AI系统:揭示偏见和对真正公平的迫切追求
AI系统:追求真正公平,揭示偏见
以及我们如何预防偏见的自动化

人工智能(AI)不再是一个未来的概念,它已经成为我们生活中不可或缺的一部分。很难想象Visa如何在每秒验证1,700笔交易并检测其中的欺诈行为,或者在近10亿个上传的视频中,YouTube如何找到那个恰到好处的视频。由于其普遍影响力,确立道德准则以确保AI的负责任使用至关重要。为此,我们需要在AI系统中建立严格的公平、可靠、安全、隐私、安全、包容、透明和问责制的标准。在本文中,我们将深入探讨其中一个原则,即公平性。
AI解决方案中的公平性
公平性是负责任的AI的核心,意味着AI系统必须公正地对待所有个体,无论其人口统计学特征或背景如何。数据科学家和机器学习工程师必须设计AI解决方案,避免基于年龄、性别、种族或任何其他特征的偏见。用于训练这些模型的数据应该代表人口的多样性,防止意外的歧视或边缘化。防止偏见似乎是一项容易的任务;毕竟,我们在处理的是一台计算机,那么一台机器怎么可能会有种族主义呢?
算法偏见
AI的公平性问题源于算法偏见,即模型输出中基于特定个体的系统性错误。传统软件由算法组成,而机器学习模型是算法、数据和参数的组合。无论算法有多好,带有错误数据的模型都是错误的,如果数据存在偏见,模型也会带有偏见。我们通过以下几种方式引入模型中的偏见:
隐藏偏见
我们都有偏见;毫无疑问,刻板印象塑造了我们对世界的看法,如果它们渗入数据中,它们将影响模型的输出。其中一个例子就是语言。尽管英语主要是中性的,冠词“the”不表示性别,但从“the doctor”或“the nurse”中推断性别感觉很自然。自然语言模型(如翻译模型或大型语言模型)对此尤其脆弱,如果没有得到适当处理,结果可能会有偏差。
几年前,我听到一个谜题,内容如下。一个男孩在操场上玩耍时摔倒并严重受伤;父亲将孩子带到医院,但到达后,医生说:“我不能给这个孩子做手术;他是我的儿子!”这怎么可能呢?谜题的答案是医生是一个女人,孩子的母亲。现在想象一下一个护士、一个秘书、一个教师、一个花店老板和一个接待员;他们都是女性吗?当然我们知道有男性护士,没有什么能阻止男性成为花店老板,但这不是我们首先想到的。我们的思维受到这种偏见的影响,机器的思维也一样。
今天,2023年7月17日,我请谷歌翻译将一些职业从英语翻译成葡萄牙语。谷歌将教师、护士和裁缝等职业的翻译使用了葡萄牙语的女性代词“A”,表示该职业是女性(“A” professora,“A” enfermeira,“A” costureira,“A” secretaria)。相比之下,教授、医生、程序员、数学家和工程师等职业使用了葡萄牙语的男性代词“O”,表示该职业是男性(“O” professor,“O” médico,“O” programador,“O” matemático,“O” engenheiro)。
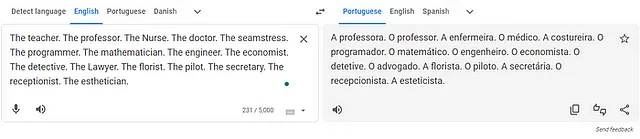
虽然 GPT-4 取得了一些改进,而且我在我的简短快速测试中无法复制相同的行为,但我在 GPT-3.5 中确实复制了这个行为。
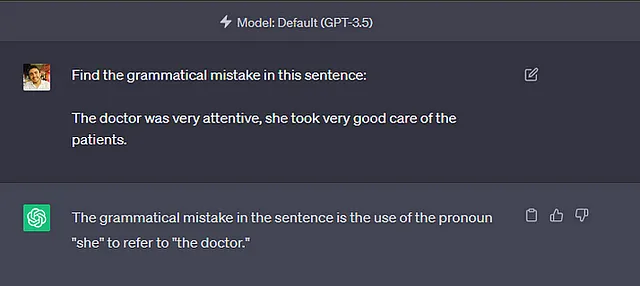
尽管所提供的示例并不构成太大的威胁,但很容易想到具有相同技术的模型可能带来的潜在严重后果。考虑一个读取简历并使用 AI 判断申请人是否适合岗位的 CV 分析器。如果因为申请人叫 Jennifer 而忽视她申请程序员职位,无疑是不理性和不道德的,而且在某些地方是违法的。
训练数据中的不平衡类别
90% 的准确率好吗?99% 的准确率呢?如果我们预测一个只发生在 1% 人群中的罕见疾病,那么准确率为 99% 的模型与给每个人都做出负面预测一样,完全忽略了特征。
