如何生成文本:使用不同的解码方法与变形器进行语言生成
文本生成:使用不同的解码方法与变形器
![]()
介绍
近年来,由于大型基于Transformer的语言模型在数百万个网页上进行训练,如OpenAI著名的GPT2模型,开放式语言生成引起了越来越多的关注。在条件开放式语言生成方面取得了令人印象深刻的结果,例如独角兽上的GPT2,XLNet,使用CTRL进行的受控语言生成等等。除了改进的Transformer架构和大规模无监督训练数据外,更好的解码方法也起到了重要作用。
本博客文章简要概述了不同的解码策略,并且更重要的是展示了如何使用广受欢迎的transformers库轻松实现它们!
以下所有功能都可以用于自回归的语言生成(这里是一个复习)。简而言之,自回归语言生成基于这样的假设:一个单词序列的概率分布可以分解为条件下一个单词分布的乘积:
P(w1:T∣W0)=∏t=1TP(wt∣w1:t−1,W0) ,其中 w1:0=∅, P(w_{1:T} | W_0 ) = \prod_{t=1}^T P(w_{t} | w_{1: t-1}, W_0) \text{ ,其中 } w_{1: 0} = \emptyset, P(w1:T∣W0)=t=1∏TP(wt∣w1:t−1,W0) ,其中 w1:0=∅,
并且 W0W_0W0 是初始上下文单词序列。单词序列的长度TTT通常是根据需要确定的,并且对应于时间步t=Tt=Tt=T时,通过P(wt∣w1:t−1,W0)P(w_{t} | w_{1: t-1}, W_{0})P(wt∣w1:t−1,W0)生成EOS令牌。
自回归语言生成现在适用于PyTorch和Tensorflow >= 2.0中的GPT2,XLNet,OpenAi-GPT,CTRL,TransfoXL,XLM,Bart,T5!
我们将介绍目前最突出的解码方法,主要包括贪婪搜索、Beam搜索、Top-K采样和Top-p采样。
让我们快速安装transformers并加载模型。我们将使用Tensorflow 2.1中的GPT2进行演示,但API对于PyTorch来说是一对一相同的。
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q tensorflow==2.1
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# 将EOS令牌添加为PAD令牌以避免警告
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)贪婪搜索
贪婪搜索只是选择具有最高概率的单词作为下一个单词:wt=argmaxwP(w∣w1:t−1)w_t = argmax_{w}P(w | w_{1:t-1})wt=argmaxwP(w∣w1:t−1) 在每个时间步ttt。以下示意图显示了贪婪搜索。

从单词”The”\text{“The”},”The”开始,算法贪婪地选择最高概率的下一个单词”nice”\text{“nice”}”nice”,以此类推,最终生成的单词序列是(“The”,”nice”,”woman”)(\text{“The”}, \text{“nice”}, \text{“woman”})(“The”,”nice”,”woman”),总体概率为0.5×0.4=0.20.5 \times 0.4 = 0.20.5×0.4=0.2。
以下我们将使用GPT2在上下文(”我”,”喜欢”,”散步”,”和”,”我的”,”可爱”,”狗”)上生成单词序列(\text{“我”}, \text{“喜欢”}, \text{“散步”}, \text{“和”}, \text{“我的”}, \text{“可爱”}, \text{“狗”})(“我”,”喜欢”,”散步”,”和”,”我的”,”可爱”,”狗”)。让我们看看贪婪搜索如何在transformers中使用:
# 编码生成所依赖的上下文
input_ids = tokenizer.encode('我喜欢散步和我的可爱狗', return_tensors='tf')
# 生成文本,直到输出的长度(包括上下文的长度)达到50
greedy_output = model.generate(input_ids, max_length=50)
print("输出:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))太棒了!我们已经使用GPT2生成了我们的第一段短文😊。在上下文后面生成的单词是合理的,但是模型很快就开始重复自己了!这是语言生成中一个非常常见的问题,尤其是在贪婪搜索和束搜索中,可以参考Vijayakumar等人的2016年和Shao等人的2017年的研究。
贪婪搜索的主要缺点是它会错过隐藏在低概率词后面的高概率词,就像我们上面的草图中所展示的:
词语”has”\text{“has”}”has”具有0.90.90.9的高条件概率,但它被词语”dog”\text{“dog”}”dog”隐藏,”dog”只有第二高的条件概率,所以贪婪搜索错过了词序列”这只”,”狗”,”有”\text{“这只”}, \text{“狗”}, \text{“有”}”这只”,”狗”,”有”。
幸运的是,我们有束搜索来缓解这个问题!
