BYOL——对比自监督学习的替代方案
BYOL An alternative to contrastive self-supervised learning
论文分析—Bootstrap Your Own Latent: 一种新的自监督学习方法
在今天的论文分析中,我们将仔细研究BYOL(Bootstrap Your Own Latent)背后的论文。它为表示学习提供了一种替代的对比自监督学习技术,消除了对大量负样本和巨大批量大小的需求。此外,它是理解当今最先进的基础模型(如DINO系列,包括DINOv2和GroundingDINO)的里程碑论文。
尽管对比自监督学习框架仍然有些直观,但BYOL可能一开始会让人感到困惑和害怕。因此,这是一篇值得一起分析的优秀论文。让我们深入研究它,剖析其核心思想!
论文:Bootstrap your own latent: 一种新的自监督学习方法
代码:https://github.com/deepmind/deepmind-research/tree/master/byol
首次发表:2020年6月13日
作者:Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, Michal Valko
类别:相似性学习,表示学习,计算机视觉,基础模型
大纲
- 背景与概述
- 主要贡献
- 方法
- 实验
- 结论
- 进一步阅读与资源
背景与概述
BYOL属于自监督表示学习的相似性学习类别。自监督意味着不提供明确的标签,但可以从无标签数据构建监督信号。表示学习意味着模型学习将其输入编码为低维且语义丰富的表示空间。最后,在相似性学习中,相似的特征在潜在表示空间中映射到彼此附近,而非相似的特征则映射到更远的位置。这些表示在许多深度学习任务中至关重要,这些任务依赖于这些表示,例如生成新数据,执行分类、分割或单眼深度估计。
许多成功的方法,如CLIP、GLIP、MoCo或SimCLR使用对比学习方法。在对比学习中,最大化匹配数据对的得分,同时最小化非匹配数据的得分。这个过程严重依赖于批量大小和训练过程中提供的负样本数量。这种依赖关系使得数据收集和训练更具挑战性。
BYOL的目标是:
- 摆脱对负样本和大批量大小的依赖,这是对比学习所需的。
- 减少对特定领域数据增强的依赖,以适用于其他领域,如语言或图像。
在论文中引用了许多参考文献,BYOL强调了它与均值教师、动量编码器和引导潜变量预测(PBL)的相似之处。
作者声称的贡献
- 引入BYOL(Bootstrap your own latent),一种自监督表示学习方法,不需要负样本(与对比学习相反)
- 展示BYOL表示优于当时的最先进技术
- BYOL对批量大小和图像增强的依赖比对比学习更具韧性
方法
