用Amazon Comprehend自定义分类构建一个分类流水线(第一部分)
Amazon Comprehend自定义分类构建分类流水线(第一部分)
“数据被锁定在文本、音频、社交媒体和其他非结构化来源中,如果企业能够找到如何使用它的方法,这将成为它们的竞争优势”
根据德勤(Deloitte)2019年的一项调查,仅有18%的组织能够利用非结构化数据。大多数数据(80%至90%之间)都是非结构化数据。这是一个巨大的未开发资源,如果企业能够找到如何使用它,有潜力为其提供竞争优势。从这些数据中找到洞见可能很困难,特别是如果需要对其进行分类、标记或标签化。在这种情况下,亚马逊Comprehend自定义分类可能非常有用。亚马逊Comprehend是一种自然语言处理(NLP)服务,利用机器学习来揭示文本中有价值的洞见和联系。
文件分类或分类在各个业务领域都有显著的好处:
- 改进搜索和检索 – 通过将文件分类为相关主题或类别,用户可以更轻松地搜索和检索他们需要的文件。他们可以在特定类别内搜索以缩小结果范围。
- 知识管理 – 以系统的方式对文件进行分类有助于组织知识库。这样可以更容易地找到相关信息,并看到相关内容之间的联系。
- 流程优化 – 自动文档排序可以帮助优化许多业务流程,如处理发票、客户支持或合规性。文档可以自动路由到正确的人员或工作流程。
- 节约成本和时间 – 手动文档分类工作繁琐、耗时且昂贵。AI技术可以接管这项乏味的任务,并以较低的成本在短时间内对成千上万个文档进行分类。
- 洞察生成 – 分析文档类别的趋势可以提供有用的业务洞察。例如,某一产品类别中客户投诉的增加可能意味着需要解决一些问题。
- 治理和策略执行 – 设置文档分类规则有助于确保根据组织的政策和治理标准正确分类文档。这可以实现更好的监控和审计。
- 个性化体验 – 在网站内容等环境中,文档分类可以根据用户的兴趣和偏好(根据其浏览行为确定)显示定制内容。这可以增加用户参与度。
开发定制分类机器学习模型的复杂性因数据质量、算法、可扩展性和领域知识等多方面因素而异。开始时,明确定义问题、干净而相关的数据,并逐步完成模型开发的不同阶段非常重要。然而,企业可以使用亚马逊Comprehend自定义分类创建自己独特的机器学习模型,将文本文档自动分类到类别或标签中,以满足业务特定需求并与业务技术和文档类别相匹配。由于不再需要人工标记或分类,这可以为企业节省大量的时间、金钱和人力。我们通过自动化整个训练流程,使这个过程变得简单。
在本系列博客文章的第一部分中,您将了解如何创建一个可扩展的训练流程,并为Comprehend自定义分类模型准备训练数据。我们将介绍一个定制的分类器训练流程,可以在您的AWS账户中轻松部署。我们将使用BBC新闻数据集,并将训练一个分类器来识别文档所属的类别(例如政治、体育)。该流程将使您的组织能够快速响应变化,并在不必每次都从头开始的情况下训练新模型。您可以根据需求轻松扩展和训练多个模型。
先决条件
- 一个活跃的AWS账户(点击此处创建一个新的AWS账户)
- 访问亚马逊Comprehend、亚马逊S3、亚马逊Lambda、亚马逊Step Function、亚马逊SNS和亚马逊CloudFormation
- 准备好的训练数据(半结构化或文本)
- 对Python和机器学习有基本的了解
准备训练数据
该解决方案可以接受文本格式(例如CSV)或半结构化格式(例如PDF)的输入。
文本输入
Amazon Comprehend自定义分类支持两种模式:多类别和多标签。
在多类别模式下,每个文档只能分配一个类别。训练数据应准备为两列的CSV文件,文件的每一行包含一个类别和一个演示该类别的文档的文本。
类别,文档1的文本
类别,文档2的文本
...以BBC新闻数据集为例:
商业,欧洲指责美国造成美元贬值...
