在Amazon Personalize中,根据用户上下文推荐和动态过滤物品
组织不断投资时间和精力开发智能推荐解决方案,为用户提供定制和相关的内容。目标可以有很多:改变用户体验,产生有意义的互动,推动内容消费。其中一些解决方案使用常见的机器学习(ML)模型,基于历史交互模式、用户人口属性、产品相似性和群体行为构建。除了这些属性,交互时的上下文(如天气、位置等)也可以影响用户在浏览内容时的决策。
在本文中,我们将展示如何使用用户当前的设备类型作为上下文,以增强您基于Amazon Personalize的推荐的有效性。此外,我们还将展示如何使用这样的上下文动态过滤推荐。尽管本文展示了Amazon Personalize如何用于视频点播(VOD)用例,但值得注意的是,Amazon Personalize可用于多个行业。
什么是Amazon Personalize?
Amazon Personalize使开发人员能够构建由Amazon.com使用的实时个性化推荐所使用的ML技术驱动的应用程序。Amazon Personalize能够提供各种个性化体验,包括特定产品推荐、个性化产品重新排序和定制直接营销。此外,作为一个完全托管的AI服务,Amazon Personalize通过ML加速客户的数字转型,使将个性化推荐集成到现有网站、应用程序、电子邮件营销系统等变得更加容易。
为什么上下文很重要?
使用用户的上下文元数据,如位置、时间、设备类型和天气,为现有用户提供个性化体验,帮助改善新用户或未识别用户的冷启动阶段。冷启动阶段指的是在该用户的历史信息缺失的情况下,推荐引擎提供非个性化推荐的时间段。在存在其他要求过滤和推广项目的情况下(比如新闻和天气),添加用户当前的上下文(季节或时间)有助于通过包含和排除推荐来提高准确性。
让我们以VOD平台向用户推荐节目、纪录片和电影为例。根据行为分析,我们知道VOD用户倾向于在移动设备上消费像情景喜剧这样的短片内容,而在电视或台式机上消费电影等长片内容。
解决方案概述
在考虑用户设备类型的示例基础上,我们展示了如何将此信息作为上下文提供,以便Amazon Personalize可以自动学习用户设备对其偏好内容的影响。
我们按照以下图示的架构模式进行展示,以说明上下文如何自动传递给Amazon Personalize。通过包含在请求中的Amazon CloudFront标头(例如在调用AWS Lambda函数检索推荐的Amazon API Gateway的REST API中),可以自动获取上下文。请参阅我们的GitHub存储库中提供的完整代码示例。我们提供了一个AWS CloudFormation模板来创建必要的资源。
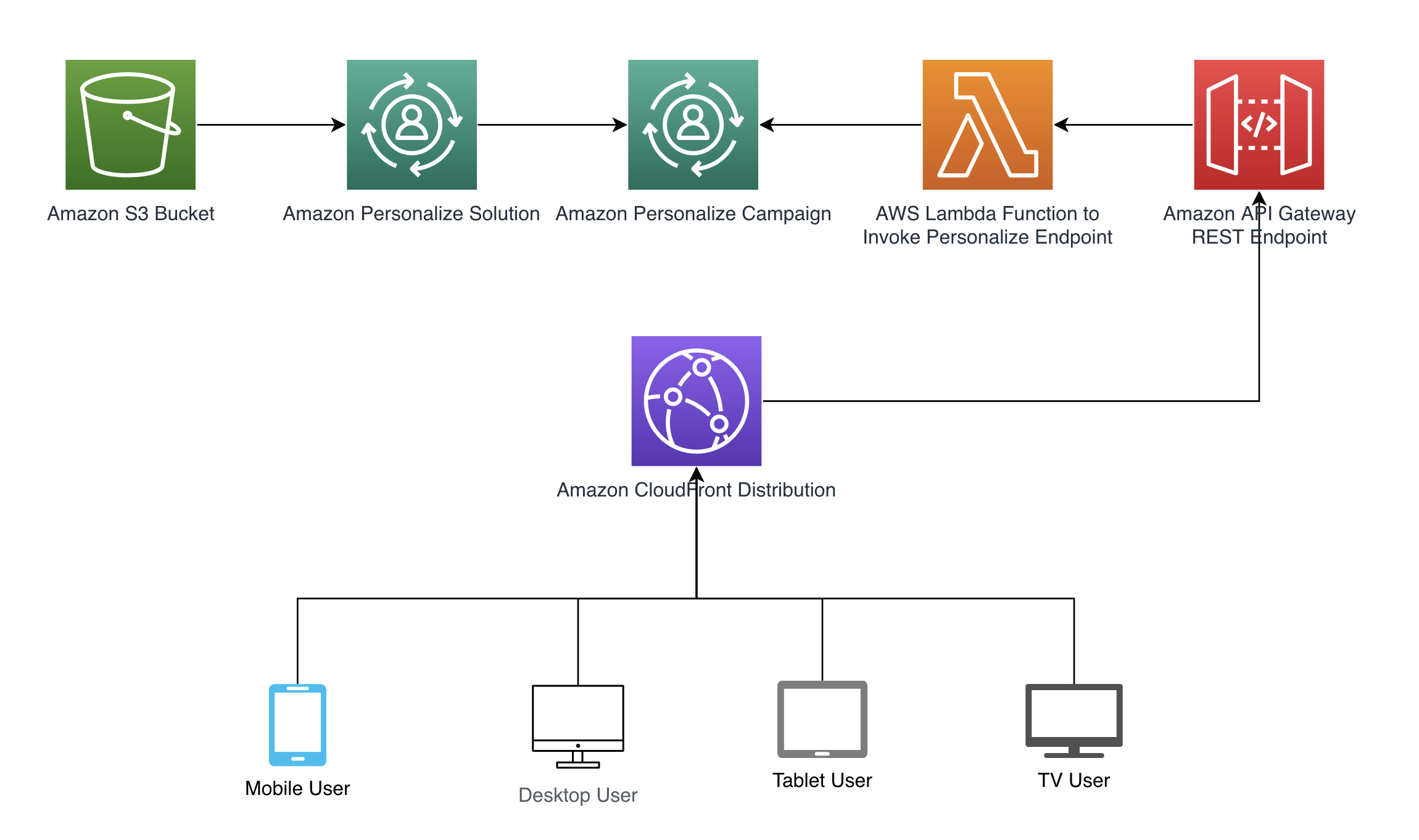
在接下来的章节中,我们将逐步介绍如何设置样例架构模式的每个步骤。
选择一个配方
配方是为特定用例准备的Amazon Personalize算法。Amazon Personalize根据常见用例为训练模型提供配方。对于我们的用例,我们使用User-Personalization配方构建了一个简单的Amazon Personalize自定义推荐器。它根据交互数据集预测用户将与之互动的项目。此外,如果提供了项目和用户数据集,此配方还会使用这些数据集影响推荐结果。要了解有关此配方的工作原理的更多信息,请参阅User-Personalization配方。
创建并导入数据集
利用上下文需要在交互中指定上下文值,以便推荐器在训练模型时将上下文作为特征使用。我们还必须在推理时提供用户的当前上下文。交互模式(请参见下面的代码)定义了历史和实时用户对项目的交互数据的结构。USER_ID、ITEM_ID和TIMESTAMP字段是Amazon Personalize对此数据集所必需的。DEVICE_TYPE是一个我们为此示例添加的自定义分类字段,用于捕捉用户的当前上下文并将其包含在模型训练中。Amazon Personalize使用这个交互数据集来训练模型并创建推荐活动。
{
"type": "record",
"name": "互动",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "用户ID",
"type": "字符串"
},