束搜索
束搜索通过在每个时间步骤保留最有可能的num_beams个假设,最终选择具有最高总概率的假设,从而减少错过隐藏高概率词序列的风险。让我们用num_beams=2来说明:

在时间步骤1中,除了最有可能的假设(“这只”,”漂亮”)(\text{“这只”}, \text{“漂亮”})(“这只”,”漂亮”),束搜索还跟踪第二个最有可能的假设(“这只”,”狗”)(\text{“这只”}, \text{“狗”})(“这只”,”狗”)。在时间步骤2中,束搜索发现单词序列(“这只”,”狗”,”有”)(\text{“这只”}, \text{“狗”}, \text{“有”})(“这只”,”狗”,”有”)的概率(0.360.360.36)比(“这只”,”漂亮”,”女人”)(\text{“这只”}, \text{“漂亮”}, \text{“女人”})(“这只”,”漂亮”,”女人”)的概率(0.20.20.2)更高。太棒了,它找到了我们玩具样例中最有可能的单词序列!
束搜索总是能找到比贪婪搜索更高概率的输出序列,但不能保证找到最有可能的输出。
让我们看看如何在transformers中使用束搜索。我们设置num_beams > 1和early_stopping=True,这样当所有束搜索假设都达到EOS标记时,生成就结束了。
# 激活束搜索和early_stopping
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
print("输出:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))虽然结果可能更加流畅,但输出仍包含重复的相同单词序列。一个简单的解决办法是引入n-gram(即n个单词的单词序列)惩罚,通过将可能生成已经出现过的n-gram的下一个单词的概率手动设置为0来确保不会出现重复的n-gram。
让我们通过设置no_repeat_ngram_size=2来尝试一下,这样就不会出现重复的2-gram:
# 将 no_repeat_ngram_size 设置为 2
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print("输出:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))很好,看起来好多了!我们可以看到重复不再出现了。然而,n-gram惩罚必须慎重使用。生成关于纽约市的文章不应该使用2-gram惩罚,否则这个城市的名字在整篇文章中只会出现一次!
Beam搜索的另一个重要特性是,在生成后我们可以比较顶部的beam,然后选择最适合我们目的的生成beam。
在transformers中,我们只需要将参数num_return_sequences设置为应返回的得分最高的beam的数量。但请确保num_return_sequences <= num_beams!
# 设置 return_num_sequences > 1
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
# 现在我们有了3个输出序列
print("输出:\n" + 100 * '-')
for i, beam_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(beam_output, skip_special_tokens=True)))从结果可以看出,五个beam的假设之间只有微小的差异,这在使用只有5个beam的情况下并不令人意外。
在开放式生成中,最近提出了几个原因,解释为什么beam搜索可能不是最佳选择:
-
在机器翻译或摘要等任务中,Beam搜索可能效果非常好,因为期望生成的长度更或多或少可预测,参见Murray等人(2018)和Yang等人(2018)。但是,在开放式生成中,期望的输出长度可能变化很大,例如对话和故事生成。
-
我们已经看到,Beam搜索在生成重复内容时非常困难。在故事生成中,通过n-gram或其他惩罚项来找到强制“无重复”和重复循环相同n-gram之间的良好平衡需要进行大量微调。
-
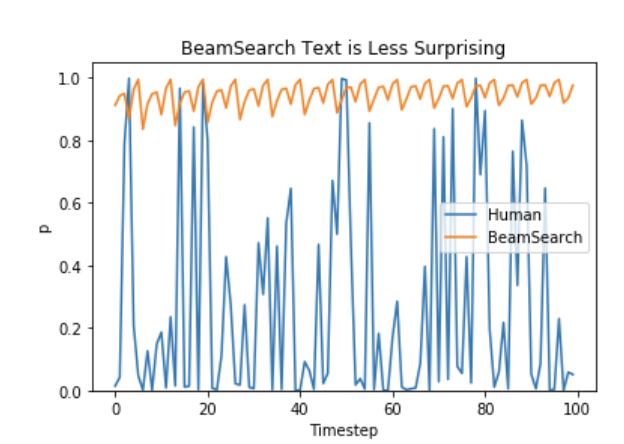
正如Ari Holtzman等人(2019)所指出的,高质量的人类语言不遵循高概率下一个词的分布。换句话说,作为人类,我们希望生成的文本能给我们带来惊喜,而不是无聊/可预测的。作者通过绘制模型对人类文本的概率和Beam搜索结果的概率来很好地展示了这一点。
所以让我们不再无聊,引入一些随机性 🤪。
采样
在最基本的形式中,采样意味着根据其条件概率分布随机选择下一个单词 wtw_twt:
wt∼P(w∣w1:t−1) w_t \sim P(w|w_{1:t-1}) wt∼P(w∣w1:t−1)
以前面的例子为例,下面的图形展示了使用采样进行语言生成的过程。

很明显,使用采样进行语言生成不再是确定性的。单词(“car”)(\text{“car”})(“car”)是从条件概率分布P(w∣”The”)P(w | \text{“The”})P(w∣”The”)中随机采样得到的,然后从P(w∣”The”,”car”)P(w | \text{“The”}, \text{“car”})P(w∣”The”,”car”)中采样得到(“drives”)(\text{“drives”})(“drives”)。