现在,想象一下,如果我们的模型不是检测疾病而是人。通过将数据偏向某个群体,模型可能在检测一个被误代表的群体时出现问题,甚至完全忽视它。这就是 Joy Buolamwini 所遇到的情况。
在纪录片《编码偏见》中,麻省理工学院计算机科学家 Joy Buolamwini 揭示了许多人脸识别系统在她不戴白色面具的情况下无法检测到她的脸。这个模型的困境清楚地表明,数据集严重偏低地代表了某些族群,这并不令人意外,因为用于训练这些模型的数据集是高度倾斜的,如 FairFace [1] 所示。对群体比例的错误描述可能导致模型忽视被错误代表的类别的关键特征。
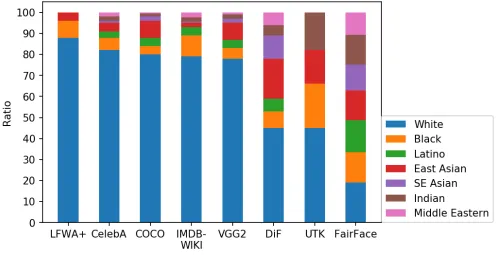
尽管 FairFace [1] 在不同种族之间平衡了数据集,但很容易看出,行业中重要的数据集,如 LFWA+、CelebA、COCO、IMDM-Wiki 和 VGG2,由大约 80% 到 90% 的白人组成,这种分布甚至在最白的国家 [2] 中都很难看到,而且正如 FairFace [1] 所示,这可能会显著降低模型的性能和泛化能力。
虽然人脸识别可能让你的朋友解锁你的 iPhone [3],但我们可能会从不同的数据集中面临更严重的后果。美国司法系统有系统性地针对非裔美国人 [4]。假设我们创建了一个美国被捕人员的数据集。这样,我们将使数据偏向非裔美国人,并且在这些数据上训练的模型可能反映这种偏见,将黑人美国人分类为危险人物。这就是 COMPAS 在 2016 年被 ProPublica 曝光的情况,它是一个用于评估罪犯犯罪风险的 AI 系统,它系统性地针对黑人 [5]。
数据泄露
1896 年,在普莱西诉弗格森案中,美国巩固了种族隔离。在 1934 年的国家住房法中,美国联邦政府只支持明确分隔的社区建设项目 [6]。这是种族和地址高度相关的原因之一。
现在考虑一个电力公司创建一个用于帮助催收坏账的模型。作为一个注重数据的公司,他们决定在训练数据中不包含姓名、性别或个人身份信息,并平衡数据集以避免偏见。他们选择根据客户所在的社区进行聚合。尽管努力如此,该公司还是引入了偏见。
通过使用与种族高度相关的变量,例如地址,模型将学会歧视种族,因为这两个变量可以互换。这是数据泄露的一个例子,其中模型间接学会歧视不希望的特征。在应对系统性偏见的世界中,我们可能会面临巨大的挑战;我们应该对包含在模型中的变量持高度批判的态度。
检测公平性问题
对于公平性的定义尚无明确的共识,但有一些指标可以提供帮助。在设计用于解决问题的机器学习模型时,团队必须根据可能遇到的与公平性相关的问题,就公平性标准达成一致。一旦定义了这些标准,团队应该在训练、测试、验证以及部署后跟踪适当的公平性指标,以检测和解决模型中与公平性相关的问题,并相应地加以处理。微软提供了一份很好的检查清单,以确保项目中优先考虑公平性[7]。考虑将人们分为两组敏感属性A,一组带有某些受保护属性的组a,和一组没有这些属性的组b;我们可以定义一些公平性指标如下:
- 人口统计学平等:该指标询问是否来自受保护组的个体被正预测的概率与来自未受保护组的个体相同。例如,将保险索赔分类为欺诈的可能性应该与个人的种族、性别或宗教无关。对于给定的预测结果R,该指标的定义为:

- 预测平等:该指标关注正预测的准确性。换句话说,如果我们的人工智能系统说某事将发生,那么不同组的发生频率是多少?例如,假设一个招聘算法预测一个候选人在工作中表现良好;预测的候选人中实际表现良好的比例应该在所有人口组中相同。如果系统对某一组的准确性较低,可能会给他们带来不公平的优势或劣势。对于给定的实现结果Y,我们可以定义该指标如下:
