🤗 Transformers中原生支持的量化方案概述
Overview of native quantization schemes in 🤗 Transformers
我们旨在清晰地概述transformers中支持的每种量化方案的优缺点,以帮助您决定应该选择哪种方案。
目前,量化模型主要用于两个目的:
- 在较小的设备上运行大型模型的推理
- 在量化模型上面微调适配器
到目前为止,已经进行了两个集成工作,并且在transformers中得到了原生支持:bitsandbytes和auto-gptq。请注意,🤗优化库还支持一些其他的量化方案,但这超出了本博文的范围。
要了解有关每个支持的方案的更多信息,请查看下面共享的资源之一。还请查看文档的适当部分。
还请注意,下面分享的详细信息仅适用于PyTorch模型,目前不适用于Tensorflow和Flax/JAX模型。
目录
- 资源
- bitsandbyes和auto-gptq的优缺点
- 深入速度基准
- 结论和最后的话
- 致谢
资源
- GPTQ博文 – 概述了GPTQ量化方法及其使用方法。
- bitsandbytes 4位量化博文 – 介绍了4位量化和高效的微调方法QLoRa。
- bitsandbytes 8位量化博文 – 解释了bitsandbytes如何使用8位量化。
- GPTQ基本用法Google Colab笔记本 – 该笔记本展示了如何使用GPTQ方法量化transformers模型,如何进行推理,以及如何使用量化模型进行微调。
- bitsandbytes基本用法Google Colab笔记本 – 该笔记本展示了如何使用4位模型进行推理以及其所有变体,并在免费的Google Colab实例上运行GPT-neo-X(一个200B参数的模型)。
- Merve关于量化的博文 – 该博文提供了量化和transformers中原生支持的量化方法的简介。
bitsandbyes和auto-gptq的优缺点
在本节中,我们将介绍bitsandbytes和gptq量化的优缺点。请注意,这些是基于社区反馈的,并且随着这些功能在各自库的路线图中,它们可能会随时间而发展。
bitsandbytes优点
简单:bitsandbytes仍然是量化任何模型最简单的方法,因为它不需要使用输入数据校准量化模型(也称为零校准量化)。只要模型包含torch.nn.Linear模块,就可以直接使用bitsandbytes量化任何模型。每当在transformers中添加新的架构时,只要它们可以使用accelerate的device_map=”auto”加载,用户就可以直接使用bitsandbytes量化,而性能几乎不受影响。量化在模型加载时执行,无需运行任何后处理或准备步骤。
跨模态互操作性:由于量化模型的唯一条件是包含torch.nn.Linear层,因此量化可以直接用于任何模态,可以直接加载Whisper、ViT、Blip2等模型的8位或4位版本。
合并适配器时没有性能降低:(如果您对适配器和PEFT不熟悉,请在这篇博文中阅读更多信息)。如果您在量化的基础模型上训练适配器,那么适配器可以在部署时与基础模型合并,而不会降低推理性能。您还可以将适配器合并到去量化的模型上!这对于GPTQ不支持。
autoGPTQ优点
用于文本生成速度快:与bitsandbytes量化模型相比,GPTQ量化模型在文本生成方面速度更快。我们将在适当的部分讨论速度比较。
n位支持:GPTQ算法使得模型可以进行2位的量化!然而,这可能会导致严重的质量下降。推荐的位数是4,这在目前的GPTQ中似乎是一个很好的折衷。
易于序列化:GPTQ模型支持任意位数的序列化。可以直接支持从TheBloke命名空间加载模型:https://huggingface.co/TheBloke(查找以-GPTQ后缀结尾的模型),前提是您已安装所需的软件包。Bitsandbytes支持8位的序列化,但目前不支持4位的序列化。
AMD支持:该集成应该可以直接在AMD GPU上运行!
bitsandbytes的缺点
对于文本生成而言,比GPTQ慢:与GPTQ相比,bitsandbytes的4位模型在使用generate时速度较慢。
4位权重无法序列化:目前,4位模型无法进行序列化。这是社区经常提出的请求,我们相信bitsandbytes的维护者应该会很快解决,因为这是他们的计划路线!