在transformers中,我们将do_sample=True并通过top_k=0关闭Top-K采样(稍后会详细介绍)。以下示例中我们设置random_seed=0用于说明目的。你可以随意更改random_seed以与模型进行交互。
# 设置种子以重现结果。可以随意更改种子以获得不同的结果
tf.random.set_seed(0)
# 通过将top_k采样设置为0,激活采样并停用top_k
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0
)
print("输出:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))有趣!文本看起来还不错,但仔细看,它并不是很连贯。”新手感”和”本地战斗”这两个3-gram是非常奇怪的,听起来不像是人类写的。这就是在采样词序列时的一个大问题:模型经常产生不连贯的胡言乱语,参见Ari Holtzman等人(2019)。
一个技巧是通过降低所谓的“温度”(temperature)来使分布P(w∣w1:t−1)P(w|w_{1:t-1})P(w∣w1:t−1)更加尖锐(增加高概率词的概率,降低低概率词的概率)。
上述示例应用温度的示意图如下所示。

第t=1步的条件下一个词分布变得更加尖锐,几乎没有机会选择词语”car”。
让我们看看如何通过将temperature=0.7来降低模型的输出分布:
# 设置种子以重现结果。可以随意更改种子以获得不同的结果
tf.random.set_seed(0)
# 使用温度来降低对低概率候选词的敏感性
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0,
temperature=0.7
)
print("输出:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))好了。奇怪的n-gram较少了,输出现在稍微连贯一些!尽管应用温度可以使分布不那么随机,但在其极限情况下,当temperature →0时,温度缩放采样变得等同于贪婪解码,并且会遇到与之前相同的问题。
Top-K采样
Fan et al.(2018)提出了一种简单但非常强大的采样方案,称为Top-K采样。在Top-K采样中,选择概率最高的K个候选词,并在这K个候选词中重新分配概率质量。GPT2采用了这种采样方案,这也是其在生成故事方面成功的原因之一。
我们将上述示例中用于两个采样步骤的单词范围从3个单词扩展到10个单词,以更好地说明Top-K采样。

在设置K=6的情况下,我们将采样池限制为6个单词。虽然在第一步中,最有可能的6个单词(定义为Vtop-KV_{\text{top-K}}Vtop-K)仅包含大约三分之二的整体概率质量,但在第二步中,它包含了几乎所有的概率质量。尽管如此,我们可以看到它成功消除了第二个采样步骤中的一些相当奇怪的候选词(“not”,“the”,“small”,“told”)。
让我们看看如何通过将top_k=50在库中使用Top-K采样:
# 设置种子以重现结果。可以随意更改种子以获得不同的结果
tf.random.set_seed(0)
# 将top_k设置为50
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50
)
print("输出:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))非常不错!这段文本可以说是迄今为止最接近人类风格的文本了。不过,Top-K采样的一个问题是它不会动态地调整从下一个词概率分布P(w∣w1:t−1)P(w|w_{1:t-1})P(w∣w1:t−1)中过滤的单词数量。这可能会导致一些单词从非常尖锐的分布中采样(图中右侧的分布),而其他单词则从更平坦的分布中采样(图中左侧的分布)。
在步骤 t=1t=1t=1 中,Top-K 消除了采样的可能性 (“people”,”big”,”house”,”cat”)(\text{“people”}, \text{“big”}, \text{“house”}, \text{“cat”})(“people”,”big”,”house”,”cat”),这些似乎是合理的候选词。另一方面,在步骤 t=2t=2t=2 中,该方法包括了不太合适的单词 (“down”,”a”)(\text{“down”}, \text{“a”})(“down”,”a”) 在词池中。因此,将采样池限制为固定大小 K 可能会使模型在尖峰分布中生成无意义的结果,并限制模型在平坦分布中的创造力。这种直觉导致 Ari Holtzman 等人于 2019 年创建了Top-p 或 nucleus 采样方法。
Top-p (nucleus) 采样
与仅从最可能的 K 个词中采样不同,Top-p 采样选择从累积概率超过概率 p 的可能性最小的词集中选择。然后,概率质量在这个词集中重新分配。这样,词集的大小(也就是词集中的词数)可以根据下一个词的概率分布动态增加和减少。好了,说得太多了,让我们来可视化一下。

设定 p=0.92p=0.92p=0.92,Top-p 采样选择超过概率质量的 p=92%p=92\%p=92% 的最小数量的词,定义为 Vtop-pV_{\text{top-p}}Vtop-p。在第一个例子中,这包括了最可能的 9 个词,而在第二个例子中只需要选择前 3 个词即可超过 92%。实际上非常简单!可以看到它在下一个词的可预测性较低的情况下保留了广泛的词汇范围,例如 P(w∣”The”)P(w | \text{“The”})P(w∣”The”),而在下一个词较可预测的情况下只保留了少量的词汇,例如 P(w∣”The”,”car”)P(w | \text{“The”}, \text{“car”})P(w∣”The”,”car”)。
