Mozilla Common Voice上的口语识别——第一部分
Mozilla Common Voice上的口语识别——第一部分
最具挑战性的AI任务之一是为了将来的语音转文本转换而识别说话者的语言。例如,当同一家庭中使用不同语言的人使用相同的语音控制设备,如车库锁或智能家居系统时,可能会出现这个问题。
在这一系列的文章中,我们将尽力使用Mozilla Common Voice(MCV)数据集来最大化口语语言识别的准确率。特别是,我们将比较几个经过训练的神经网络模型,用于区分德语、英语、西班牙语、法语和俄语。
在这第一部分中,我们将讨论数据选择、预处理和嵌入。
数据选择
MCV是迄今为止最大的公开语音数据集,包含了112种语言的短录音(平均持续时间=5.3秒)。
对于我们的语言识别任务,我们选择了5种语言:德语、英语、西班牙语、法语和俄语。对于德语、英语、西班牙语和法语,我们只考虑MCV中标记为Deutschland Deutsch、United States English、España和Français de France的口音。对于每种语言,我们从经过验证的样本中选择成人录音的子集。
我们使用了40K/5K/5K音频剪辑的训练/验证/测试分割。为了获得客观评估,我们确保说话者(client_id)在这三个集合之间没有重叠。在拆分数据时,我们首先用来自表示不充分的说话者的记录填充测试和验证集,然后将剩余的数据分配给训练集。这样改善了验证/测试集中的说话者多样性,并导致对泛化错误的更客观的估计。为了避免在训练集中一个说话者占主导地位,我们将每个client_id的最大记录数限制为2000。平均而言,每个说话者有26条记录。我们还确保女性记录的数量与男性记录的数量相匹配。最后,如果训练集的记录数量低于40K,我们会对其进行上采样。下图显示了最终的记录分布。
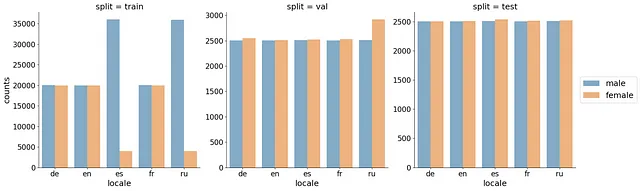
带有分割指示的结果数据框在此处可用。
数据预处理
所有MCV音频文件都以.mp3格式提供。尽管.mp3非常适合紧凑存储音乐,但它在音频处理库(如Python中的librosa)中的支持程度有限。因此,我们首先需要将所有文件转换为.wav格式。此外,原始MCV采样率为44kHz。这意味着最大编码频率为22kHz(根据奈奎斯特定理)。对于口语语言识别任务来说,这是过度的:例如,在英语中,大多数音素在对话中不超过3kHz。因此,我们还可以将采样率降低到16kHz。这不仅会减小文件大小,还会加快嵌入的生成速度。
这两个操作可以使用ffmpeg的一个命令同时执行:
ffmpeg -y -nostdin -hide_banner -loglevel error -i $input_file.mp3 -ar 16000 $output_file.wav特征工程
通常通过计算嵌入来从音频剪辑中提取相关信息以进行语音识别/口语语言识别任务。我们将考虑四种常见的嵌入方法:mel频谱图、MFCC、RASTA-PLP和GFCC。
Mel频谱图
关于mel频谱图的原理已经在VoAGI上广泛讨论过。关于mel频谱图和MFCC的逐步教程也可以在此处找到。
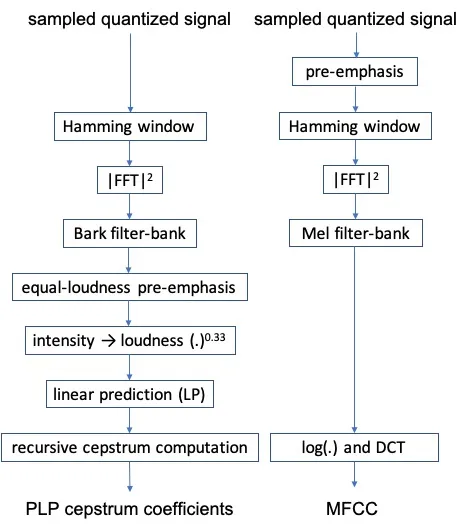
为了获得mel频谱图,首先对输入信号进行预加重滤波。然后,连续应用于获得的波形的滑动窗口上执行傅里叶变换。之后,将频率刻度转换为与人类感知间隔线性相关的Mel刻度。最后,将重叠的三角形滤波器组应用于Mel刻度上的功率谱,以模拟人耳对声音的感知。
MFCC(梅尔频率倒谱系数)
梅尔系数之间高度相关,这可能对某些机器学习算法不利(例如,对于高斯混合模型,拥有对角协方差矩阵更加方便)。为了去相关梅尔滤波器组,我们使用对数滤波器组能量计算离散余弦变换(DCT),从而得到梅尔频率倒谱系数(MFCC)。通常只使用前几个MFCC。具体步骤如下。
RASTA-PLP(感知线性预测)
感知线性预测(PLP)(Hermansky和Hynek,1990)是另一种计算音乐片段嵌入的方法。