科技,出租车收集了大量手机...
...在多标签模式下,每个文档至少有一个类别被分配给它,但也可以有更多。训练数据应该是一个包含两列的CSV文件,文件的每一行包含一个或多个类别和训练文档的文本。使用分隔符来指示多个类别。
类别,文档1的文本
类别|类别|类别,文档2的文本
...CSV文件中不应包含任何标题。
半结构化输入
从2023年开始,Amazon Comprehend现在支持使用半结构化文档训练模型。半结构化输入的训练数据由一组标记的文档组成,这些文档可以是您已经有访问权限的文档存储库中的预识别文档。以下是用于训练的注释文件CSV数据的示例(示例数据):
类别,文档1.pdf,1
类别,文档1.pdf,2
...注释的CSV文件包含三列:第一列包含文档的标签,第二列是文档名称(即文件名),最后一列是要包含在训练数据集中的文档的页码。在大多数情况下,如果注释的CSV文件位于与所有其他文档相同的文件夹中,则只需在第二列中指定文档名称。但是,如果CSV文件位于不同的位置,则需要在第二列中指定路径,例如 path/to/prefix/document1.pdf。
有关如何准备训练数据的详细信息,请参考此处。
解决方案概述

- Amazon Comprehend训练流程在将训练数据(用于文本输入的.csv文件和用于半结构化输入的注释.csv文件)上传到专用的Amazon Simple Storage Service(Amazon S3)存储桶时开始。
- Amazon S3触发器会调用AWS Lambda函数,以便每次将对象上传到指定的Amazon S3位置时,AWS Lambda函数都会检索上传对象的源存储桶名称和键名称,并将其传递给训练步骤函数工作流。
- 在训练步骤函数中,接收到训练数据存储桶名称和对象键名称作为输入参数后,自定义模型训练工作流会作为一系列的Lambda函数启动,具体如下所述:
