在Mozilla Common Voice上的语音识别——音频转换
Mozilla Common Voice语音识别及音频转换
这是基于Mozilla Common Voice数据集的口语语音识别的第三篇文章。在第一部分中,我们讨论了数据选择和数据预处理,第二部分中,我们分析了几个神经网络分类器的性能。
最终模型达到了92%的准确率和97%的成对准确率。由于该模型存在一定的方差,通过添加更多的数据可能可以提高准确性。获取额外数据的一种常见方法是通过对现有数据集进行各种变换来合成数据。
在本文中,我们将考虑5种流行的音频数据增强变换:添加噪声、改变速度、改变音调、时间遮蔽和剪切与拼接。
教程笔记本可以在此处找到。
- 提高10倍生产力的前10个VS Code扩展
- “会见PUG:Meta AI的一项新的AI研究,使用虚幻引擎生成逼真的、语义可控的数据集,用于强大的模型评估”
- Salesforce研究人员介绍了XGen-Image-1:一种文本到图像的潜在扩散模型,经过训练以重新使用多个预训练组件
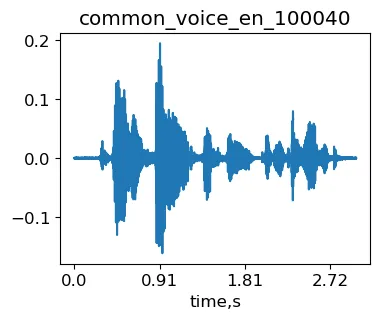
为了说明目的,我们将使用Mozilla Common Voice(MCV)数据集中的示例common_voice_en_100040。这是句子:The burning fire had been extinguished。
import librosa as lrimport IPythonsignal, sr = lr.load('./transformed/common_voice_en_100040.wav', res_type='kaiser_fast') #load signalIPython.display.Audio(signal, rate=sr)MCV中的原始示例common_voice_en_100040。
添加噪声
添加噪声是最简单的音频增强方法。噪声的大小由信噪比(SNR)来描述,即最大信号幅度和噪声标准差之间的比值。我们将生成几个噪声水平,用SNR定义,并观察它们如何改变信号。
SNRs = (5,10,100,1000) #信噪比:最大幅度除以噪声标准差noisy_signal = {}for snr in SNRs: noise_std = max(abs(signal))/snr #获取噪声标准差 noise = noise_std*np.random.randn(len(signal),) #生成给定标准差的噪声 noisy_signal[snr] = signal+noiseIPython.display.display(IPython.display.Audio(noisy_signal[5], rate=sr))IPython.display.display(IPython.display.Audio(noisy_signal[1000], rate=sr))通过在原始MCV示例common_voice_en_100040上叠加SNR=5和SNR=1000的噪声获得的信号(作者生成)。
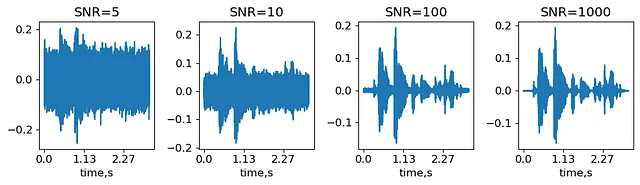
因此,SNR=1000的声音几乎听起来像未经扰动的音频,而在SNR=5的情况下,人们只能辨别出信号的最强部分。在实践中,SNR水平是依赖于数据集和选择的分类器的超参数。
改变速度
改变速度的最简单方法就是假装信号具有不同的采样率。然而,这也会改变音调(音频听起来的低/高频率)。增加采样率会使声音听起来更高。为了说明这一点,我们将为我们的示例“增加”1.5倍的采样率:
IPython.display.Audio(signal, rate=sr*1.5)通过对原始MCV示例common_voice_en_100040使用虚假采样率获得的信号(作者生成)。
在不影响音调的情况下改变速度更具挑战性。需要使用相位音频编码器(PV)算法。简而言之,输入信号首先分割成重叠的帧。然后,通过应用快速傅里叶变换(FFT)计算每个帧内的频谱。然后,通过以不同速率重合帧的方式修改播放速度。由于每个帧的频率内容不受影响,音调保持不变。PV在帧之间插值,并使用相位信息实现平滑。
对于我们的实验,我们将使用来自此PV实现的stretch_wo_loop时间拉伸函数。
stretching_factor = 1.3signal_stretched = stretch_wo_loop(signal, stretching_factor)IPython.display.Audio(signal_stretched, rate=sr)通过改变原始MCV样本common_voice_en_100040(由作者生成)的速度获得的信号。