autoGPTQ的缺点
校准数据集:校准数据集的需求可能会使一些用户对GPTQ望而却步。此外,模型的量化过程可能需要几个小时(例如,对于一个180B的模型,需要4个GPU小时)
目前仅适用于语言模型:截至目前,使用auto-GPTQ对模型进行量化的API仅设计用于支持语言模型。使用GPTQ算法量化非文本(或多模态)模型应该是可行的,但原始论文或auto-gptq存储库中尚未详细说明该过程。如果社区对此主题感兴趣,这可能会在将来考虑。
深入研究速度基准
我们决定为使用bitsandbytes和auto-gptq的推理和微调适配器提供广泛的基准测试。推理基准测试应该让用户了解在推理过程中使用我们提出的不同方法之间可能获得的速度差异,而适配器微调基准测试应该让用户在决定在bitsandbytes和GPTQ基础模型之上微调适配器时选择哪种方法时有一个清晰的想法。
我们将使用以下设置:
- bitsandbytes:使用
bnb_4bit_compute_dtype=torch.float16进行4位量化。请确保使用bitsandbytes>=0.41.1以获得快速的4位内核。 - auto-gptq:使用exllama内核进行4位量化。您将需要
auto-gptq>=0.4.0以使用ex-llama内核。
推理速度(仅正向传递)
此基准测试仅测量预填充步骤,即训练期间的正向传递。它在一台单个的NVIDIA A100-SXM4-80GB GPU上运行,提示长度为512。我们使用的模型是meta-llama/Llama-2-13b-hf。
批大小为1:
批大小为16:
通过基准测试,我们可以看到bitsandbyes和GPTQ是等效的,对于较大的批大小,GPTQ稍微快一些。点击此链接以获取有关这些基准测试的更多详细信息。
生成速度
以下基准测试测量了模型在推理过程中的生成速度。可以在此处找到基准测试脚本以进行再现。
use_cache
