25,000台计算机如何训练ChatGPT
如何训练25,000台计算机的ChatGPT?
ChatGPT背后的突破

好的后面是什么词?
你可能会想到“早上好”或“再见”。但你绝对不会说“好吵”。这毫无意义。几十年来,计算机科学家一直在训练人工智能来解决这个确切的问题。

给定一个词,我们的人工智能预测下一个词。重复这个过程几次,你就生成了一个句子。
这就是ChatGPT的工作原理。
ChatGPT在整个互联网上进行了训练,已经学会了如何像人类一样聊天。然而,这一巨大成就只有在2010年代末期取得的突破下才变得可能。这一突破为ChatGPT打下了基础,并永远改变了我们所处的世界。
这是一部关于一个人工智能读取并从整个互联网上的每本书、推文和网站中学习的故事。以及它是如何成为可能的。
句子很长。
当我们超越单个词语时,下一个词的预测就变得更加困难。以这个例子为例。
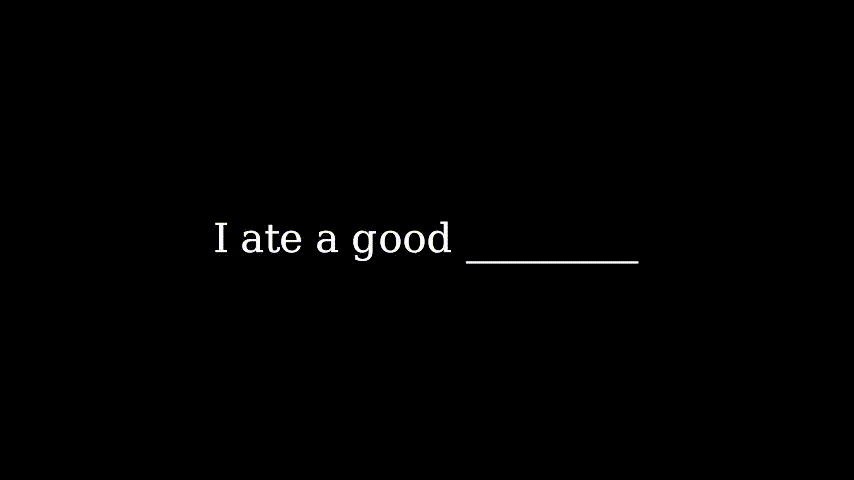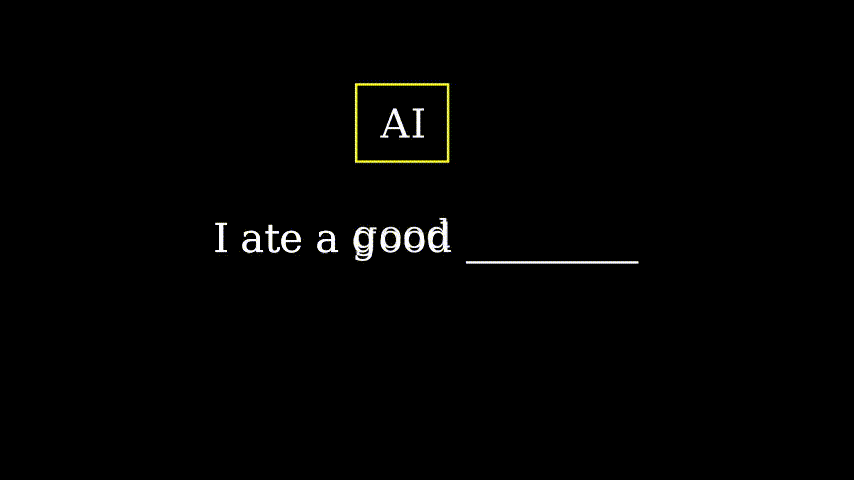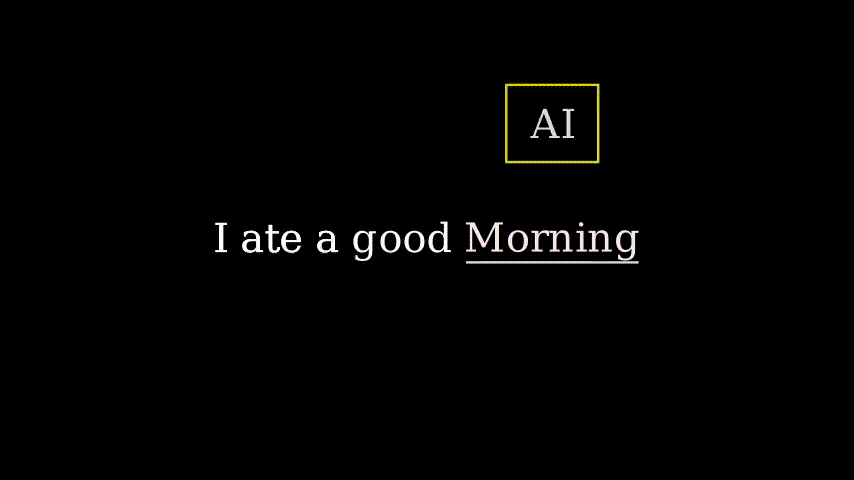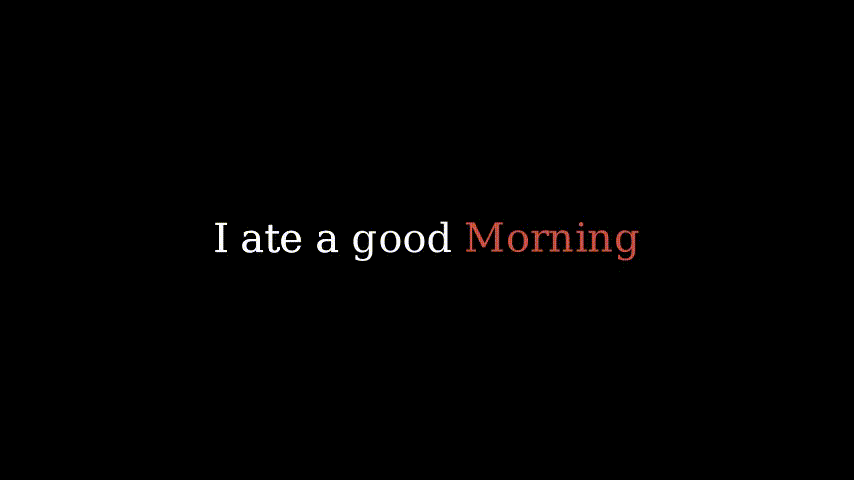
在这个上下文中,说“我吃了一个好早晨”是没有意义的。但我们的人工智能只看到了“好”,并输出了“早晨”。在大多数情况下,即使是人类也需要许多词语来预测下一个词语。因此,人工智能也需要这些额外信息。
