SVM背后的优化:原始形式和对偶形式
SVM优化:原始形式和对偶形式
点击此链接的人都已经了解支持向量机(SVM)了,但相信我,在背后有很多事情正在发生。
了解SVM优化的对偶形式和原始形式对于机器学习领域的数据科学家至关重要。它们让他们对SVM的工作原理有着基本的理解,使他们能够解释和解读SVM模型得到的结果。此外,这种知识有助于算法选择和定制,使数据科学家能够根据数据集大小和计算限制等因素选择最合适的优化方法。此外,了解对偶形式和原始形式有助于超参数调优、高级模型解释和优化SVM算法的计算效率。
所以,请系好安全带,因为这个过程中将涉及许多数学方程。
注意:所有图片都属于作者。
SVM有两种定义方式,一种是对偶形式,另一种是原始形式。两者都得到了相同的优化结果,但它们得到结果的方式却非常不同。在我们深入研究数学之前,让我告诉你什么时候使用哪种形式。当我们不需要对数据应用核技巧且数据集很大但每个数据点的维度很小时,首选原始形式。而当数据具有很高的维度且必须应用核技巧时,首选对偶形式。
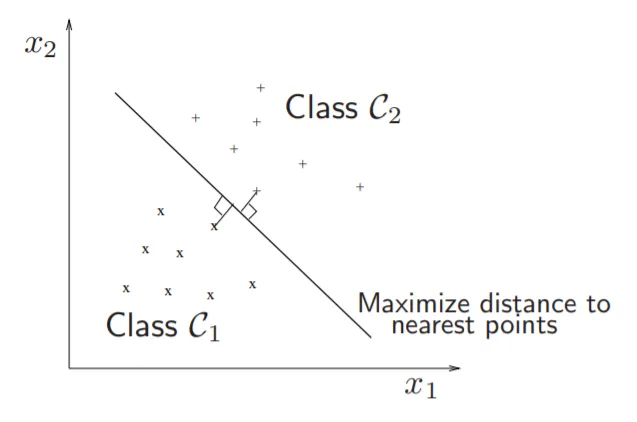
让我们了解一下在SVM中我们实际上是做什么。在SVM优化中,我们试图最大化超平面到支持向量的距离,这等同于最小化W(权重矩阵)的L2范数。随着我们对数学的探讨,我们将定义什么是支持向量。但是最大化距离如何等同于最小化权重矩阵呢?
• 类之间的间隔等于2/ ||w||_2。
• 最小化||w||_2等同于最大化间隔。
• 注意:w’ x1 + b = 1,w’x2 + b = − 1
⇒ w’(x1* − x2*) = 2 ⇒ w’( x1* − x2*)/||w||_2 = 2 /||w||_2
这里x1*和x2*是两个不同类别超平面上最近的点,||w||_2是权重矩阵的L2范数。