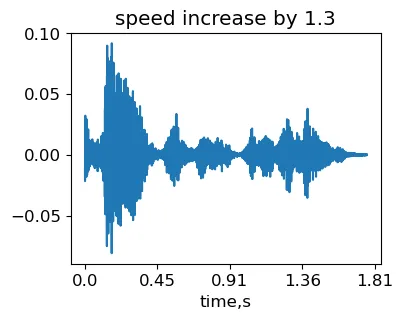
因此,由于我们增加了速度,信号的持续时间减少了。然而,可以听到音高没有改变。请注意,当拉伸因子很大时,帧之间的相位插值可能效果不佳。因此,转换后的音频中可能会出现回声伪影。
改变音高
为了在不影响速度的情况下改变音高,我们可以使用相同的PV时间拉伸,但假装信号具有不同的采样率,以使信号的总持续时间保持不变:
IPython.display.Audio(signal_stretched, rate=sr/stretching_factor)通过改变原始MCV样本common_voice_en_100040(由作者生成)的音高获得的信号。
为什么我们要费心使用这个PV,而librosa已经有time_stretch和pitch_shift函数了呢?嗯,这些函数会将信号转换回时域。当您之后需要计算嵌入时,您将浪费时间进行冗余的傅里叶变换。另一方面,很容易修改stretch_wo_loop函数,使其产生傅里叶输出而不进行逆变换。也许您还可以尝试深入研究librosa代码以实现类似的结果。
时间遮罩和剪切拼接
这两种转换最初是在频域中提出的(Park等人,2019年)。其思想是通过使用预计算的音频谱来节省FFT的时间。为了简单起见,我们将演示这些转换在时域中的工作方式。通过将时间轴替换为帧索引,可以轻松地将这些操作转移到频域。
时间遮罩
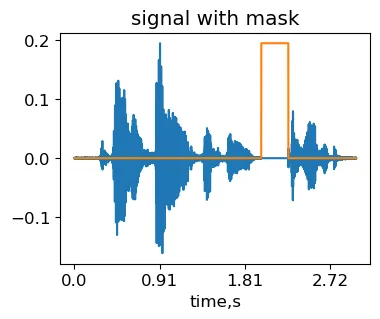
时间遮罩的思想是覆盖信号中的一个随机区域。这样,神经网络就较少有机会学习不可推广的信号特定的时间变化。
max_mask_length = 0.3 #最大遮罩持续时间,相对于信号长度L = len(signal)mask_length = int(L*np.random.rand()*max_mask_length) #随机选择遮罩长度mask_start = int((L-mask_length)*np.random.rand()) #随机选择遮罩位置masked_signal = signal.copy()masked_signal[mask_start:mask_start+mask_length] = 0IPython.display.Audio(masked_signal, rate=sr)通过在原始MCV样本common_voice_en_100040(由作者生成)上应用时间遮罩转换获得的信号。
剪切拼接
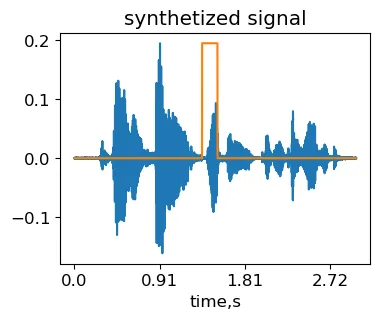
这个想法是用具有相同标签的另一个信号的随机选择区域替换信号的随机选择区域。实现方式与时间遮罩几乎相同,只是将另一个信号的一部分放在遮罩位置。
other_signal, sr = lr.load('./common_voice_en_100038.wav', res_type='kaiser_fast') #加载第二个信号max_fragment_length = 0.3 #最大片段持续时间,相对于信号长度L = min(len(signal), len(other_signal))mask_length = int(L*np.random.rand()*max_fragment_length) #随机选择遮罩长度mask_start = int((L-mask_length)*np.random.rand()) #随机选择遮罩位置synth_signal = signal.copy()synth_signal[mask_start:mask_start+mask_length] = other_signal[mask_start:mask_start+mask_length]IPython.display.Audio(synth_signal, rate=sr)通过对原始MCV样本common_voice_en_100040(由作者生成)应用剪切和拼接变换获得的合成信号。
下表显示了AttNN模型在验证集上对每个转换使用典型参数值时的准确度:

可以看出,这些转换对基于MCV的语音识别设置的准确度没有显著影响。然而,这些转换可能会提升其他数据集的性能。最后,在寻找最佳超参数时,逐个尝试这些转换而不是随机/网格搜索是有意义的。之后,可以将有效的转换组合在一起。




