扩散器的新功能有哪些?🎨
'What are the new functions of the diffuser? 🎨'
一个半月前,我们发布了 diffusers ,这是一个提供了跨模态扩散模型的模块化工具包的库。几周后,我们发布了对稳定扩散的支持,这是一个高质量的文本到图像模型,并提供了免费的演示供任何人尝试。除了消耗大量的GPU资源,最近三周团队决定为该库添加一两个新功能,希望社区能够喜欢!本博客文章将对 diffusers 0.3版本的新功能进行高级概述!记得给 GitHub 仓库点个 ⭐。
- 图像到图像流程
- 文本反转
- 修复
- 针对较小GPU的优化
- 在Mac上运行
- ONNX导出
- 新文档
- 社区
- 使用SD潜空间生成视频
- 模型可解释性
- 日语稳定扩散
- 高质量微调模型
- 稳定扩散的交叉注意力控制
- 可重复使用的种子
图像到图像流程
最多人要求的功能之一是图像到图像的生成。这个流程允许您输入一个图像和一个提示,然后它会基于此生成一个图像!
让我们看一下基于官方的 Colab 笔记本的代码。
from diffusers import StableDiffusionImg2ImgPipeline
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
)
# 下载初始图像
# ...
init_image = preprocess(init_img)
prompt = "一个奇幻的风景,在 artstation 上流行"
images = pipe(prompt=prompt, init_image=init_image, strength=0.75, guidance_scale=7.5, generator=generator)["sample"]没时间写代码?没问题,我们还创建了一个 Space 演示,您可以直接尝试。
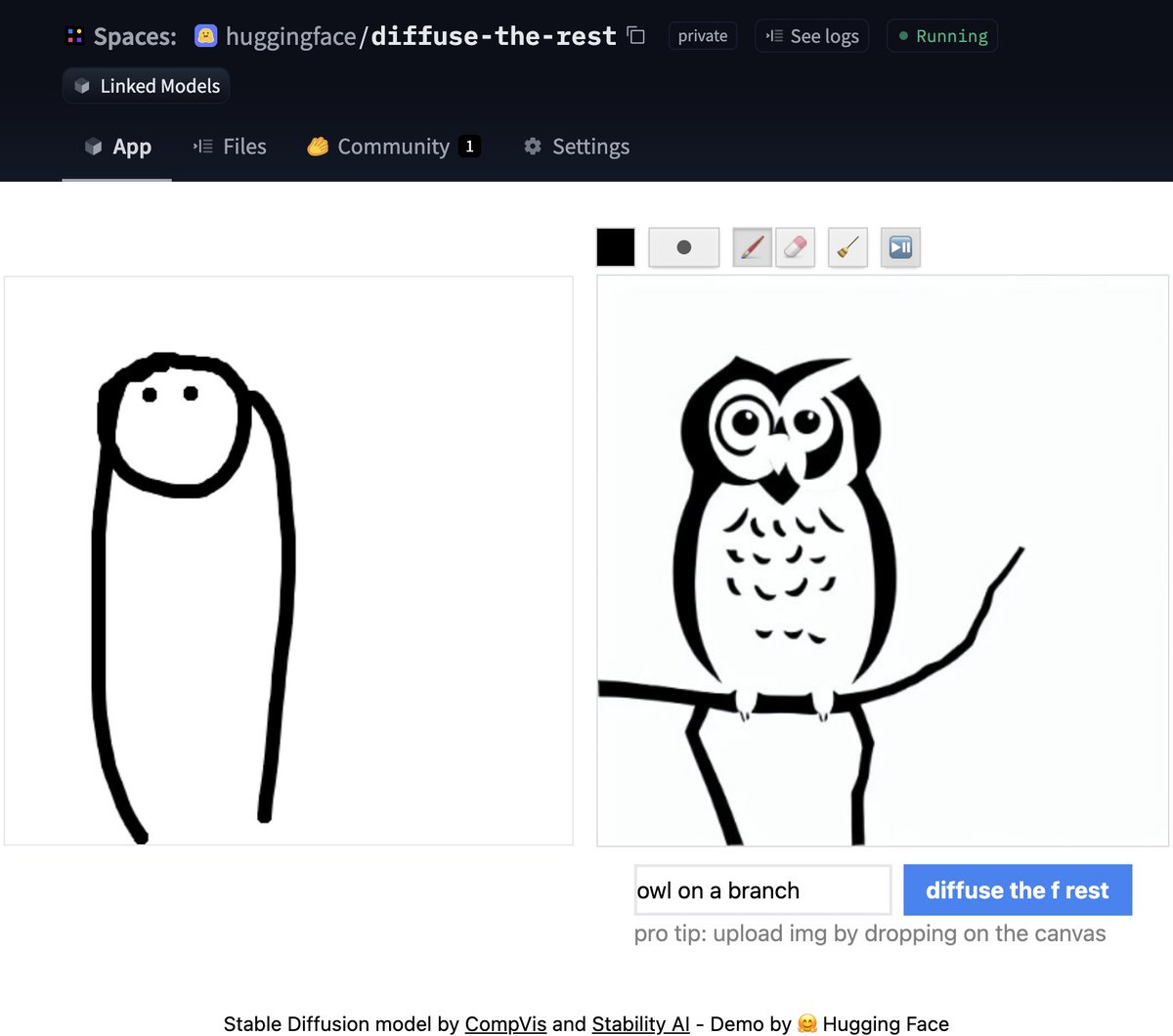
文本反转
文本反转允许您使用仅3-5个样本在自己的图像上个性化一个稳定扩散模型。使用这个工具,您可以在一个概念上训练一个模型,然后与社区的其他人分享这个概念!
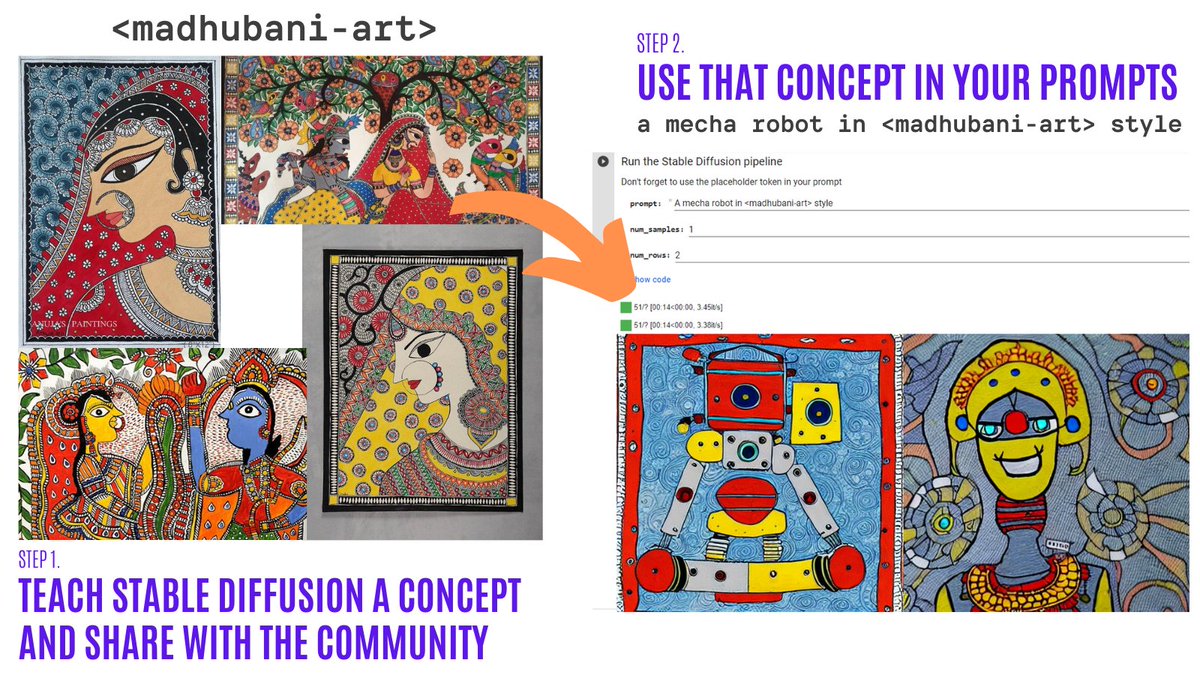
在短短几天内,社区分享了超过200个概念!快去看看吧!
