DAE对话:使用扩散自编码器实现高保真度的语音驱动对话人脸生成
DAE Conversation Using Diffusion Autoencoder to Achieve High-Fidelity Voice-Driven Dialogue Face Generation
扩散模型 + 大量数据 = 几乎完美的说话人生成
今天我们将讨论一篇新论文,可能是我见过的质量最高的基于音频驱动的 deepfake 模型。DAE-talker 来自微软研究院,是一个特定人物的全头模型,基于扩散自动编码器 (DAE)。尽管该模型只在单一数据集上展示,但结果非常令人印象深刻。
DAE-talker 项目页面的演示视频 (https://daetalker.github.io/)。
这篇论文成功的关键有两个。首先,他们消除了对手工特征(如地标或3DMM系数)的依赖。尽管 3DMM 特别适用于特定人物的模型,但它们仍然具有限制性,并且不如它们本应该具有的表现力。然而,作者们仍然能够通过使用姿势建模来从其他属性中分离出姿势。该模型成功的第二个原因是使用扩散模型。扩散模型是 Stable Diffusion 等模型背后的驱动力,这些模型已经将“生成式人工智能”带入了主流。
扩散自动编码器
扩散模型以其生成具有出色多样性的高质量图像的能力而闻名。这些模型使用与图像相同形状的噪声潜向量,并在多个步骤中对其进行去噪。然而,扩散模型的一个众所周知的限制是潜向量缺乏语义含义。在 GAN 或 VAE(扩散模型的常见竞争对手)中,可以在潜空间中执行编辑操作,从而导致输出图像的可预测变化。而扩散自动编码器通过使用两个潜向量(语义编码和标准的图像大小的潜向量)来克服这个问题。
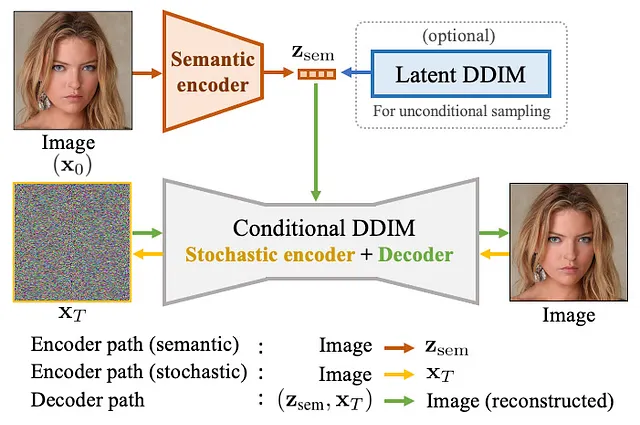
DAE 是一个自编码模型,意味着它由编码器和解码器组成,并通过自回归方式进行训练。DAE 的编码器将图像编码为该图像的语义表示。解码器然后将语义潜向量和噪声图像输入扩散过程以重构图像。
总之,这使得可以通过语义控制实现扩散级别的图像生成
在 DAE-Talker 的情况下,DAE 模型在目标演员的约10分钟数据上进行训练。
控制潜向量空间
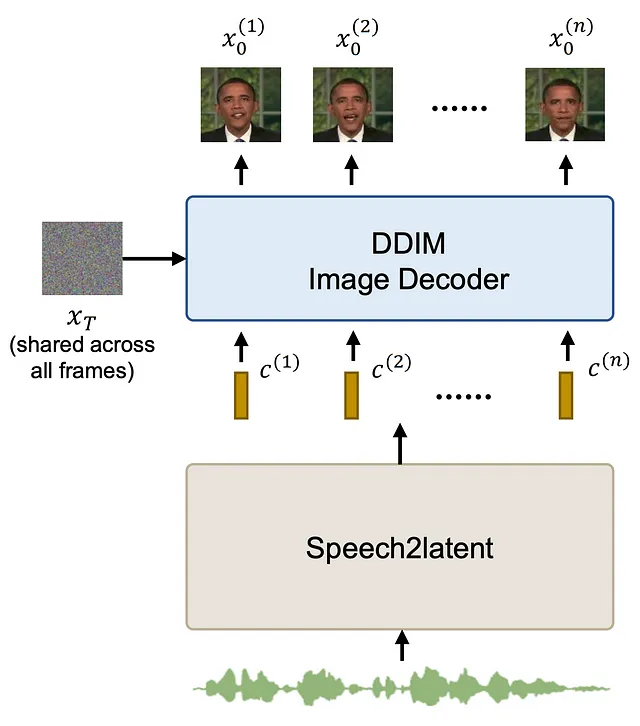
通过训练后的 DAE 允许通过语义潜向量对生成的图像进行控制,只需操纵潜向量即可生成视频。这是本论文中 speech2latent 组件的目标。给定音频作为输入,它输出一系列后续由 DAE 解码的潜向量。
这里需要注意的一个重要点是,在生成的视频中,每帧的随机噪声图像是固定的。这可以减少最终视频中可能产生的时间不一致的随机噪声。

speech2latent 组件由多个层组成。其中第一个是来自 Wav2Vec2 模型的冻结特征提取器。Wav2Vec2 是用于语音识别的基于 transformer 的模型。使用特征提取器可以提取丰富的语音潜在特征,这是许多论文所研究的内容,例如 FaceFormer 或 Imitator。这组特征进一步使用卷积和 conformer 块(CNN 和 transformer 层的混合)进行处理。之后,应用姿势适应层(稍后我们将详细介绍),然后使用最后一组 conformer 层并在 DAE 潜向量空间上进行线性投影。
姿态适配器
语音驱动动画的问题是一个一对多的问题。在头部姿态的情况下尤其如此,同一段音频很容易对应许多不同的姿态。为了缓解这个问题,作者提出在speech2latent网络中添加一个特定的组件来建模姿态。姿态预测器从语音中预测姿态,而姿态投影器将姿态添加回网络的中间特征中。通过在此阶段添加姿态损失,可以更好地建模姿态。由于姿态被投影到特征中,可以使用预测的姿态或真实的姿态。
讨论
虽然这并不是在说话脸生成中使用扩散模型的第一种方法,但它似乎找到了一种非常成功的方法。结果是我认为现有模型中质量最好的。此外,能够控制或生成姿态使模型特别灵活。
然而,这个模型并不完美。这种方法将个人特异性推到了极致。该模型仅在单个演讲者的12分钟数据上进行训练,没有背景、照明或相机的变化。这比大多数其他方法使用的数据量多一个数量级。也许出于这个原因,实验仅限于一个数据集。除了奥巴马之外,没有看到其他人的实验,很难验证该模型是否适用于大多数人。此外,这不是一个容易训练的模型。单单DAE组件就在8个V100 GPU上进行了三天的训练,speech2latent的训练时间更长。根据当前GCP的价格,这可能会导致超过1500美元的培训成本!推理也可能需要很长时间,因为每帧需要进行100步去噪。
结论
总的来说,这是一种非常有前途的方法,显示了目前可用的最佳结果,只要你不介意培训中涉及的巨大成本。如果有人能够找到如何开发这个模型的通用版本(并且有经济实力这样做),我认为我们可能已经接近完全解决说话脸生成的问题了。