StartComprehendTraining:此AWS Lambda函数根据输入文件的类型(即文本或半结构化)定义一个ComprehendClassifier对象,然后通过调用create_document_classifier应用程序编程接口(API)启动Amazon Comprehend自定义分类训练任务,该API返回一个训练作业Amazon资源名称(ARN)。随后,此函数通过调用describe_document_classifier API来检查训练作业的状态。最后,它将训练作业ARN和作业状态作为输出返回给训练工作流的下一个阶段。GetTrainingJobStatus:此AWS Lambda函数每隔15分钟调用一次describe_document_classifier API来检查训练作业的状态,直到训练作业状态变为完成或失败。GenerateMultiClass或GenerateMultiLabel:如果在启动堆栈时选择了性能报告的是,则这两个AWS Lambda函数之一将根据您的Amazon Comprehend模型输出运行分析,生成每个类别的性能分析并将其保存到Amazon S3中。GenerateMultiClass:如果您的输入是多类别并且在性能报告中选择了是,则将调用此AWS Lambda函数。GenerateMultiLabel:如果您的输入是多标签并且在性能报告中选择了是,则将调用此AWS Lambda函数。
- 一旦训练成功完成,解决方案将生成以下输出:
- 自定义分类模型:您的账户中将有一个已训练模型的ARN,供未来的推理工作使用。
- 混淆矩阵[可选]:根据用户选择,混淆矩阵(
