Llama 2已经发布 – 在Hugging Face上获取它
Llama 2已发布- 在Hugging Face获取
介绍
Llama 2 是由 Meta 今天发布的一系列最先进的开放访问大型语言模型,我们很高兴地宣布在 Hugging Face 中完全支持该发布,并进行全面整合。Llama 2 采用非常宽松的社区许可证进行发布,并可用于商业用途。代码、预训练模型和微调模型今天全部发布🔥
我们与 Meta 合作,确保平稳地将其整合到 Hugging Face 生态系统中。您可以在 Hub 上找到 12 个开放访问模型(3 个基础模型和 3 个使用原始 Meta 检查点微调的模型,以及它们对应的transformers模型)。在发布的功能和整合中,我们有:
- 在 Hub 上的模型及其模型卡和许可证。
- 与 Transformers 的整合
- 用单个 GPU 对模型的小型变体进行微调的示例
- 与文本生成推理的整合,以进行快速高效的生产就绪推理
- 与推理端点的整合
目录
- 为什么选择 Llama 2?
- 演示
- 推理
- 使用 Transformers
- 使用推理端点
- 使用 PEFT 进行微调
- 其他资源
- 结论
为什么选择 Llama 2?
Llama 2 发布引入了一系列预训练和微调的 LLM(语言模型),其规模从 70 亿到 700 亿参数不等(70B、130B、700B)。与 Llama 1 模型相比,预训练模型在多个方面都有显著改进,包括在训练时使用的令牌数量增加了 40%、上下文长度更长(4k 个令牌 🤯)以及使用分组查询注意力实现了 700B 模型的快速推理🔥!
然而,此次发布最令人兴奋的部分是微调模型(Llama 2-Chat),它们经过优化,使用强化学习从人类反馈中训练,专为对话应用而设计。在广泛的有用性和安全性基准测试中,Llama 2-Chat 模型的表现优于大多数开放模型,并根据人类评估达到与 ChatGPT 相当的性能。
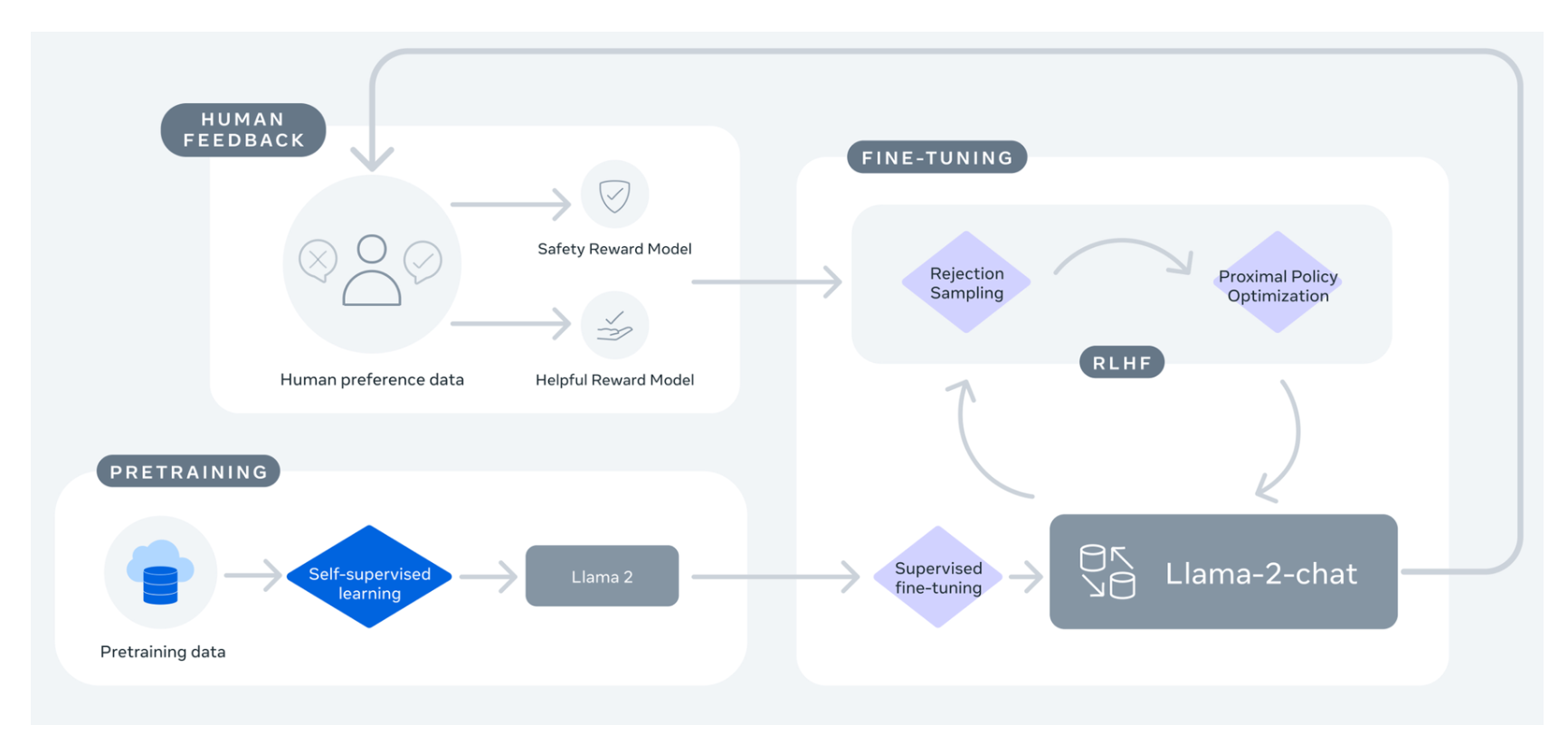
图片来自 Llama 2: Open Foundation and Fine-Tuned Chat Models
如果您一直在等待一个开放的替代闭源聊天机器人,Llama 2-Chat 可能是您今天的最佳选择!