{
"name": "物品ID",
"type": "字符串"
},
{
"name": "设备类型",
"type": "字符串",
"categorical": true
},
{
"name": "时间戳",
"type": "长整型"
}
],
"version": "1.0"
}同样地,物品模式(见下方代码)定义了产品和视频目录数据的结构。对于这个数据集,物品ID是Amazon Personalize所必需的。 创建时间戳是一个保留的列名,但不是必需的。 类型和允许的国家是我们为此示例添加的自定义字段,用于捕获视频的类型和允许播放视频的国家。Amazon Personalize使用这个物品数据集来训练模型并创建推荐活动。
{
"type": "record",
"name": "物品",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "物品ID",
"type": "字符串"
},
{
"name": "类型",
"type": "字符串",
"categorical": true
},
{
"name": "允许的国家",
"type": "字符串",
"categorical": true
},
{
"name": "创建时间戳",
"type": "长整型"
}
],
"version": "1.0"
}在我们的上下文中,历史数据指的是VOD平台上的视频和物品的终端用户交互历史。这些数据通常会被收集和存储在应用程序的数据库中。
为了演示目的,我们使用Python的Faker库生成一些测试数据,模拟与不同物品、用户和设备类型的交互数据,时间跨度为3个月。在定义了模式和输入交互文件位置之后,下一步是创建一个数据集组,将交互数据集包含在数据集组中,最后将训练数据导入数据集,如下面的代码片段所示:
create_dataset_group_response = personalize.create_dataset_group(
name = "personalize-auto-context-demo-dataset-group"
)
create_interactions_dataset_response = personalize.create_dataset(
name = "personalize-auto-context-demo-interactions-dataset",
datasetType = ‘INTERACTIONS’,
datasetGroupArn = interactions_dataset_group_arn,
schemaArn = interactions_schema_arn
)
create_interactions_dataset_import_job_response = personalize.create_dataset_import_job(
jobName = "personalize-auto-context-demo-dataset-import",
datasetArn = interactions_dataset_arn,
dataSource = {
"dataLocation": "s3://{}/{}".format(bucket, interactions_filename)
},
roleArn = role_arn
)
create_items_dataset_response = personalize.create_dataset(
name = "personalize-auto-context-demo-items-dataset",
datasetType = ‘ITEMS’,
datasetGroupArn = items_dataset_group_arn,
schemaArn = items_schema_arn
)
create_items_dataset_import_job_response = personalize.create_dataset_import_job(
jobName = "personalize-auto-context-demo-items-dataset-import",
datasetArn = items_dataset_arn,