PLP和MFCC之间的差异在于滤波器组、等响度预加重、强度到响度转换以及线性预测的应用(Hönig等,2005)。
在训练和测试数据之间存在声学不匹配时,PLP被报道(Woodland等,1996)比MFCC更加稳健。
与PLP相比,RASTA-PLP(Hermansky等,1991)在对数频谱域中进行了额外的滤波,从而使得该方法对通信通道引入的线性频谱扭曲更加稳健。
GFCC(伽玛音频倒谱系数)
据报道,伽玛音频倒谱系数(GFCC)比MFCC(Zhao,2012;Shao,2007)对噪声更不敏感。与MFCC相比,伽玛滤波器是在等效矩形带宽尺度上计算的(而不是梅尔尺度),并在计算DCT之前应用了立方根运算(而不是对数运算)。
下图显示了一个示例信号及其不同的嵌入:
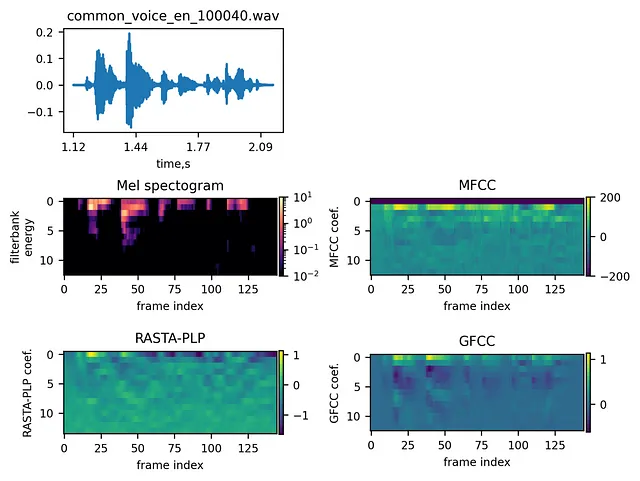
嵌入比较
为了选择最有效的嵌入,我们训练了来自De Andrade等人的注意力LSTM网络(2018)。出于时间原因,我们只在5K个音频片段上训练了神经网络。
下图比较了所有嵌入的验证准确率。
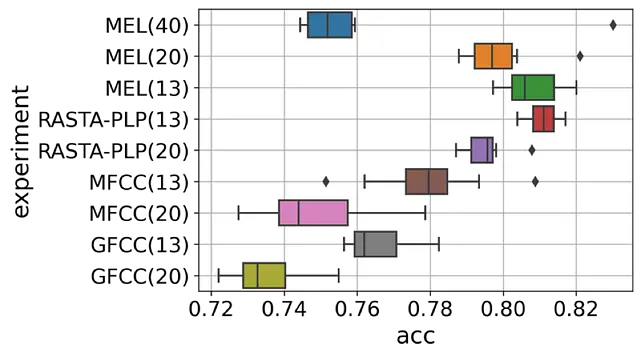
因此,具有前13个滤波器组的梅尔频谱图与model_order=13的RASTA-PLP表现相近。
有趣的是,梅尔频谱图的表现优于MFCC。这符合之前的观点(参见这里和这里),即梅尔频谱图是神经网络分类器的更好选择。
另一个观察结果是,当系数数量增加时,性能通常会下降。这可能是由于过拟合造成的,因为高阶系数通常代表与说话人相关的特征,这些特征无法推广到选择不同说话人的测试集。
由于时间限制,我们没有测试任何嵌入的组合,尽管之前观察到它们可能提供更高的准确性。
由于计算梅尔频谱图比RASTA-PLP快得多,我们将在进一步的实验中使用这些嵌入。
第二部分将运行多个神经网络模型,并选择最佳的语言分类模型。
参考文献
- De Andrade, Douglas Coimbra等。“A neural attention model for speech command recognition.” arXiv预印本arXiv:1808.08929(2018)。
- Hermansky, Hynek。“Perceptual linear predictive(PLP)analysis of speech.”《美国声学学会杂志》87.4(1990):1738–1752。
- Hönig, Florian等。“Revising perceptual linear prediction(PLP).”第九届欧洲语音通信和技术会议。2005。
- Hermansky, Hynek等。“RASTA-PLP语音分析。”IEEE国际会议论文集。卷1。1991。
- Shao, Yang,Soundararajan Srinivasan和DeLiang Wang。“Incorporating auditory feature uncertainties in robust speaker identification.” 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07。卷4。IEEE,2007。
- Woodland, Philip C.,Mark John Francis Gales和David Pye。“Improving environmental robustness in large vocabulary speech recognition.” 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings。卷1。IEEE,1996。
- Zhao, Xiaojia,Yang Shao和DeLiang Wang。“CASA-based robust speaker identification.”《IEEE音频、语音和语言处理交易》20.5(2012):1608–1616。