让我们测试use_cache以更好地了解在生成过程中缓存隐藏状态的影响。
该基准测试在A100上运行,提示长度为30,我们生成了30个标记。我们使用的模型是meta-llama/Llama-2-7b-hf。
使用 use_cache=True
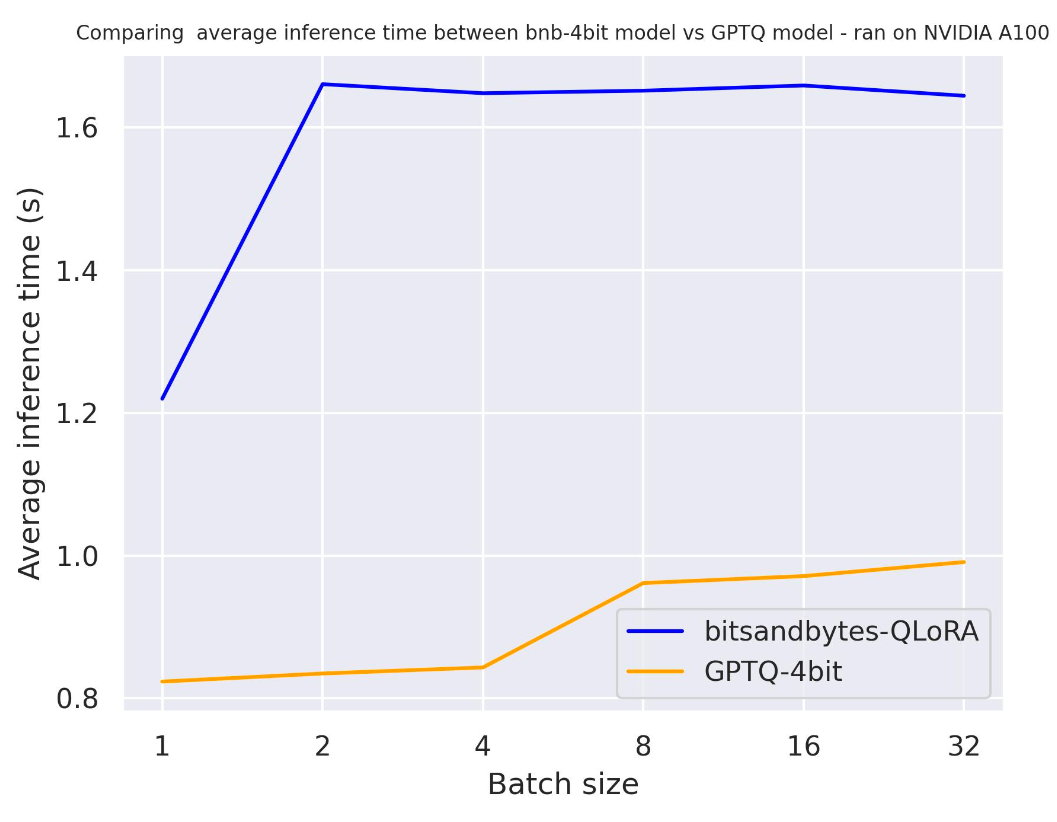
使用 use_cache=False
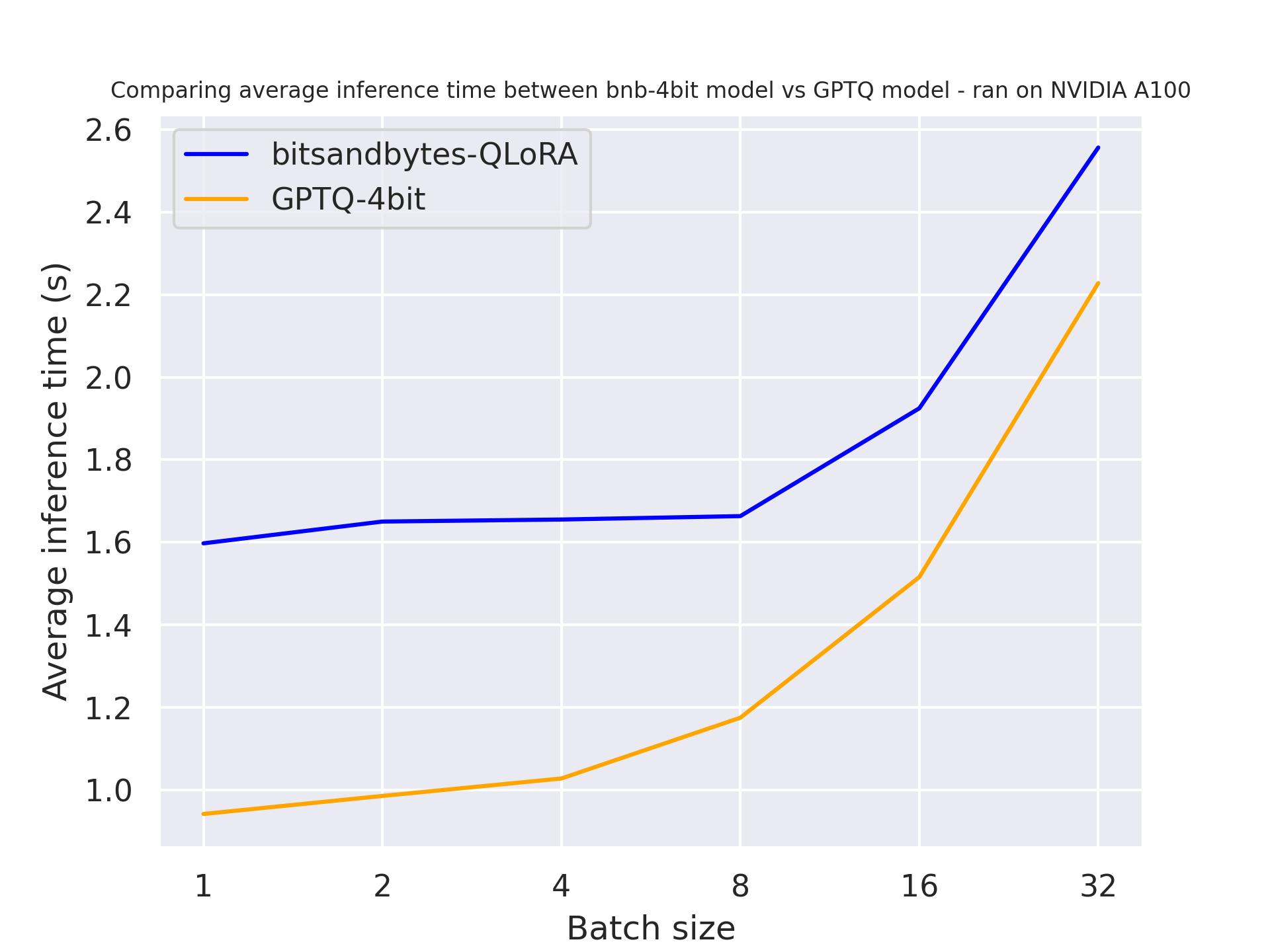
从这两个基准测试中,我们可以得出结论,使用注意力缓存时生成速度更快,这是预期的。此外,总体上来说,GPTQ 比 bitsandbytes 更快。例如,使用batch_size=4 和 use_cache=True 时,速度快了一倍!因此,让我们在下一个基准测试中使用use_cache。需要注意的是,use_cache 将消耗更多内存。
硬件