dataSource = {
"dataLocation": "s3://{}/{}".format(bucket, items_filename)
},
roleArn = role_arn
)收集历史数据并训练模型
在这一步中,我们定义了选择的配方(recipe),并创建了一个解决方案和解决方案版本,这些都是参考之前定义的数据集组。当您创建一个自定义解决方案时,您需要指定一个配方并配置训练参数。当您为解决方案创建一个解决方案版本时,Amazon Personalize会根据配方和训练配置来训练支持解决方案版本的模型。请参阅下面的代码:
recipe_arn = "arn:aws:personalize:::recipe/aws-user-personalization"
create_solution_response = personalize.create_solution(
name = "personalize-auto-context-demo-solution",
datasetGroupArn = dataset_group_arn,
recipeArn = recipe_arn
)
create_solution_version_response = personalize.create_solution_version(
solutionArn = solution_arn
)创建一个活动终端点
在训练模型之后,您将其部署到一个活动中。活动会为您训练的模型创建和管理一个自动扩缩容的终端点,您可以使用该终端点通过GetRecommendations API获取个性化推荐。在后续的步骤中,我们将使用此活动终端点自动将设备类型作为上下文参数传递,并接收个性化推荐。请参考以下代码:
create_campaign_response = personalize.create_campaign(
name = "personalize-auto-context-demo-campaign",
solutionVersionArn = solution_version_arn
)创建一个动态过滤器
在从创建的活动中获取推荐时,您可以基于自定义条件对结果进行过滤。例如,为了满足仅推荐能够在用户当前所在国家播放的视频的要求,我们创建了一个过滤器。国家信息会从CloudFront的HTTP头动态传递。
create_filter_response = personalize.create_filter(
name = 'personalize-auto-context-demo-country-filter',
datasetGroupArn = dataset_group_arn,
filterExpression = 'INCLUDE ItemID WHERE Items.ALLOWED_COUNTRIES IN ($CONTEXT_COUNTRY)'
)创建一个Lambda函数
我们架构中的下一步是创建一个Lambda函数,用于处理来自CloudFront分发的API请求,并通过调用Amazon Personalize活动终端点来响应。在此Lambda函数中,我们定义了分析以下CloudFront请求的HTTP头和查询字符串参数的逻辑,以确定用户的设备类型和用户ID:
CloudFront-Is-Desktop-ViewerCloudFront-Is-Mobile-ViewerCloudFront-Is-SmartTV-ViewerCloudFront-Is-Tablet-ViewerCloudFront-Viewer-Country
创建此函数的代码通过CloudFormation模板部署。
创建一个REST API
为了使Lambda函数和Amazon Personalize活动终端点对CloudFront分发可访问,我们创建了一个REST API终端点,并设置为Lambda代理。API Gateway提供了创建和文档化API的工具,用于将HTTP请求路由到Lambda函数。Lambda代理集成功能允许CloudFront调用一个Lambda函数,将请求抽象为对Amazon Personalize活动终端点的调用。创建此函数的代码通过CloudFormation模板部署。