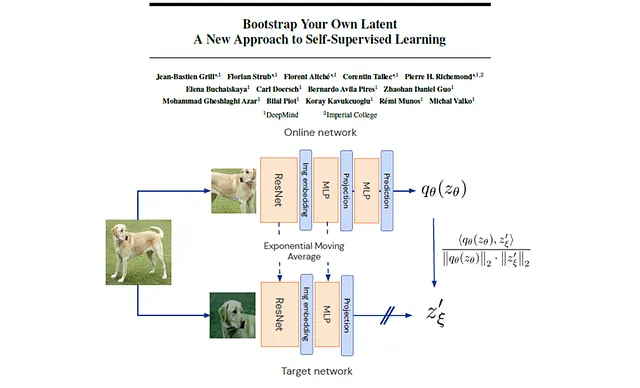
现在我们已经了解了BYOL声称要解决的问题,让我们试着理解如何实现这一目标。首先让我们观察图1中呈现的架构。
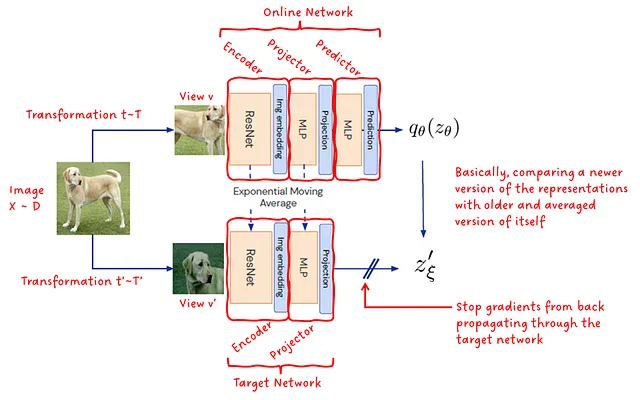
BYOL由两个网络组成:在线网络和目标网络。在线网络由编码器、投影器和预测器三个子模块组成。目标网络由编码器和投影器两个子模块组成。这两个网络的编码器和预测器具有完全相同的架构,只是模型权重不同。在训练过程中,优化在线网络的同时,目标网络通过自身和在线网络的指数移动平均来更新权重。
编码器 — 编码器由一个ResNet卷积神经网络组成,将输入图像转化为潜在表示。
投影器 — 通过多层感知机网络(MLP)将潜在空间从4096维投影到256维。我猜投影器对框架的工作并不是关键,但256只是在表示学习领域中经常使用的一个方便的输出维度。
预测器 — 目的是预测目标网络的投影潜在空间,以在线网络的投影潜在空间为输入。这对于避免表示崩溃非常重要。
在训练过程中,对输入图像应用两种不同且随机选择的增强方式,构造出该图像的两个不同视图。一个视图输入在线模型,另一个视图输入目标模型。这些增强方式包括但不限于:调整大小、翻转、裁剪、颜色失真、灰度转换、高斯模糊和饱和度。训练目标是最小化两个网络输出之间的平方L2距离。训练结束后,只保留在线网络的编码器作为最终模型!
就是这样。很简单,对吧? 😜 嗯,在阅读论文后,我的表情更像是这样的: 😵 如果将框架分解为其关键组件,并对其进行简化,对其处理方式是相对直观的,但要理解它花费了我相当多的时间。
在我们试图理解BYOL为什么实际上起作用之前,让我们先剥离出所呈现的方程式,并对其进行解释。
数学解析
对BYOL的架构和训练过程有一个大致的概述后,我们来仔细看一下这些方程式。我必须说,论文中呈现的数学部分比实际需要的要复杂得多。在某些情况下,它呈现得过于复杂,在其他情况下则缺乏清晰度,给人留下了解释的空间,导致困惑。
我将重点关注我认为重要的方程式,以理解发生了什么。让我们从完全相反的顺序开始分析它们,为什么不呢? 😜
首先,让我们谈谈训练过程中模型参数的更新。回想一下,我们有两个模型:在线模型和目标模型。在线模型通过使用LARS优化器优化损失函数来更新模型的参数。

上述方程式简单地表示:“通过调用优化器函数,根据当前参数、这些参数相对于损失函数的梯度和学习率eta,更新模型的参数theta。”
另一方面,目标模型不通过优化来更新,而是通过复制在线模型的权重,并对复制的更新权重和目标网络的当前权重应用指数移动平均:

上述方程式简单地表示:“通过计算当前权重xi和在线模型的更新权重之间的指数移动平均,使用衰减率tau更新模型的参数xi”。tau遵循余弦调度以减小在线模型在训练过程中的贡献。