- 按概念进行组织。
- 导航器 Colab:通过视觉浏览并使用社区创建的150多个概念。
- 训练 Colab:教会稳定扩散一个新概念,并与社区的其他人分享。
- 推理 Colab:使用已学习到的概念运行稳定扩散。
实验性修复流程
修复允许您提供一张图像,然后选择图像中的一个区域(或提供一个掩码),并使用稳定扩散替换掩码。这里是一个例子:

您可以尝试一个简化的 Colab 笔记本,或查看下面的代码。演示即将推出!
from diffusers import StableDiffusionInpaintPipeline
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
).to(device)
images = pipe(
prompt=["一只猫坐在长凳上"] * 3,
init_image=init_image,
mask_image=mask_image,
strength=0.75,
guidance_scale=7.5,
generator=None
).images请注意,这是实验性的,还有改进的空间。
针对较小的GPU的优化
经过一些改进,扩散模型所需的VRAM大大减少。🔥 例如,稳定扩散只需要3.2GB!这样可以以10%的速度为代价获得完全相同的结果。以下是如何使用这些优化的方法
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
)
pipe = pipe.to("cuda")
pipe.enable_attention_slicing()这非常令人激动,因为这将进一步降低使用这些模型的门槛!
Mac OS中的扩散
🍎 是的!又一个广受请求的功能刚刚发布!在官方文档中阅读完整的说明(包括性能比较、规格等)。
使用PyTorch的mps设备,使用M1/M2硬件的用户可以运行稳定扩散的推理。🤯 对用户而言,这只需要进行最少的设置,试一试吧!
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=True)
pipe = pipe.to("mps")
prompt = "一张马上骑着马的宇航员的照片"
image = pipe(prompt).images[0]实验性的ONNX导出器和管道
新的实验性管道允许用户在支持ONNX的任何硬件上运行稳定扩散。以下是如何使用它的示例(请注意正在使用的onnx版本)
from diffusers import StableDiffusionOnnxPipeline
pipe = StableDiffusionOnnxPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="onnx",
provider="CPUExecutionProvider",
use_auth_token=True,
)
prompt = "一张马上骑着马的宇航员的照片"
image = pipe(prompt).images[0]或者,您还可以使用导出器脚本将您的SD检查点直接转换为ONNX。
python scripts/convert_stable_diffusion_checkpoint_to_onnx.py --model_path="CompVis/stable-diffusion-v1-4" --output_path="./stable_diffusion_onnx"新文档
之前的所有功能都非常酷。作为开源库的维护者,我们知道高质量的文档对于使任何人尽可能轻松地尝试该库是多么重要。
💅 因此,我们进行了文档冲刺,我们非常激动地发布了我们的文档的第一个版本。这是一个初步版本,因此我们计划添加许多内容(欢迎贡献!)。
文档的一些亮点包括:
- 优化技巧
- 培训概览
- 贡献指南
- 深入的调度器API文档
- 深入的管道API文档
社区
在我们进行上述工作的同时,社区也没有闲着!以下是一些亮点(尽管不全面)
稳定扩散视频
通过探索潜在空间并在文本提示之间进行形态变化,可以创建🔥视频。您可以:
- 梦见相同提示的不同版本
- 在不同的提示之间进行形态变化
稳定扩散视频工具可以通过pip进行安装,附带有Colab笔记本和Gradio笔记本,非常易于使用!