创建一个CloudFront分发
在创建CloudFront分发时,由于这是一个演示设置,我们使用自定义缓存策略禁用缓存,确保每次请求都会发送到源。此外,我们使用一个源请求策略指定在源请求中所需的HTTP头和查询字符串参数。创建此函数的代码通过CloudFormation模板部署。
测试推荐
当从不同设备(如台式机、平板电脑、手机等)访问CloudFront分发的URL时,我们可以看到与其设备最相关的个性化视频推荐。此外,如果出现冷启动用户,将呈现针对用户设备定制的推荐。在以下示例输出中,视频的名称仅用于表示其类型和时长,以使其具有可关联性。
在以下代码中,一个已知的用户,根据过去的互动喜欢喜剧,从手机设备访问时会呈现较短的情景喜剧:
用户的推荐结果: 460
ITEM_ID 类型 允许的国家
380 喜剧 RU|GR|LT|NO|SZ|VN
540 情景喜剧 US|PK|NI|JM|IN|DK
860 喜剧 RU|GR|LT|NO|SZ|VN
600 喜剧 US|PK|NI|JM|IN|DK
580 喜剧 US|FI|CN|ES|HK|AE
900 讽刺 US|PK|NI|JM|IN|DK
720 情景喜剧 US|PK|NI|JM|IN|DK以下是另一个已知用户,根据过去的互动,从智能电视设备访问时会呈现特色电影:
用户的推荐结果: 460
ITEM_ID 类型 允许的国家
780 浪漫 US|PK|NI|JM|IN|DK
100 恐怖 US|FI|CN|ES|HK|AE
400 动作 US|FI|CN|ES|HK|AE
660 恐怖 US|PK|NI|JM|IN|DK
720 恐怖 US|PK|NI|JM|IN|DK
820 悬疑 US|FI|CN|ES|HK|AE
520 悬疑 US|FI|CN|ES|HK|AE一个从手机访问的冷(未知)用户将会看到更短但受欢迎的节目:
为用户推荐: 666
ITEM_ID 类型 允许的国家
940 讽刺 美国|芬兰|中国|西班牙|香港|阿联酋
760 讽刺 美国|芬兰|中国|西班牙|香港|阿联酋
160 情景喜剧 美国|芬兰|中国|西班牙|香港|阿联酋
880 喜剧 美国|芬兰|中国|西班牙|香港|阿联酋
360 讽刺 美国|巴基斯坦|尼加拉瓜|牙买加|印度|丹麦
840 讽刺 美国|巴基斯坦|尼加拉瓜|牙买加|印度|丹麦
420 讽刺 美国|巴基斯坦|尼加拉瓜|牙买加|印度|丹麦 一个从桌面访问的冷(未知)用户将会看到最佳科幻电影和纪录片:
为用户推荐: 666
ITEM_ID 类型 允许的国家
120 科幻 美国|巴基斯坦|尼加拉瓜|牙买加|印度|丹麦
160 科幻 美国|芬兰|中国|西班牙|香港|阿联酋
680 科幻 俄罗斯|希腊|立陶宛|挪威|瑞士|越南
640 科幻 美国|芬兰|中国|西班牙|香港|阿联酋
700 纪录片 美国|芬兰|中国|西班牙|香港|阿联酋
760 科幻 美国|芬兰|中国|西班牙|香港|阿联酋
360 纪录片 美国|巴基斯坦|尼加拉瓜|牙买加|印度|丹麦 以下从手机访问的已知用户根据位置(美国)返回筛选后的推荐:
为用户推荐: 460
ITEM_ID 类型 允许的国家
300 情景喜剧 美国|巴基斯坦|尼加拉瓜|牙买加|印度|丹麦
480 讽刺 美国|巴基斯坦|尼加拉瓜|牙买加|印度|丹麦
240 喜剧 美国|巴基斯坦|尼加拉瓜|牙买加|印度|丹麦
900 情景喜剧 美国|巴基斯坦|尼加拉瓜|牙买加|印度|丹麦
880 喜剧 美国|芬兰|中国|西班牙|香港|阿联酋
220 情景喜剧 美国|芬兰|中国|西班牙|香港|阿联酋
940 情景喜剧 美国|芬兰|中国|西班牙|香港|阿联酋 结论
在本文中,我们介绍了如何使用用户设备类型作为上下文数据,使您的推荐更加相关。使用上下文元数据来训练Amazon Personalize模型,将有助于向新用户和现有用户推荐相关产品,不仅仅是从配置文件数据中,还包括浏览设备平台的数据。不仅如此,像位置(国家、城市、地区、邮政编码)和时间(星期几、周末、工作日、季节)这样的上下文还为推荐相关性提供了机会。您可以使用我们在GitHub存储库中提供的CloudFormation模板运行完整的代码示例,并将笔记本克隆到Amazon SageMaker Studio中。