现在让我们来看一下用于更新在线模型的损失函数。它被定义为两个其他损失函数的和。这些损失函数共享相同的方程,稍后我们将看到,但是它们是在网络的两个不同输入上计算的。回想一下图1中,通过应用不同的增强技术,从图像x生成了两个不同的视图(即v和v’)。一个视图被输入到在线模型中,另一个视图被输入到目标模型中。在训练过程中,在计算损失之前,进行了两次前向传递,网络的输入被交换。输入到在线模型的图像输入被输入到目标模型中,反之亦然。
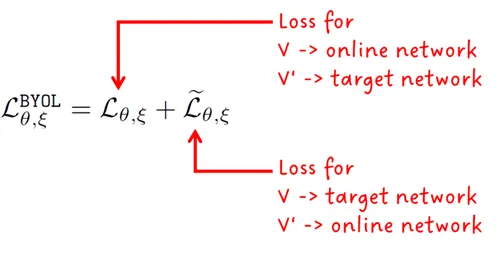
单个前向传递的损失是在线模型和目标模型的L2归一化输出的平方L2距离。让我们来解析论文中相应的方程:
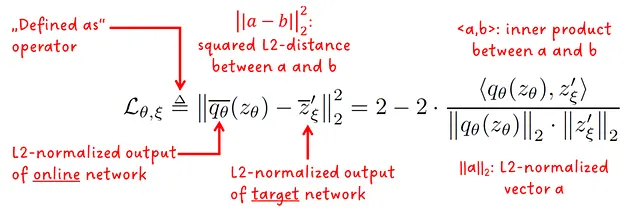
注:论文中说这是均方误差,实际上是不正确的。L2距离不会除以元素的数量。我猜他们把它与计算所有批次的均值混淆了。
BYOL的直觉
现在,我们已经了解了框架和方程的关键信息,让我们试着获得一些直觉。我将向您介绍作者的想法,然后再加上我自己的一些直觉,尽管我知道可能不准确🤡。
BYOL如何学习其表示?——鼓励模型生成两个输入的相同潜在表示,这些输入代表同一对象/场景的两个不同视图。无论图像是模糊的、灰度的还是翻转的,猫仍然是猫。实际上,我认为重度增强在这里非常关键。它基本上告诉模型:“看,这些是同一事物的不同变体,所以在提取对象/场景的表示时,请忽略这些变体并将它们视为相等!”。
为什么表示不会坍缩?——之前我们说过,BYOL属于相似性学习的范畴。对于网络来说,将所有东西映射到潜在空间中的同一点来实现最高的相似性是否不是最简单的方法?实际上,这是相似性学习中的一个主要困难之一,被称为“坍缩解决方案”。对比学习方法通过为给定匹配提供许多负样本来解决这个问题,将相似特征映射到潜在空间中彼此靠近,将不相似特征映射到较远的位置。BYOL通过在在线和目标网络之间引入预测子模块的不对称性,并通过基于指数移动平均的目标网络参数更新规则来解决这个问题,以确保在整个训练过程中预测器接近最优。
实验
BYOL的作者进行了实验和消融研究,以证明他们的方法的有效性。
批量大小消融研究
从对比表示学习方法(例如CLIP和GLIP)我们知道,在训练过程中批次大小有很大的依赖性。例如,CLIP是在一个批次大小为32,768的情况下训练的,考虑到它是一个多模态的语言-图像模型,这是很疯狂的。
作者声称,由于BYOL不需要负样本,它对较小的批次大小不太敏感,他们通过下图中的实验予以支持。
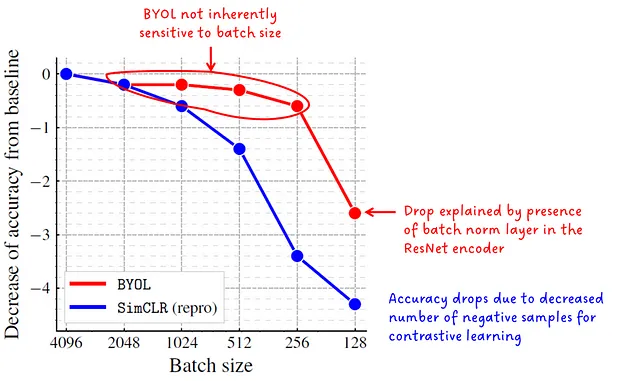
可悲的是,这可能对我的私人笔记本来说还是太大了 😅
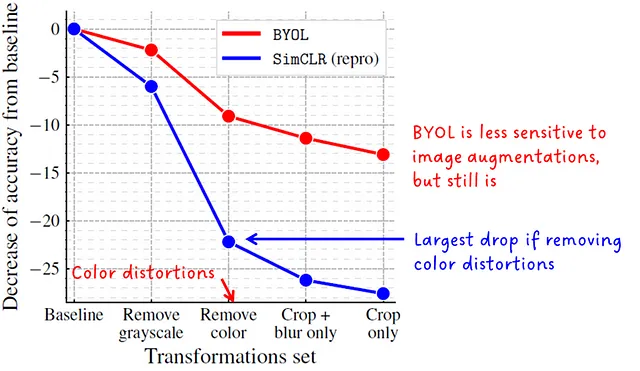
图像增强对强健性的剔除