confusion_matrix.json)将在用户定义的输出Amazon S3路径中可用。 - Amazon Simple Notification Service通知[可选]:根据初始用户选择,将向订阅者发送有关训练作业状态的通知电子邮件。
步骤
启动解决方案
要部署您的流水线,请完成以下步骤:
- 选择启动堆栈按钮:

- 选择下一步
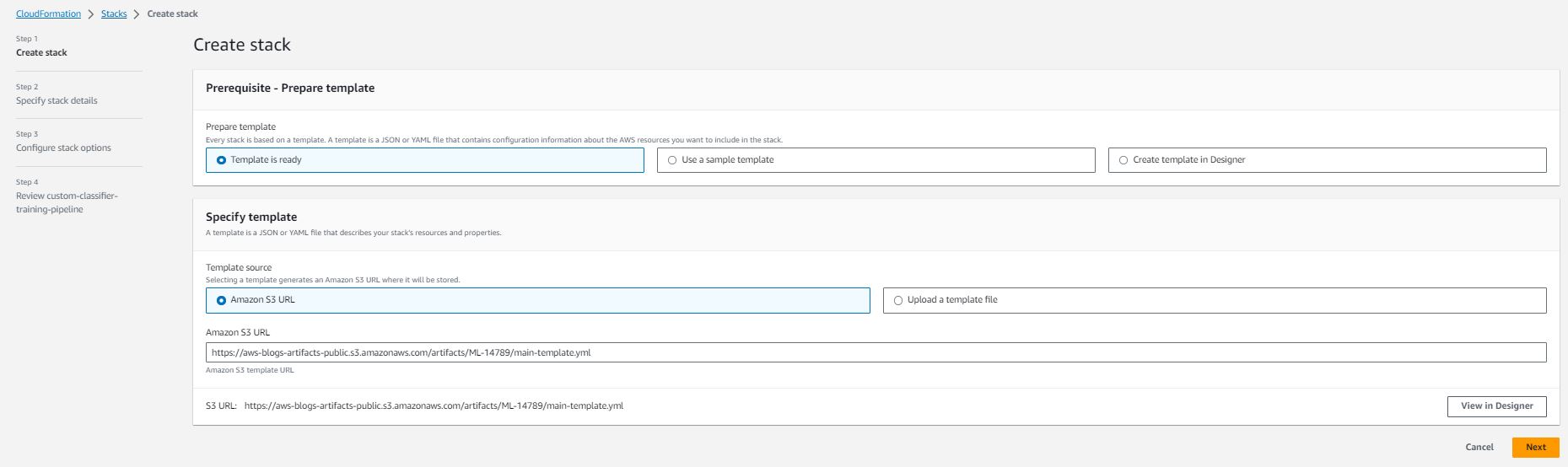
- 根据适用于您的用例的选项指定流水线详细信息:
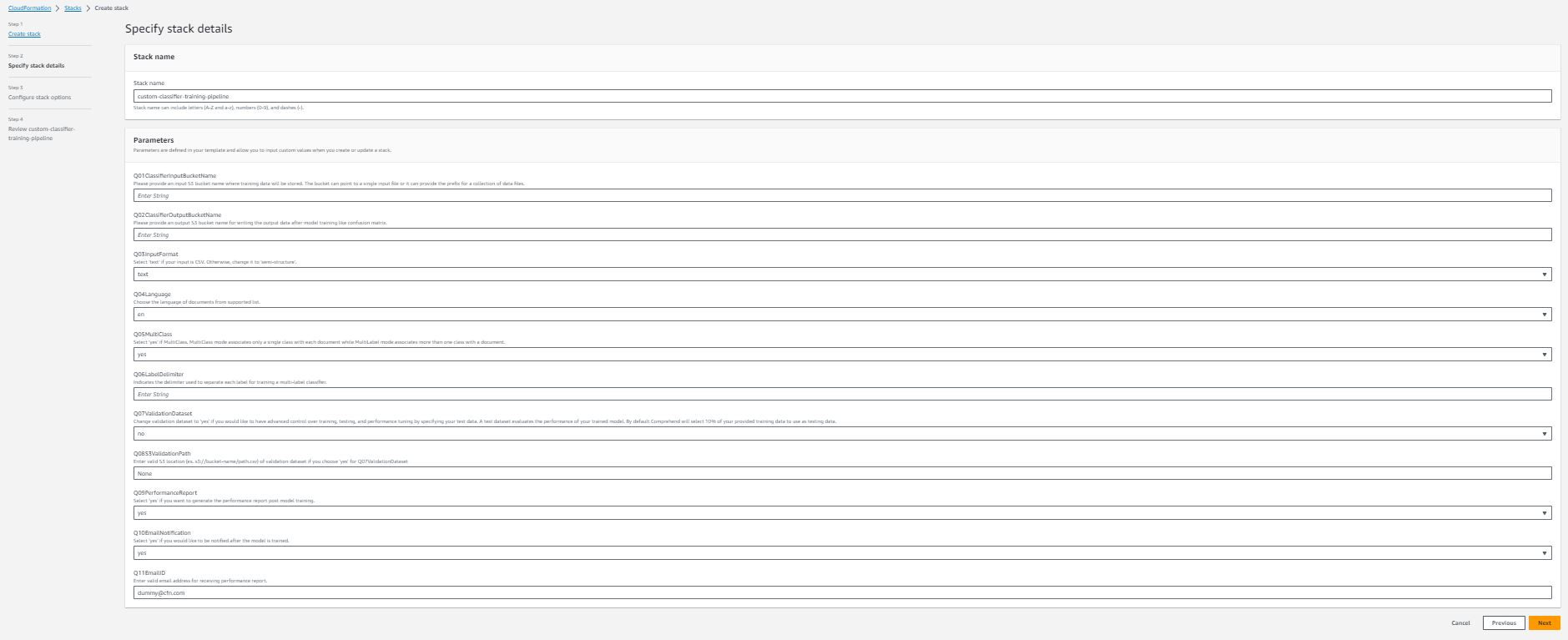
每个堆栈详细信息的说明:
- 堆栈名称(必填) – 您为此AWS CloudFormation堆栈指定的名称。该名称在您创建它的区域中必须是唯一的。
- Q01分类器输入存储桶名称(必填) – 存储输入数据的Amazon S3存储桶名称。它应该是一个全局唯一的名称,AWS CloudFormation堆栈在启动时帮助您创建存储桶。
- Q02分类器输出存储桶名称(必填) – 存储来自Amazon Comprehend和流水线的输出的Amazon S3存储桶名称。它也应该是一个全局唯一的名称。
- Q03输入格式 – 下拉选择,您可以根据数据输入格式选择文本(如果您的训练数据是csv文件)或半结构(如果您的训练数据是半结构[例如,PDF文件])。
- Q04语言 – 下拉选择,选择受支持列表中的文档语言。请注意,如果输入格式为半结构,则目前仅支持英语。
- Q05多类别 – 下拉选择,如果您的输入是多类别模式,请选择是。否则,选择否。
- Q06标签分隔符 – 仅在您的Q05多类别答案为否时需要。此分隔符用于在训练数据中分隔每个类别。
- Q07验证数据集 – 下拉选择,如果您想要使用自己的测试数据测试训练分类器的性能,请将答案更改为是。
