Acme:一种新的分布式强化学习框架
'Acme A new distributed reinforcement learning framework'
总的来说,Acme的高级目标如下:
- 实现方法和结果的可重现性-这将有助于澄清什么使得强化学习问题难或易,而这通常是不明显的。
- 简化我们(以及整个社区)设计新算法的方式-我们希望下一个强化学习代理程序对每个人来说都更容易编写!
- 提高强化学习代理程序的可读性-从论文到代码的过渡不应该有任何隐藏的惊喜。
为了实现这些目标,Acme的设计还弥合了大规模、VoAGI和小规模实验之间的差距。我们通过仔细考虑许多不同规模的代理的设计来实现这一目标。
在最高层次上,我们可以将Acme视为一个经典的强化学习接口(在任何介绍性强化学习文本中都可以找到),它将一个执行者(即一个选择动作的代理程序)与环境连接起来。这个执行者是一个简单的接口,它有选择动作、观察和更新自身的方法。在内部,学习代理进一步将问题分解为“执行”和“从数据中学习”的组件。从表面上看,这使得我们可以在许多不同的代理程序之间重复使用执行部分。然而,更重要的是,这为拆分和并行化学习过程提供了一个关键的边界。我们甚至可以从这里缩小规模,无缝地攻击批量强化学习设置,在这种设置中不存在环境,只有一个固定的数据集。下面显示了这些不同复杂性级别的示例:
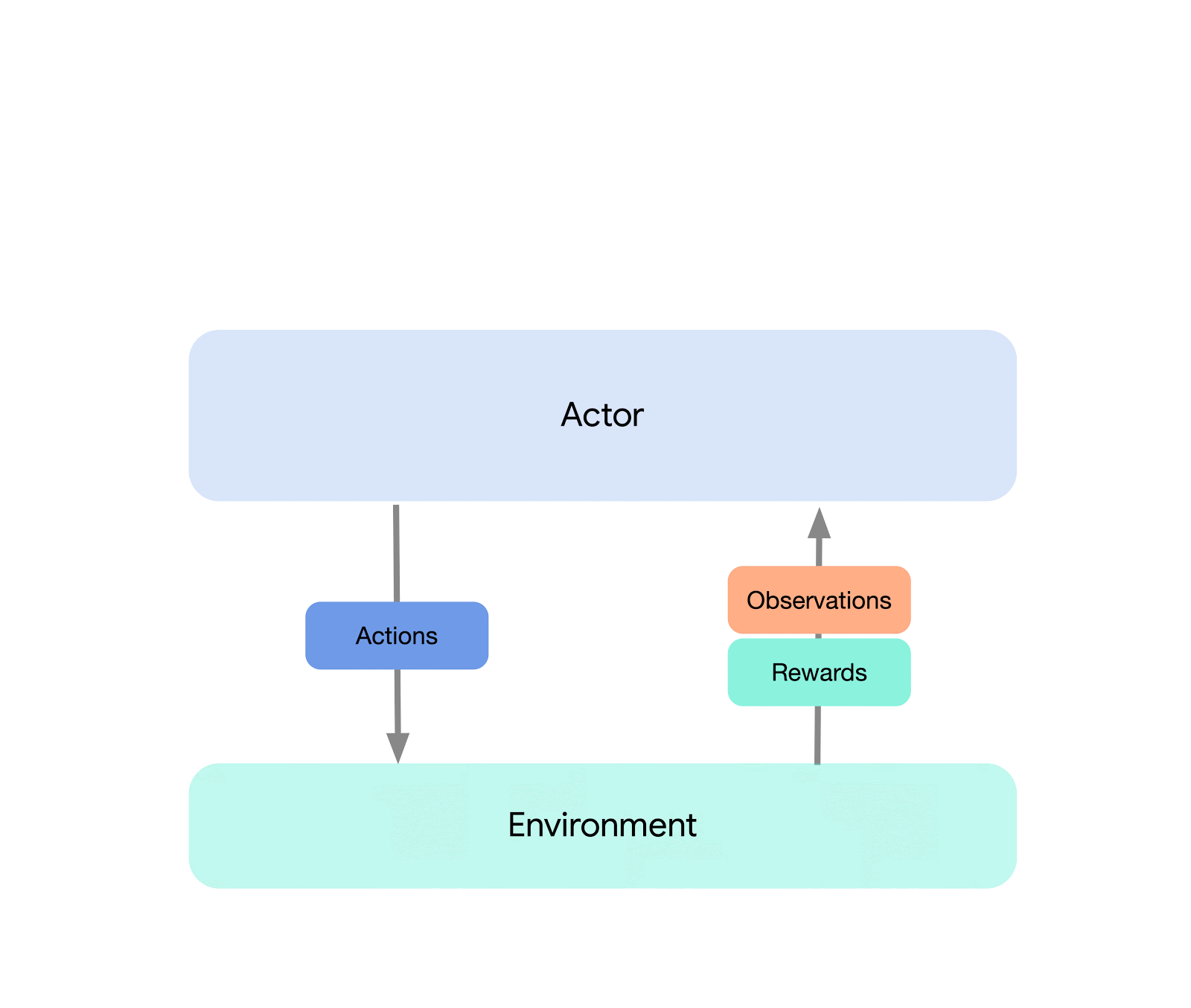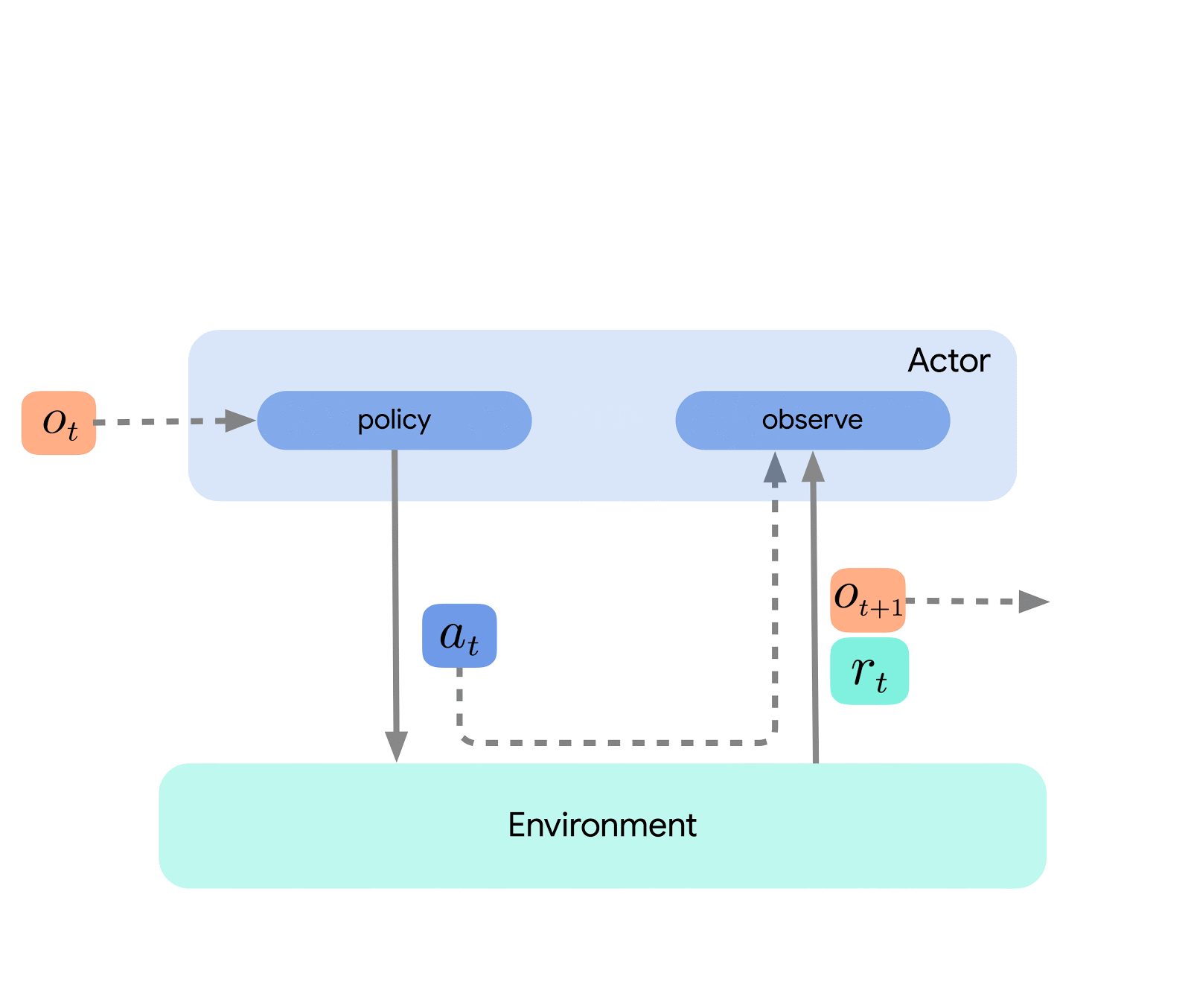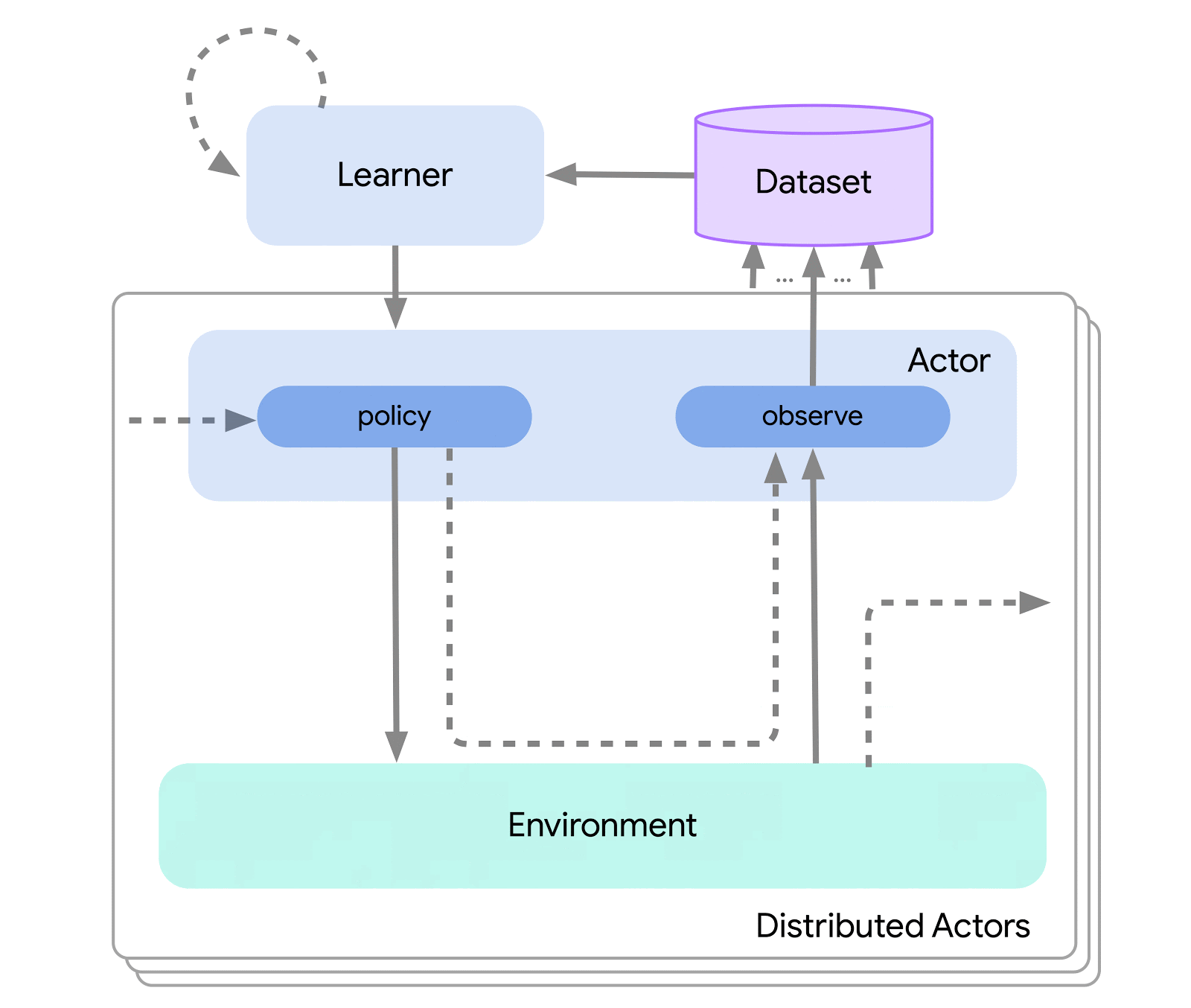