这是一个示例
from stable_diffusion_videos import walk
video_path = walk(['一只猫', '一只狗'], [42, 1337], num_steps=3, make_video=True)扩散解释
扩散解释是建立在diffusers之上的可解释性工具。它具有以下很酷的功能:
- 查看扩散过程中的所有图像
- 分析提示中的每个令牌对生成的影响
- 如果您想要了解图像的一部分,可以在指定的边界框内进行分析
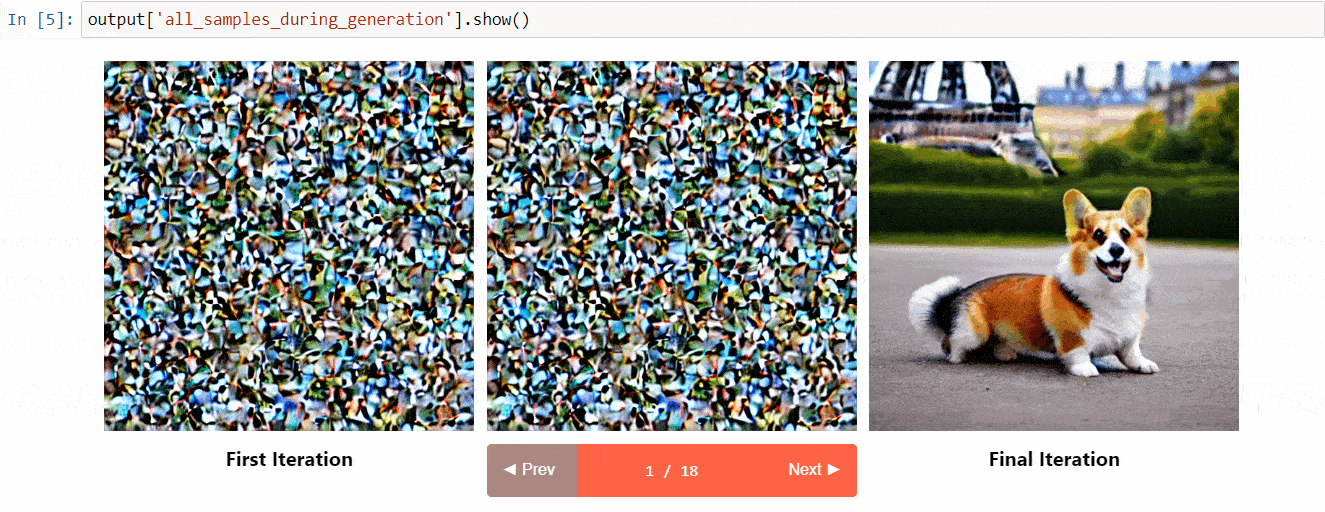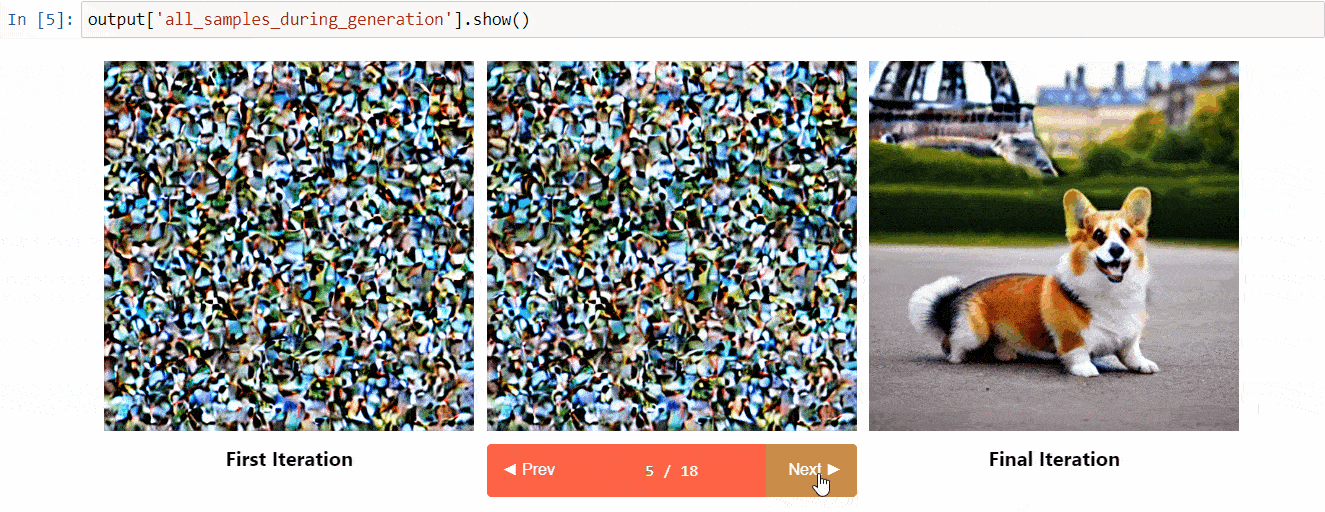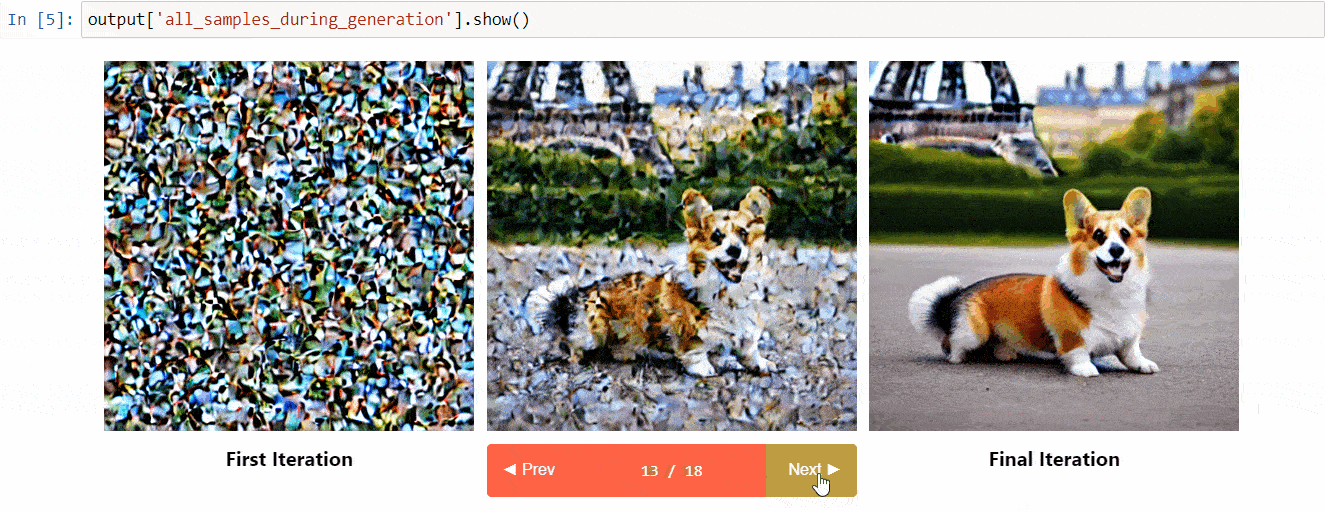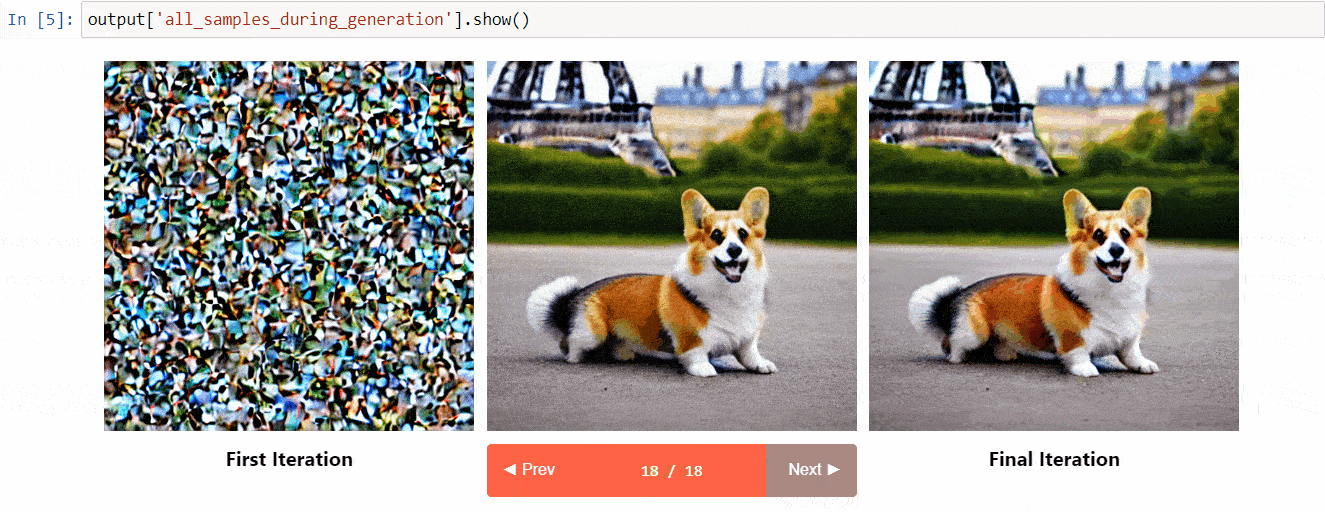 (来自工具库的图片)