- Q08S3验证路径 – 仅在您的Q07验证数据集答案为是时需要。
- Q09性能报告 – 下拉选择,如果您想要在模型训练后生成类级性能报告,请选择是。报告将保存在您指定的Q02分类器输出存储桶中。
- Q10电子邮件通知 – 下拉选择。如果您想在模型训练完成后接收通知,请选择是。
- Q11电子邮件地址 – 输入有效的电子邮件地址以接收性能报告通知。请注意,在启动AWS CloudFormation堆栈后,您必须从您的电子邮件中确认订阅,然后才能在训练完成时接收通知。
- 在Amazon配置堆栈选项部分,添加可选的标签、权限和其他高级设置。
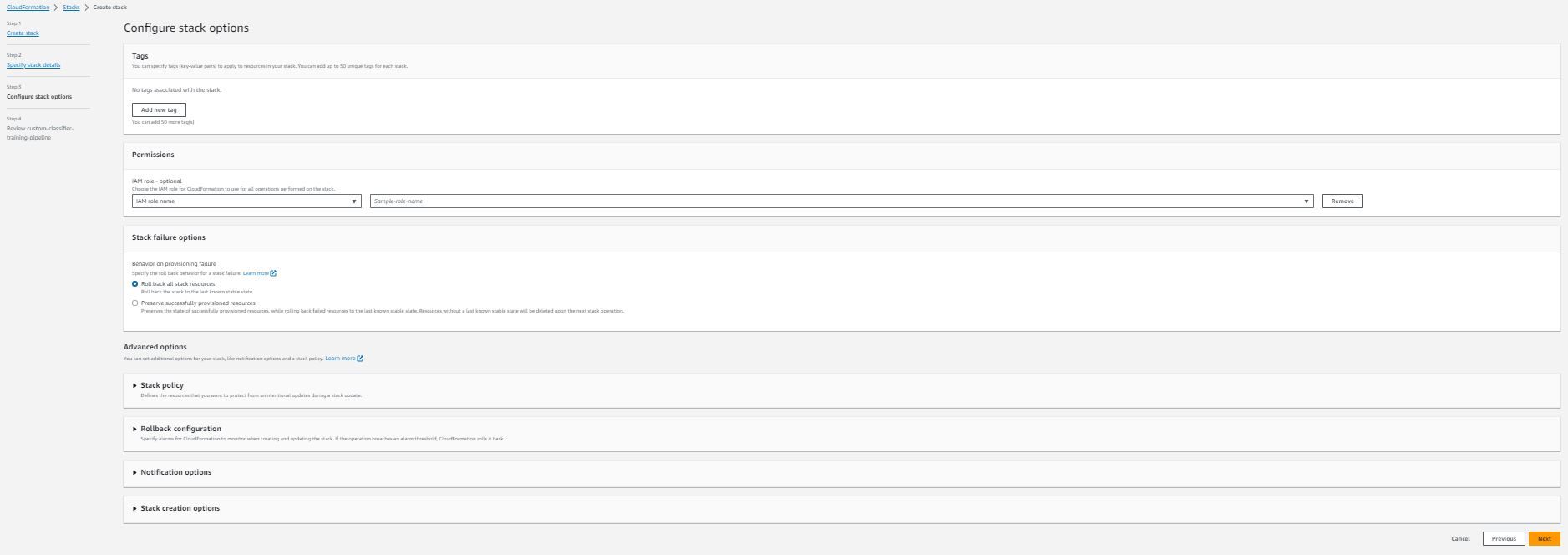
- 选择下一步
- 查看堆栈详细信息,并选择我确认AWS CloudFormation可能创建AWS IAM资源。
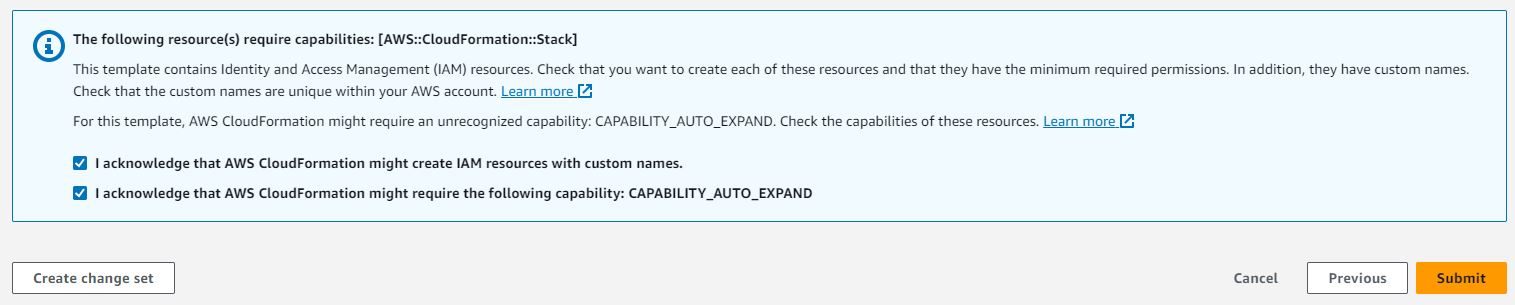
- 选择提交。这将在您的AWS账户中启动流水线部署。
- 堆栈成功部署后,您可以开始使用流水线。在指定的Amazon S3位置下创建一个
/training-data文件夹作为输入。注意:Amazon S3会自动对每个新对象应用服务器端加密(SSE-S3),除非您指定其他加密选项。有关Amazon S3中数据保护和加密的更多详细信息,请参阅Amazon S3中的数据保护。

- 将训练数据上传到文件夹中。(如果训练数据是半结构化的,则在上传.csv格式的标签信息之前,请先上传所有PDF文件)。
完成了!您已成功部署了流水线,并且可以在部署的步骤函数中检查流水线状态。(您将在Amazon Comprehend的自定义分类面板中拥有一个经过训练的模型)。

