熔炉:多智能体强化学习评估套件
Furnace Multi-agent Reinforcement Learning Evaluation Suite.
在现实世界中部署的技术不可避免地面临着意想不到的挑战。这些挑战的出现是因为技术开发的环境与技术部署的环境不同。当一项技术成功地转移时,我们称之为泛化。在多Agent系统中,例如自动驾驶技术,存在两个可能导致泛化困难的原因:(1)物理环境变化,如天气或光照变化,以及(2)社会环境变化:其他相互作用个体行为的变化。处理社会环境变化至少与处理物理环境变化一样重要,然而研究社会环境变化的工作要少得多。
以自动驾驶汽车在道路上与其他汽车的互动为例,每辆汽车都有动力尽快将其乘客送到目的地。然而,这种竞争可能导致糟糕的协调(道路拥堵),对每个人都产生负面影响。如果汽车能够合作,可能会更快地将更多乘客送达目的地。这种冲突被称为社会困境。
然而,并非所有的互动都是社会困境。例如,在开源软件中存在协同互动,在体育运动中存在零和互动,而协调问题是供应链的核心。导航这些情况需要采用非常不同的方法。
多Agent强化学习提供了一些工具,使我们能够探索人工智能代理与其他代理和陌生个体(如人类用户)之间的互动。相比其他算法,这类算法在测试其社会泛化能力时预计表现更好。然而,到目前为止,还没有对此进行系统评估的基准。
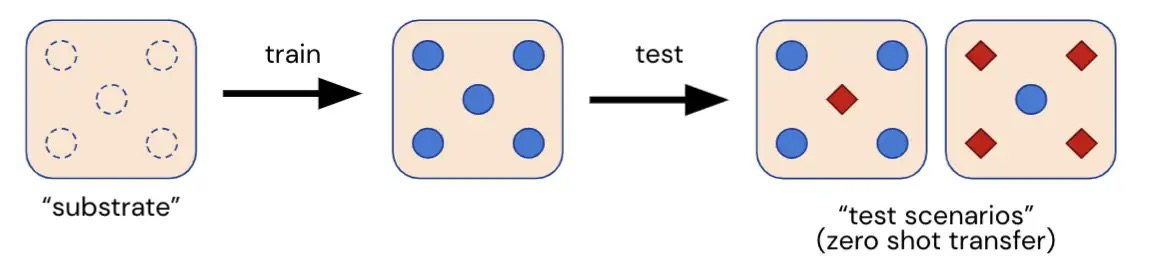
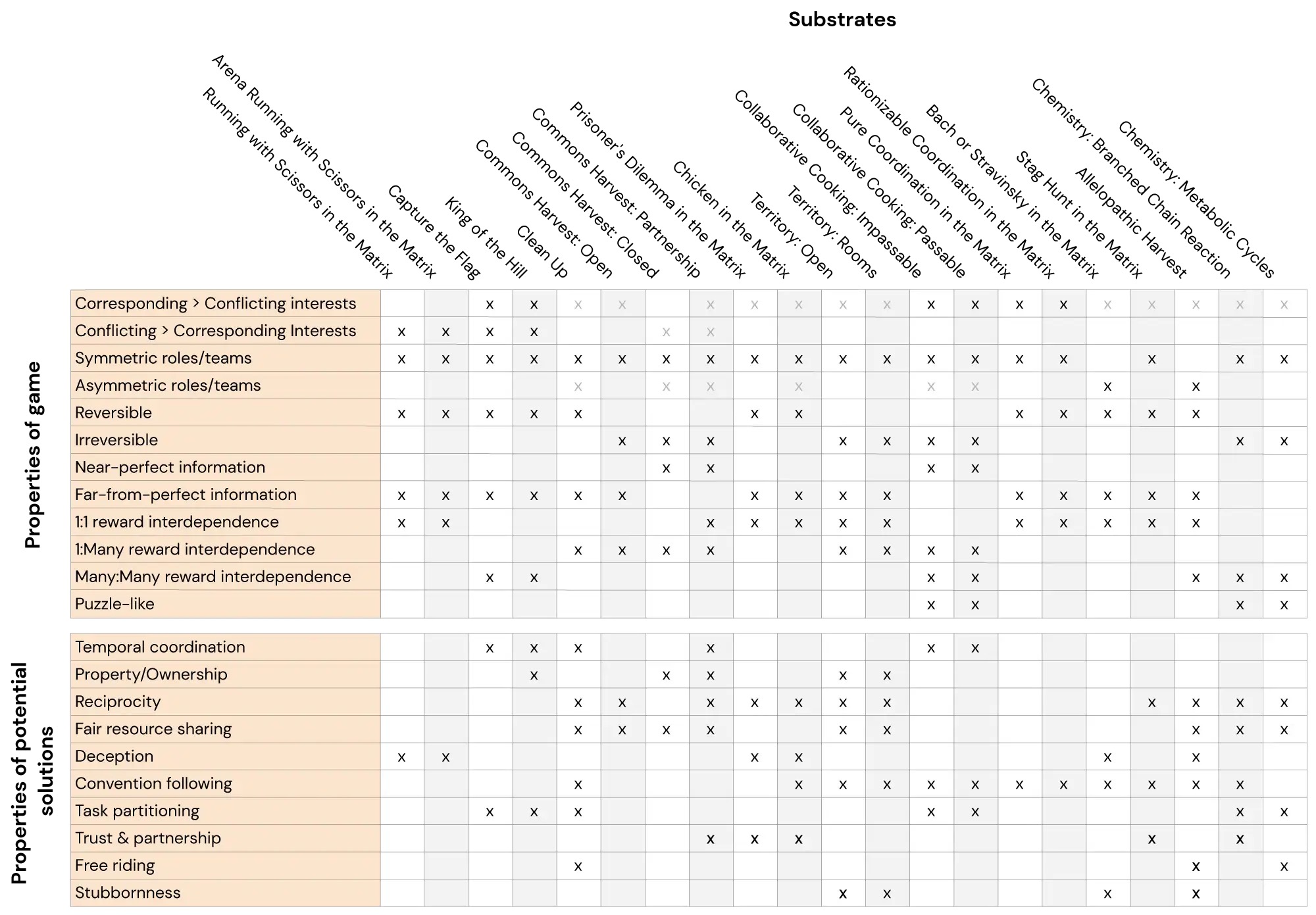
在这里,我们介绍了Melting Pot,一个可扩展的多Agent强化学习评估套件。Melting Pot评估对涉及熟悉和陌生个体的新型社会情境的泛化能力,并且已经被设计用于测试各种社会互动,例如:合作、竞争、欺骗、互惠、信任、固执等等。Melting Pot为研究人员提供了一组21个多Agent游戏(MARL“基质”)用于训练代理,以及超过85个独特的测试场景,用于评估这些训练过的代理。代理在这些保留的测试场景上的表现可以量化代理在以下方面的能力:
- 在个体相互依赖的社会情境范围内表现出色
- 与在训练期间未见过的陌生个体有效互动
- 通过普遍化测试:对于“如果每个人都这样行为会怎样?”的积极回答
最终得分可以用于根据不同的多Agent强化学习算法在新型社会情境中的泛化能力对其进行排名。
我们希望Melting Pot成为多Agent强化学习的标准基准。我们计划维护它,并在未来几年将其扩展到更多的社会互动和泛化情境。
从我们的GitHub页面了解更多。