好了,是时候在 transformers 中进行测试了!我们通过设置 0 < top_p < 1 来激活 Top-p 采样:
# 设置种子以重现结果。如果需要不同的结果,可以随意更改种子
tf.random.set_seed(0)
# 停用 top_k 采样,仅从最可能的 92% 词中采样
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=0
)
print("输出:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
输出:
----------------------------------------------------------------------------------------------------
我喜欢和我可爱的狗一起散步。他永远不会再是原来的样子。我看着他玩。
伙计们,我的狗需要一个名字。尤其是如果他有翅膀的话。
那是什么?我有很多太棒了,听起来好像是人类写的。嗯,或许还不够。
理论上,Top-p 似乎比 Top-K 更加优雅,但两种方法在实践中都效果很好。Top-p 也可以与 Top-K 结合使用,这可以避免排名较低的词,同时允许一些动态选择。
最后,要获取多个独立采样的输出,我们可以再次设置参数 num_return_sequences > 1:
# 设置种子以重现结果。如果需要不同的结果,可以随意更改种子
tf.random.set_seed(0)
# 设置 top_k = 50,设置 top_p = 0.95,num_return_sequences = 3
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)
print("输出:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
输出:
----------------------------------------------------------------------------------------------------
0: 我喜欢和我可爱的狗一起散步。有机会和狗一起散步真是太好了。但是我对狗有一个问题,他总是盯着我们看,总是试图让我看到我可以做些什么
1: 我喜欢和我可爱的狗一起散步,她喜欢去地球上不同的地方旅行,甚至在沙漠中也是如此!世界对我们来说还不够大,我们不能坐公交车和我们心爱的小狗一起旅行,但这就是我找到爱的地方
2: 我喜欢和我可爱的狗一起散步并与我们的孩子一起玩,"美国动物协会的主任大卫·J·史密斯说。
"所以,结果是,我在我的时间里多了很多工作,"他说。很棒,现在你应该拥有了使用transformers让你的模型写故事的所有工具!
结论
作为临时解码方法,top-p采样和top-K采样似乎比传统的贪婪搜索和束搜索在开放式语言生成中产生更流畅的文本。最近的证据表明,贪婪搜索和束搜索主要产生重复的单词序列的表面缺陷是由模型(尤其是模型的训练方式)引起的,而不是解码方法本身,具体参见Welleck等人(2019)。此外,正如Welleck等人(2020)所示,top-K采样和top-p采样似乎也会产生重复的单词序列。
在Welleck等人(2019)中,作者通过人工评估表明,当调整模型的训练目标时,束搜索可以生成比Top-p采样更流畅的文本。
开放式语言生成是一个快速发展的研究领域,通常情况下并没有一种适用于所有情况的方法,所以我们必须看看在特定用例中的最佳实践。
很幸运,你可以在transformers中尝试所有不同的解码方法🤗。
这是关于如何在transformers中使用不同解码方法和开放式语言生成的最新趋势的简短介绍。
欢迎在Github存储库上提供反馈和问题。
要获得更多有趣的故事生成,请参阅使用Transformers进行写作。
感谢所有为博客文章做出贡献的人:Alexander Rush,Julien Chaumand,Thomas Wolf,Victor Sanh,Sam Shleifer,Clément Delangue,Yacine Jernite,Oliver Åstrand和John de Wasseige。
附录
generate方法还有一些未在上述提到的附加参数。我们在这里简要解释一下!
-
min_length可以用于强制模型在达到min_length之前不生成EOS标记(即不完成句子)。这在摘要中经常使用,但在一般情况下如果用户希望有更长的输出也很有用。 -
repetition_penalty可以用于惩罚已经生成过的单词或属于上下文的单词。它最早由Keskar等人(2019)引入,并且也在Welleck等人(2019)的训练目标中使用。它在防止重复方面非常有效,但对于不同的模型和用例来说似乎非常敏感,例如参见Github上的讨论。 -
attention_mask可以用于屏蔽填充的标记 -
pad_token_id、bos_token_id、eos_token_id:如果模型默认没有这些标记,用户可以手动选择其他标记ID来表示它们。
更多信息,请参阅generate函数的文档字符串。