如果您在Amazon Comprehend控制台中选择了模型及其版本,则现在可以查看有关您刚刚训练的模型的更多详细信息。其中包括您选择的模式,对应于选项Q05MultiClass,标签数量以及训练数据中训练和测试文档的数量。您还可以在下面检查整体性能;但是,如果您想要检查每个类别的详细性能,请参阅部署流水线生成的性能报告。
服务配额
如果输入数据为半结构化格式,则您的AWS账户具有Amazon Comprehend和AmazonTextract的默认配额。要查看服务配额,请参阅Amazon Comprehend的此处和AmazonTextract的此处。
清理
为了避免产生持续的费用,请在完成后删除您创建的资源。
- 在Amazon S3控制台中,手动删除为输入和输出数据创建的存储桶中的内容。
- 在AWS CloudFormation控制台中,选择导航窗格中的堆栈。
- 选择主堆栈,然后选择删除。
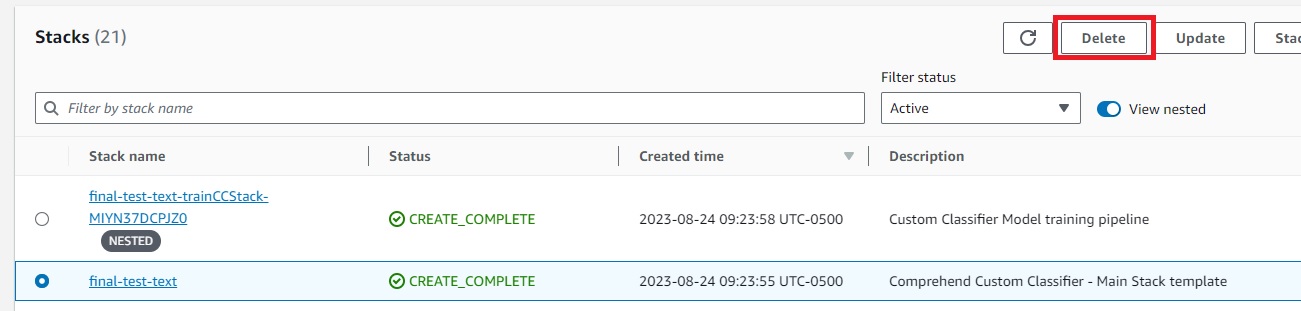
这将自动删除已部署的堆栈。
- 您训练的Amazon Comprehend自定义分类模型将保留在您的账户中。如果您不再需要它,请在Amazon Comprehend控制台中删除已创建的模型。
结论
在本文中,我们向您展示了针对Amazon Comprehend自定义分类模型的可扩展训练流水线的概念,并提供了一种自动化解决方案,以高效地训练新模型。所提供的AWS CloudFormation模板使您能够轻松创建自己的文本分类模型,以满足需求的扩展。该解决方案采用了最近发布的Euclid功能,并接受文本或半结构化格式的输入。
现在,我们鼓励您,我们的读者,测试这些工具。您可以找到有关训练数据准备和了解自定义分类器指标的更多详细信息。试用一下,亲自体验它如何简化您的模型训练过程并提高效率。请将您的反馈分享给我们!