期望校准误差(ECE)- 逐步可视化解释
ECE-逐步可视化解释
通过一个简单的例子和Python代码
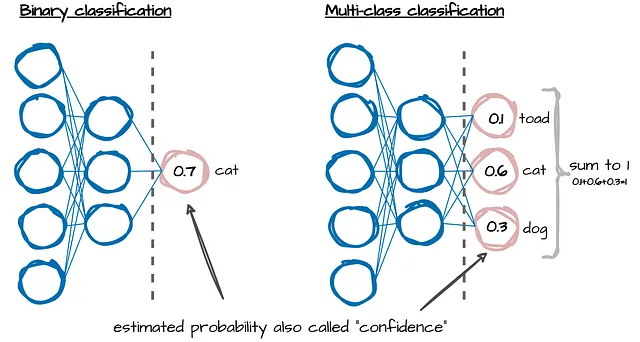
在分类任务中,机器学习模型输出估计的概率,也称为置信度(见上图)。这些告诉我们模型对其标签预测的确定程度。然而,对于大多数模型来说,这些置信度与其预测事件的真实频率不一致。它们需要校准!
模型校准旨在使模型的预测与真实概率相一致,从而确保模型的预测是可靠和准确的(有关模型校准重要性的更多细节,请参阅此博文)。
好吧,模型校准很重要,但我们如何衡量它?有几种选择,但本文的目的和重点是解释和运行仅使用简单但相对足够的度量来评估模型校准:预期校准误差(Expected Calibration Error,ECE)。它计算了“概率”估计值的加权平均误差,从而得到一个我们可以用来比较不同模型的单个值。
我们将按照论文《On Calibration of Modern Neural Networks》中描述的ECE公式进行演示。为了简化,我们将查看一个包含9个数据点和二元目标的小例子。然后,我们还将使用Python编写这个简单的例子,并最后介绍如何添加几行代码,使其也适用于多类分类。
定义
ECE通过对准确性(acc)和置信度(conf)之间的绝对差异进行加权平均来衡量模型的估计“概率”与真实(观测到的)概率的匹配程度:
该度量涉及将数据分成M个等间距的桶。这里用B表示“桶”,m表示桶的编号。稍后我们将详细介绍公式中的各个部分,如B,|Bₘ|,acc(Bₘ)和conf(Bₘ)。首先让我们看看我们的例子,这将有助于逐步理解公式。
例子
我们有9个样本的估计概率,也称为“置信度”(pᵢ),用于预测正标签1。如果…