMs)进行自主视觉信息搜索”的论文中,Google研究介绍了一种新颖的方法,该方法在寻找视觉信息相关任务中取得了有趣的结果。该方法将LLMs与三个不同类别的工具集成:1)利用计算机视觉工具从图像中提取视觉数据。2)利用网络搜索工具从更广泛的开放世界知识和事实中检索信息。3)利用图像搜索工具从与图像相关的元数据中提取相关详细信息。这三者的结合结果是一种技术,其中包括一个由LLM驱动的规划器来确定每个步骤的合适工具和查询。此外,还使用了一个由LLM驱动的推理器来审查工具的输出并提取关键见解。在整个过程中,一个功能性的记忆模块保留和保存信息。
一些背景
Google AVIS的理念源于最近的研究领域。近期的探索,如Chameleon、ViperGPT和MM-ReAct,专注于为多模态输入增强LLMs的辅助工具。这些系统分为两个阶段:规划阶段,将问题分解为结构化指令;执行阶段,使用工具来收集信息。尽管这种方法在基本任务中取得了成功,但在面对复杂的现实场景时往往失败。

人们还对将LLMs用作自主代理产生了越来越多的兴趣,如WebGPT和ReAct。这些代理与环境进行交互,根据实时反馈进行适应,并完成目标。然而,这些方法对各个阶段可以调用的工具的种类没有限制,导致搜索空间广泛。因此,即使是最先进的LLMs也可能陷入无限循环或传播错误。AVIS方法通过受用户研究人员决策影响的引导LLM应用来解决这个问题。
在像Infoseek和OK-VQA这样的数据集中,许多视觉查询甚至对人类回答者都提出了挑战,通常需要各种工具和API的帮助。为了了解在使用外部工具时人类决策的情况,进行了一项用户研究。
参与者使用与AVIS方法中使用的相同工具集进行装备,包括PALI、PaLM和网络搜索。他们得到输入图像、问题、裁剪的对象图像和链接到图像搜索结果的按钮。这些按钮提供了关于裁剪对象图像的各种信息,如知识图谱中的实体、相似图像标题、相关产品标题和相同图像描述。
用户的操作和输出被记录下来,并用作AVIS系统的参考,有两种重要的方式。首先,通过分析用户所做决策的顺序构建转换图。这个图将离散状态划分出来,并限制每个状态内可用的行动范围。例如,在初始状态下,系统只能进行三种操作:PALI标题、PALI VQA或对象检测。其次,利用人类决策的示例来引导AVIS系统中的规划器和推理器,为它们提供相关的上下文实例,以提高性能和效果。
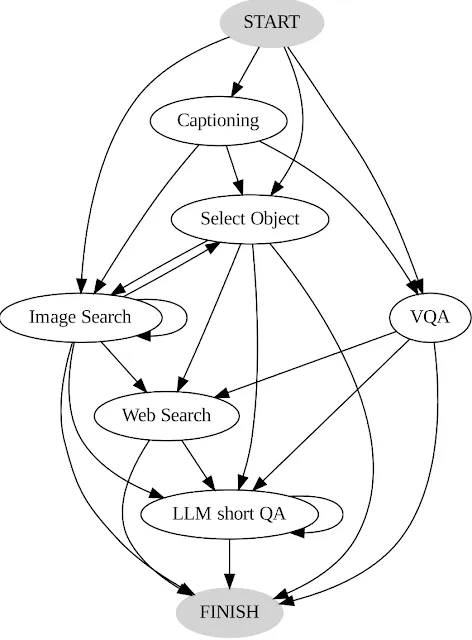
AVIS内部
在AVIS中,Google研究采用了一种动态决策方法,专门针对涉及寻求视觉信息的查询。该方法包括系统架构中的三个基本组件。1)首先,规划器接管控制权,解读后续的行动方案,包括适当的API调用和相应的查询处理。2)同时,工作内存模块被设置,勤奋地保存与API执行产生的结果相关的数据。3)最后,推理器扮演关键角色,筛选API调用生成的结果。该角色包括评估所获取的信息是否足够有价值以提供明确的响应,或者是否需要进一步的数据检索。
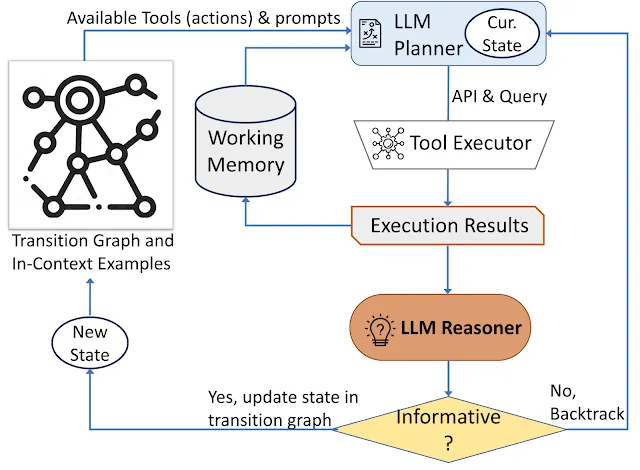
规划器在决定选择工具和相应查询进行调度时,会执行一系列步骤。根据当前状态,规划器展开一系列可能的行动。潜在行动的广度可能会变得难以控制,从而给搜索空间带来挑战。为了解决这个难题,规划器参考一个转换图,排除了不相关的行动。之前执行并存储在工作内存中的行动也被排除。
随后,规划器根据先前由人类参与者在用户研究期间做出的判断,组合一系列相关的语境实例。凭借这些实例和存储在工作内存中的数据,规划器构建一个提示。然后,该提示被传送给LLM,LLM提供结构化响应。该输出决定了随后要激活的工具和相关的查询。这个蓝图使得规划器在整个过程中可以被反复触发,从而实现逐步导向解决初始查询的动态决策。
推理器进入战场,分析工具执行的结果。它获取宝贵的见解,并确定工具输出所属的类别:信息性的、无信息的或最终响应。该技术依赖于LLM和适当的提示以及上下文实例来进行推理任务。如果推理器确认准备好提供响应,它将相应地发出明确的回复,从而结束任务。在工具输出为空的情况下,推理器将由规划器选择一个基于现有状态的替代行动。如果工具输出有见解,推理器会组织状态转换,并恢复规划器的权威,促使基于新状态的新决策。
结果
正如预期的那样,Google在不同的视觉信息查询基准上评估了AVIS,如Infoseek和OK-VQA数据集。结果令人难以置信,甚至在没有微调的情况下,准确率超过了50%。

AVIS研究将不同的思想融合到一种新颖的视觉信息查询模型框架中。如果我们看到AVIS被纳入Google发布的新一波多模式基础模型中,不要感到惊讶。