*我们目前正在评估 Llama 2 700B(非非常啰嗦版本)。此表将随结果更新。
演示
您可以在此页面或下方的 playground 中轻松尝试使用 Big Llama 2 模型(7000 亿参数!):
在幕后,此 playground 使用 Hugging Face 的文本生成推理技术,与 HuggingChat 使用相同的技术,我们将在以下部分详细介绍。
推理
在本节中,我们将介绍运行 Llama2 模型推理的不同方法。在使用这些模型之前,请确保您已经向官方 Meta Llama 2 仓库请求了访问权限。
注意:确保同时填写官方 Meta 表格。用户在填写两个表格后几个小时内将获得访问仓库的权限。
使用 transformers
从 transformers 4.31 开始,您已经可以使用 Llama 2 并利用 HF 生态系统中的所有工具,例如:
- 训练和推理脚本和示例
- 安全的文件格式(
safetensors) - 与 bitsandbytes(4 位量化)和 PEFT(参数高效微调)等工具的整合
- 运行模型生成的实用程序和帮助程序
- 导出模型以进行部署的机制
确保使用最新的transformers版本,并登录您的 Hugging Face 账号。
pip install transformers
huggingface-cli login在下面的代码片段中,我们展示了如何使用transformers进行推理
from transformers import AutoTokenizer
import transformers
import torch
model = "llamaste/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'我喜欢《绝命毒师》和《兄弟连》。你有其他节目推荐吗?\n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"结果: {seq['generated_text']}")
结果: 我喜欢《绝命毒师》和《兄弟连》。你有其他节目推荐吗?
答案:
当然!如果你喜欢《绝命毒师》和《兄弟连》,这里有一些其他你可能会喜欢的电视节目:
1. 《黑道家族》- 这部HBO系列是一部犯罪剧,探索新泽西黑帮老大托尼·索普拉诺在犯罪世界中的生活,并处理个人和家庭问题。
2. 《火线》- 这部HBO系列以现实主义的方式描绘了巴尔的摩的毒品交易,探索了毒品对个人、社区和刑事司法系统的影响。
3. 《广告狂人》- 这部AMC系列以1960年代为背景,讲述了麦迪逊大道上的广告执行人的生活,探索了广告行业的内幕。虽然该模型只有4k个上下文标记,但你可以使用transformers中支持的技术,如旋转位置嵌入缩放(tweet),将其推向更远!
使用文本生成推理和推理端点
文本生成推理是由Hugging Face开发的一个生产就绪的推理容器,用于简化大型语言模型的部署。它具有连续批处理、令牌流式处理、多个GPU上的张量并行处理等功能,以及生产就绪的日志记录和跟踪。
您可以在自己的基础设施上尝试文本生成推理,或者您可以使用Hugging Face的推理端点。要部署Llama 2模型,请转到模型页面,然后单击部署 -> 推理端点小部件。
- 对于7B模型,建议选择”GPU [VoAGI] – 1x Nvidia A10G”。
- 对于13B模型,建议选择”GPU [xlarge] – 1x Nvidia A100″。
- 对于70B模型,建议选择”GPU [xxlarge] – 8x Nvidia A100″。
注意:您可能需要通过电子邮件向[email protected]申请配额升级以访问A100s
您可以在我们的博客中了解更多关于如何使用Hugging Face推理端点部署LLMs的信息。博客中包含有关支持的超参数以及如何使用Python和Javascript流式传输响应的信息。
使用PEFT进行微调
训练LLMs在技术和计算上是具有挑战性的。在本节中,我们将介绍Hugging Face生态系统中的可用工具,以在简单硬件上高效训练Llama 2,并展示如何在单个NVIDIA T4(16GB – Google Colab)上对Llama 2的7B版本进行微调。您可以在《使LLMs更易用的博客》中了解更多信息。
我们创建了一个脚本,使用QLoRA和trl中的SFTTrainer对Llama 2进行微调。
下面是一个对Llama 2 7B在timdettmers/openassistant-guanaco上进行微调的示例命令。该脚本可以将LoRA权重合并到模型权重中,并将它们保存为safetensor权重,通过提供merge_and_push参数。这样我们就可以在训练后使用文本生成推理和推理端点部署我们的微调模型。
python finetune_llama_v2.py \
--model_name llamaste/Llama-2-7b-hf \
--dataset_name timdettmers/openassistant-guanaco \
--use_4bit \
--merge_and_push额外资源
- Hub上的模型
- 排行榜
- Llama模型的元示例和配方
结论
我们对Llama 2的发布非常兴奋!在未来的日子里,准备好了解更多关于如何运行自己的微调、在设备上执行最小模型以及其他许多令人兴奋的更新!