我们的人工智能需要阅读许多词语来预测下一个词语。ChatGPT可以一次阅读超过8,000个先前的词语。自然的做法是将每个词语逐个输入到人工智能中。
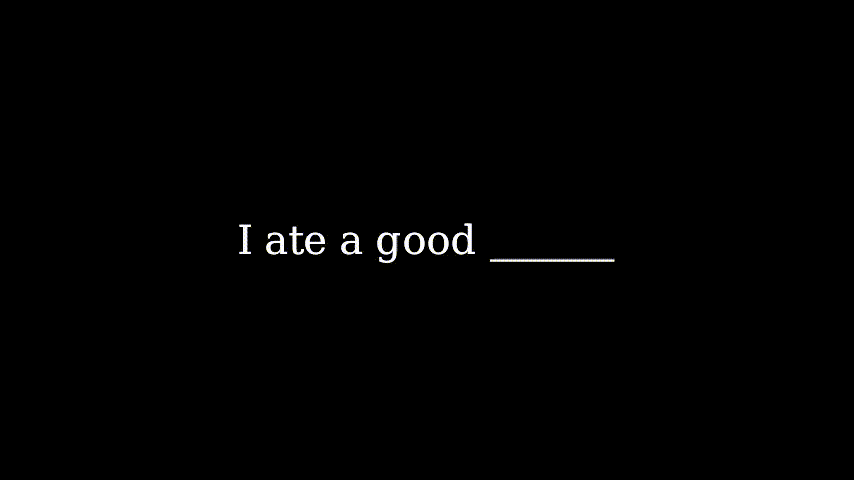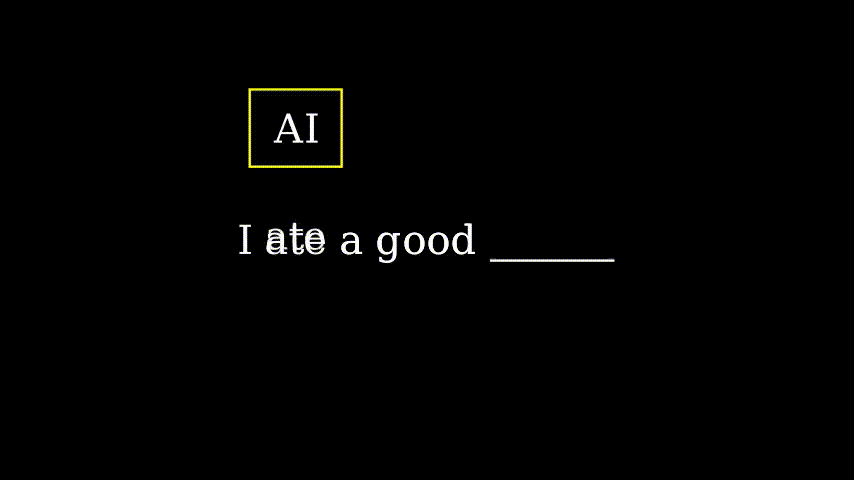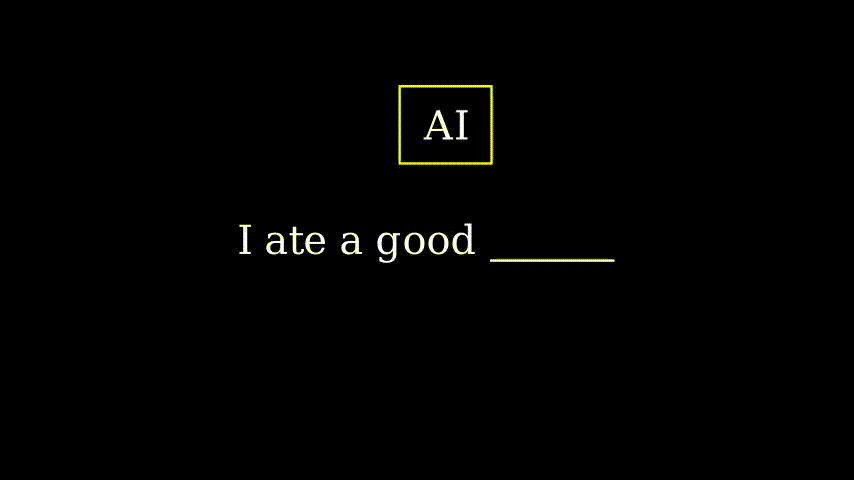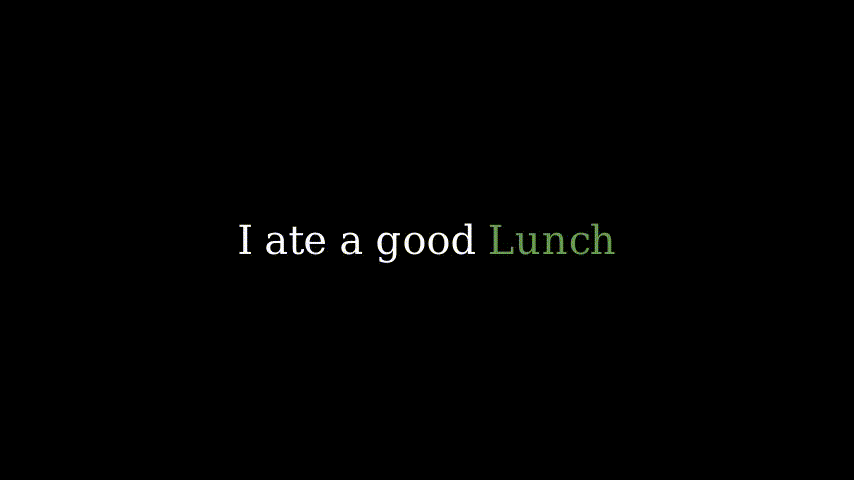
这是过去人工智能的工作方式。递归神经网络 (RNN) 会逐个接收一个词语…