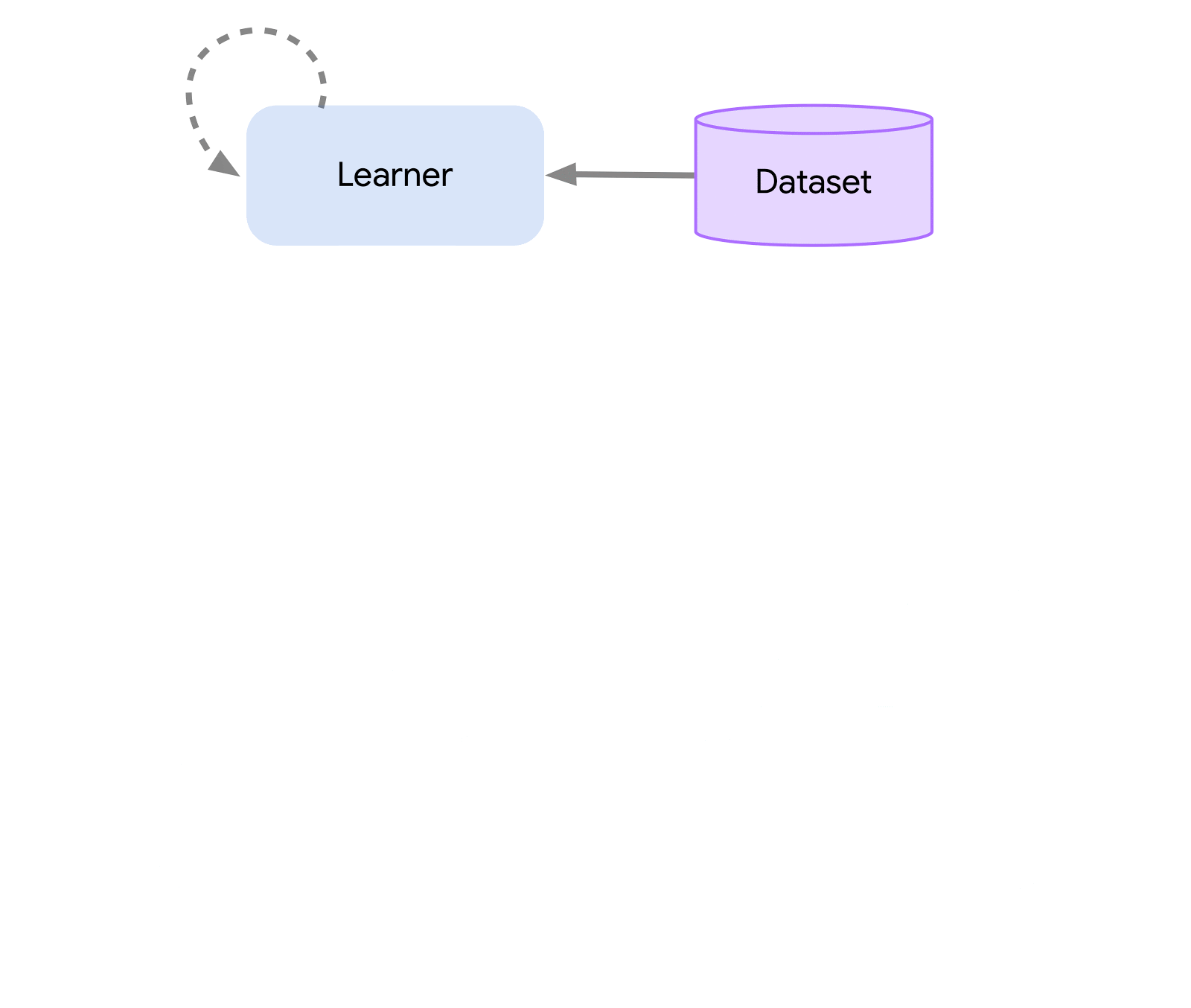
这种设计使我们可以在小规模场景中轻松创建、测试和调试新的代理程序,然后再将它们扩展到更大规模-同时使用相同的执行和学习代码。Acme还提供了许多有用的工具,从检查点、快照到低级计算辅助工具。这些工具通常是任何强化学习算法中不为人知的英雄,在Acme中,我们努力使它们尽可能简单和易于理解。
为了实现这种设计,Acme还利用了Reverb:一种新颖、高效的数据存储系统,专为机器学习(和强化学习)数据而构建。Reverb主要用作分布式强化学习算法中的经验回放系统,但它还支持其他数据结构表示,如FIFO和优先队列。这使我们可以在在线和离线算法中无缝使用它。Acme和Reverb从一开始就被设计成相互配合,但Reverb也可以单独使用,所以去看看吧!