在下面的基准测试中,我们将尝试不同的硬件,以了解对量化模型的影响。我们使用了长度为30的提示,并生成了确切的30个标记。我们使用的模型是meta-llama/Llama-2-7b-hf。
使用 NVIDIA A100:
使用 NVIDIA T4:
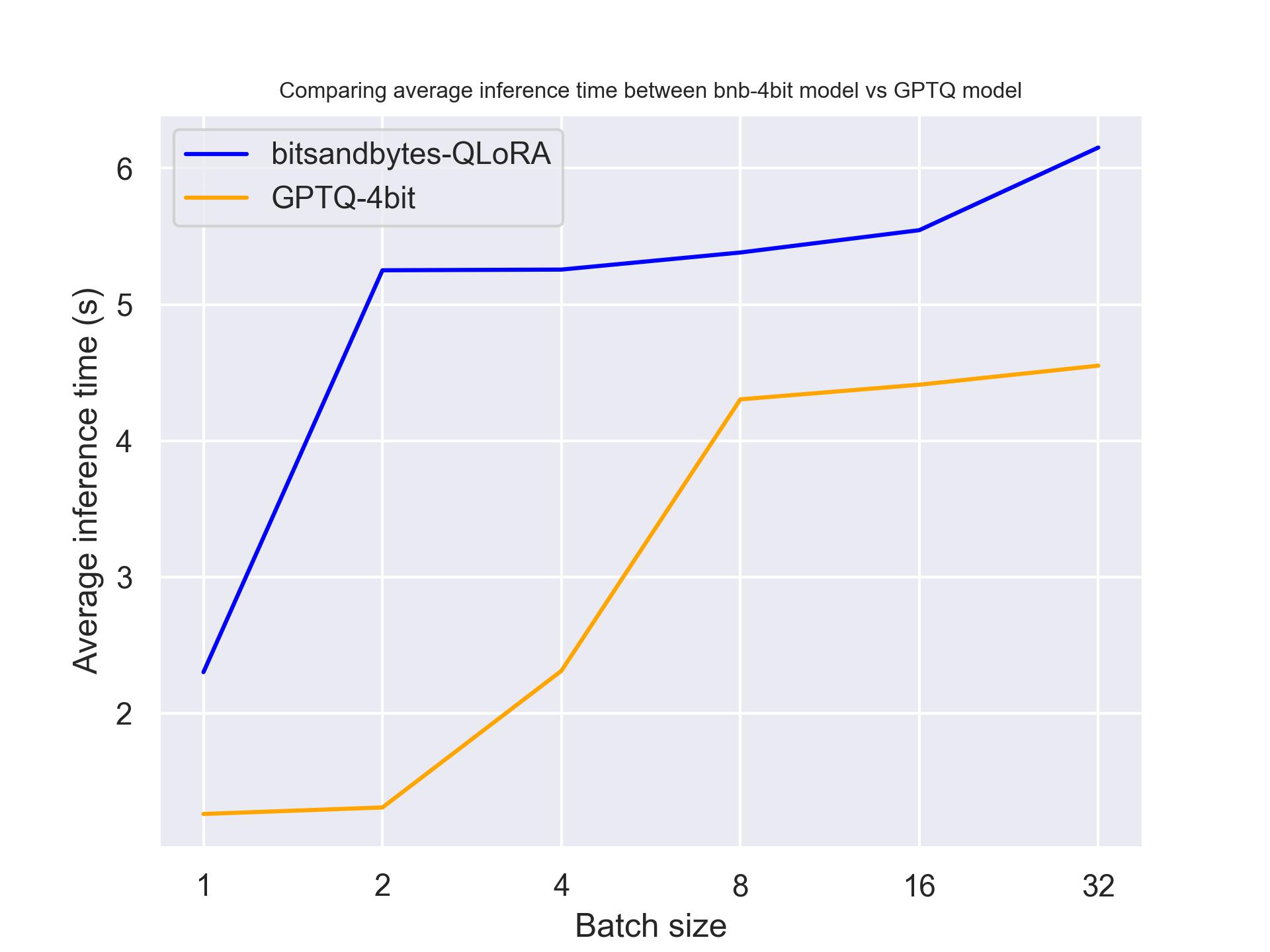
使用 Titan RTX:
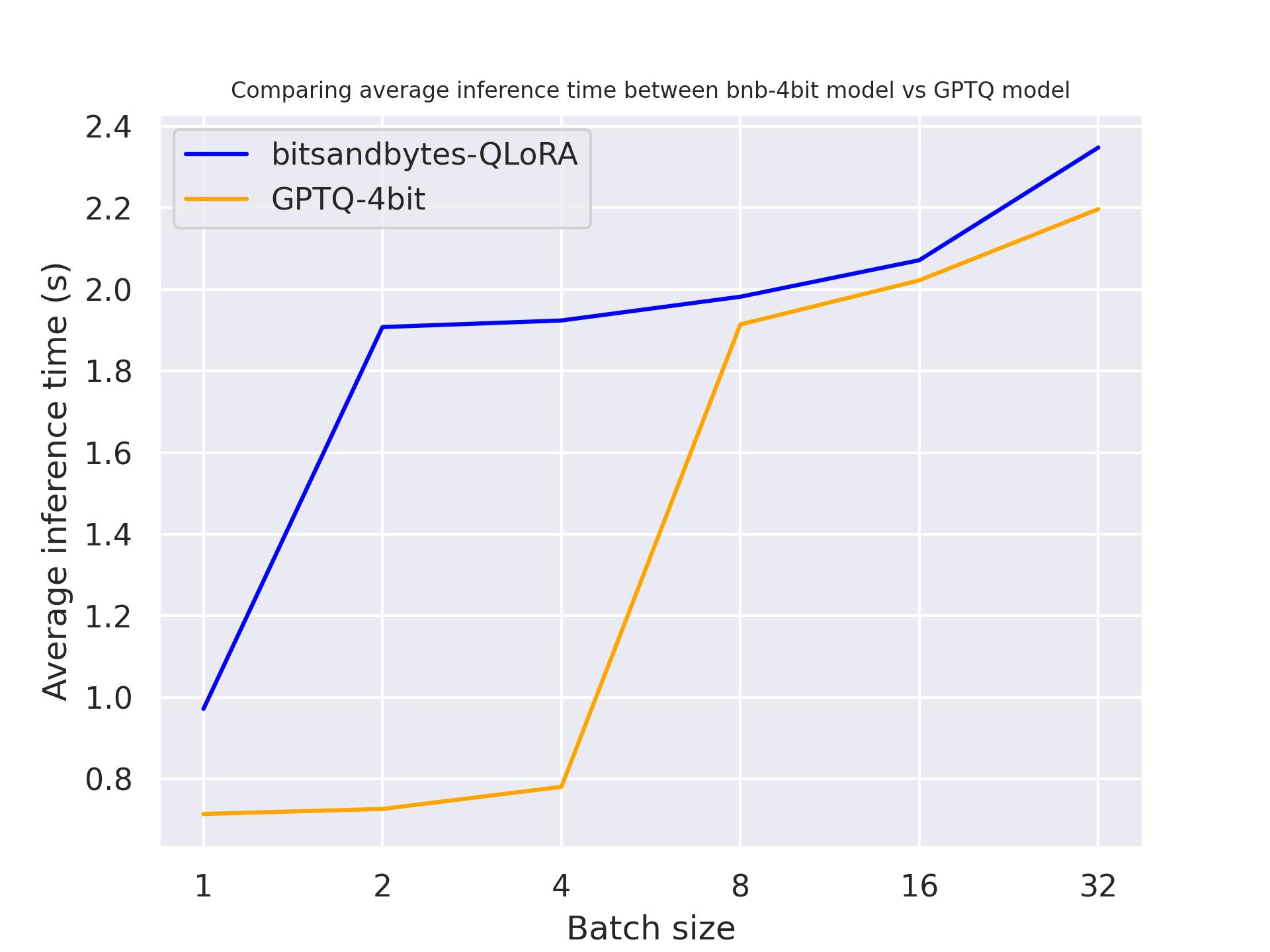
从上面的基准测试中,我们可以得出结论,对于这三种 GPU,GPTQ 比 bitsandbytes 更快。
生成长度
在下面的基准测试中,我们将尝试不同的生成长度,以了解对量化模型的影响。它在 A100 上运行,我们使用了长度为30的提示,并变化了生成的标记数。我们使用的模型是meta-llama/Llama-2-7b-hf。
生成30个标记:
生成512个标记:
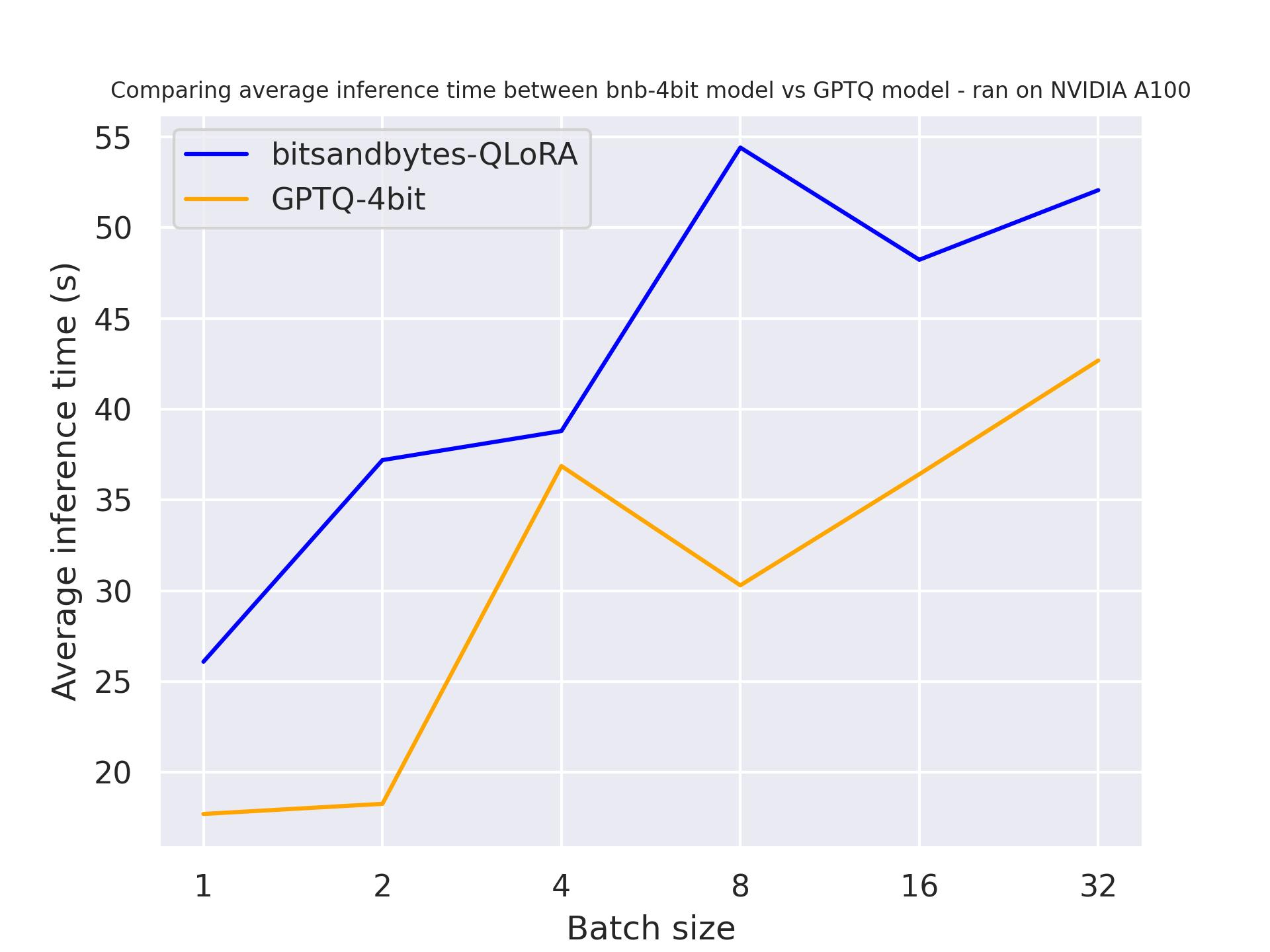