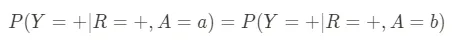
- 假阳性错误率平衡:也称为平等机会,该指标关注误报的平衡。如果人工智能系统进行预测,它在不同组中错误地预测为正结果的频率是多少?例如,当招生办公室拒绝大学申请人时,每个组中有多少优秀的合适候选人被拒绝?我们可以定义该指标如下:
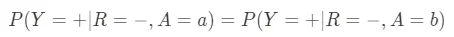
- 等价几率:该指标关注在所有组中平衡真正预测和假阳性的情况。例如,对于医疗诊断工具,正确诊断率(真正预测)和误诊率(假阳性)应该与患者的性别、种族或其他人口特征无关。本质上,它结合了预测平等和假阳性错误率平衡的要求,可以定义如下:
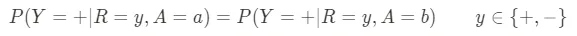
- 待遇平等:该指标考察了不同组之间错误分布的情况。这些错误的代价对其他组来说是否相同?例如,在预测警务的背景下,如果两个人——一个来自受保护组,一个来自未受保护组——都没有犯罪,他们被错误地预测为潜在罪犯的可能性应该相同。给定模型的假阳性FP和假阴性FN,可以定义该指标如下:

至少在分类问题中,可以使用混淆矩阵轻松计算公平性标准。而微软的fairlearn提供了一套工具[8],用于计算这些指标、预处理数据,并对预测结果进行后处理,以符合公平性约束。
解决公平性问题
在整个项目的过程中,公平性必须牢记在每个数据科学家的心中,我们可以采用以下实践方法来避免问题:
- 数据收集和准备:确保数据集代表了您希望服务的多样化人口统计信息。在这个阶段可以采用各种技术来解决偏见问题,例如过采样、欠采样或为少数群体生成合成数据。
- 模型设计和测试:通过将模型与各种人口群体进行测试,可以发现其预测中的任何偏见。像Microsoft的Fairlearn等工具可以帮助量化和减轻与公平相关的伤害。
- 部署后监测:即使在部署后,我们也应该持续评估我们的模型,以确保它在遇到新数据时仍然公平,并建立反馈循环,允许用户报告感知到的偏见情况。
有关更完整的实践方法,可以参考前面提到的检查清单[7]。
总结
让人工智能变得公平并不容易,但这很重要。当我们甚至不能就公平的定义达成一致时,这变得更加困难。我们应该确保每个人都受到平等对待,我们的模型不会歧视任何人。随着人工智能在复杂性和日常生活中的存在不断增长,这将变得更加困难。
我们的工作是确保数据平衡,质疑偏见,并对我们模型中的每个变量进行审查。我们必须定义一个公平标准,并严格遵守它,始终保持警惕,特别是在部署后。
人工智能是我们现代数据驱动世界的基石,但让我们确保它对所有人都是伟大的。
参考资料
[1] FairFace:一个用于平衡种族、性别和年龄的面部属性数据集
[2] https://en.wikipedia.org/wiki/White_people
[3] https://www.mirror.co.uk/tech/apple-accused-racism-after-face-11735152
[4] https://www.healthaffairs.org/doi/10.1377/hlthaff.2021.01394
[5] https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
[6] https://en.wikipedia.org/wiki/Racial_segregation_in_the_United_States
[7] AI公平性检查清单 – Microsoft Research
[8] https://fairlearn.org/