(来自工具库的图片)
# 将管道传递给解释器类
explainer = StableDiffusionPipelineExplainer(pipe)
# 使用 `explainer` 生成图像
prompt = "柯基和埃菲尔铁塔"
output = explainer(
prompt,
num_inference_steps=15
)
output.normalized_token_attributions # (标记,归因百分比)
#[('柯基', 40),
# ('和', 5),
# ('埃菲尔', 5),
# ('铁塔', 25)]日本稳定扩散
名字就说明了一切!JSD 的目标是训练一个能够捕捉文化、身份和独特表达的模型。它使用了一亿个带有日语标题的图像进行训练。您可以在模型卡片中了解更多关于模型训练的信息
Waifu 扩散
Waifu 扩散是一个为高质量动漫图像生成而微调的 SD 模型。

(来自工具库的图片)
交叉注意力控制
交叉注意力控制允许通过修改扩散模型的注意力图来对提示进行精细控制。一些很酷的功能包括:
- 替换提示中的目标(例如将猫替换为狗)
- 减少或增加提示中单词的重要性(例如,如果您想减少对“rocks”的关注)
- 轻松注入样式
等等!请查看仓库了解更多信息。
可重复使用的种子
稳定扩散最令人印象深刻的早期演示之一是重用种子来调整图像。这个想法是使用感兴趣图像的种子生成一个新的图像,使用不同的提示。这样会产生一些很酷的结果!请查看 Colab
感谢阅读!
希望您喜欢阅读本文!记得在我们的 GitHub 仓库上给一个 Star,并加入 Hugging Face Discord 服务器,在那里我们有专门讨论扩散模型的频道。最新的库中的消息都会在那里分享!
欢迎提出功能请求和错误报告!所有这些成就都离不开如此精彩的社区。