从上面的基准测试中,我们可以得出结论,无论生成长度如何,GPTQ 都比 bitsandbytes 更快。
适配器微调(前向 + 后向)
无法对量化模型进行纯训练。但是,您可以利用参数高效微调方法(PEFT)对量化模型进行微调,并在其上面训练适配器。微调方法将依赖于最近的一种方法,称为“低秩适配器”(LoRA):您只需微调这些适配器,并在模型内正确加载它们。让我们比较微调速度!
基准测试在 NVIDIA A100 GPU 上运行,我们使用了 Hub 中的meta-llama/Llama-2-7b-hf模型。需要注意的是,对于 GPTQ 模型,我们必须禁用 exllama 内核,因为 exllama 不支持微调。
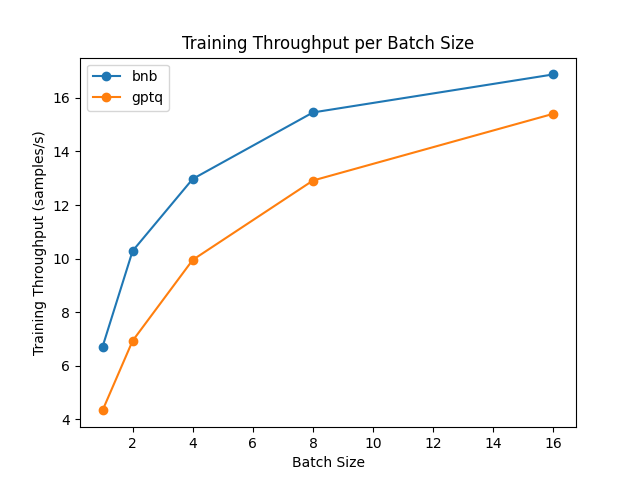
从结果中,我们可以得出结论,对于微调,bitsandbytes 的速度比 GPTQ 快。
性能下降
量化对于减少内存消耗非常有用。但是,它确实会导致性能下降。让我们使用 Open-LLM 排行榜来比较性能!
使用7b模型:
使用13b模型:
从上面的结果可以得出结论,较大的模型降级较少。更有趣的是,降级程度非常小!
结论和最后的话
在这篇博文中,我们对bitsandbytes和GPTQ量化进行了多个设置的比较。我们发现bitsandbytes更适用于微调,而GPTQ更适合生成。根据这个观察,改进合并模型的一种方法是:
- (1) 使用bitsandbytes对基础模型进行量化(零-shot量化)
- (2) 添加并微调适配器
- (3) 在基础模型或去量化模型上合并训练好的适配器!
- (4) 使用GPTQ对合并模型进行量化,并将其用于部署
我们希望这个概述能让每个人在他们的应用和用例中更容易使用LLMs,我们期待看到您将用它构建什么!
致谢
我们要感谢Ilyas、Clémentine和Felix对基准测试的帮助。
最后,我们要感谢Pedro Cuenca在撰写这篇博文时的帮助。