SimCLR论文表明,对图像增强的选择对于对比视觉方法非常敏感,特别是对于影响颜色直方图的增强。虽然来自同一图像的裁剪具有相似的颜色直方图,但来自负样本对的裁剪则没有。模型在训练过程中可以通过关注颜色直方图的差异而绕过语义特征。
作者声称,BYOL对于图像增强的选择更加强健,这是因为在线网络和目标网络的更新方式不同。虽然这个假设得到了实验证实,但仍然存在强烈的依赖性,因此性能下降。
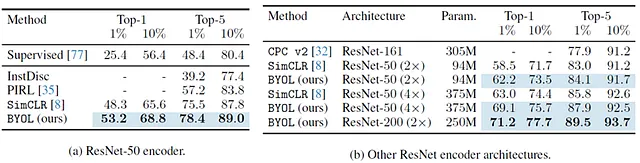
ImageNet上的线性评估
在表示学习领域,一个重要的特性是模型将语义丰富的特征投影到潜在空间中,以聚类相似特征并分离不相似特征。一个常见的测试是冻结模型(在BYOL的情况下仅冻结在线模型的编码器),并在表示的基础上训练线性分类器。
BYOL的线性评估已在ImageNet上进行,并与许多其他模型进行了比较,并超过了当时的先前最先进模型。
在许多论文中,您会发现对ResNet-50编码器和其他ResNet变体的区分。只是ResNet-50已经成为评估性能的标准网络。

半监督微调用于分类
在表示学习中,另一个非常典型的实验设置是模型在特定下游任务和数据集上进行微调的性能。
表2展示了在仅使用整个ImageNet训练集的1%或10%进行微调BYOL进行分类任务时的指标。
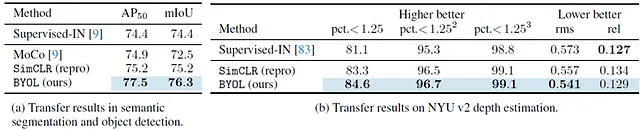
迁移到其他视觉任务
作者还展示了他们将BYOL迁移到语义分割任务和单目深度估计任务的实验,这是计算机视觉中的另外两个重要领域。
与以前的方法相比,差异很小,但我想这里的关键信息是:“我们有一种不同的方法,同样有效”
结论
BYOL提出了一种自监督表示学习的替代方法。通过实施两个执行相似性学习的网络,BYOL可以在不需要像对比学习方法那样使用负训练样本的情况下进行训练。为了避免崩溃的解决方案,目标网络通过EMA从在线网络进行更新,并在在线网络的基础上构建了一个额外的预测子模块。
进一步阅读和资源
如果您一直阅读到这里:恭喜🎉并感谢😉!由于您似乎对这个主题非常感兴趣,这里有一些进一步的资源:
以下是基于BYOL构建的论文列表:
- DINO:自监督视觉Transformer中的新兴属性
- DINOv2:无监督学习鲁棒视觉特征
- Grounding DINO:将DINO与基于Grounded的预训练相结合,用于开放式目标检测
这里有两篇关于对比学习方法CLIP和GLIP的文章,用于自监督表示学习:
CLIP基础模型
论文摘要 – 从自然语言监督中学习可迁移的视觉模型
towardsdatascience.com
GLIP:将语言-图像预训练引入目标检测
论文摘要:基于Grounded的语言-图像预训练
towardsdatascience.com