除了基础设施,我们还发布了使用Acme构建的一些代理程序的单进程实例。这些代理程序涵盖了连续控制(D4PG、MPO等)、离散Q学习(DQN和R2D2)等各种类型。通过对执行/学习边界进行拆分,只需进行最少的更改,我们就可以以分布式方式运行这些相同的代理程序。我们的首次发布主要关注单进程代理程序,因为这些代理程序是学生和研究从业者主要使用的。
我们还在一些环境中仔细对这些代理程序进行了基准测试,包括控制套件、Atari和bsuite。
使用 Acme 框架训练的代理程序的视频播放列表
虽然我们的论文中还有更多的结果可供参考,但我们展示了一些图表,比较了单个代理程序(D4PG)在连续控制任务中在行动步骤和墙时钟时间方面的性能。由于我们限制了数据插入回放的速率(更详细的讨论请参阅论文),当比较代理程序接收到的奖励与其与环境的交互次数(行动步骤)时,我们可以看到大致相同的性能。然而,随着代理程序的进一步并行化,我们在学习速度方面获得了收益。在观察受限于小特征空间的相对较小的领域中,即使是在这种并行化较低的情况下(4个执行者),代理程序学习最优策略的时间也可以减少一半:

但对于观察结果是相对昂贵的图像的更复杂领域,我们看到了更大的收益:

并且对于一些领域,例如Atari游戏,由于数据收集成本更高、学习过程通常更长,收益可能会更大。然而,重要的是要注意,这些结果在分布式和非分布式环境中使用相同的行动和学习代码。因此,在较小的规模上实验这些代理和结果是完全可行的 – 实际上,这是我们开发新型代理时一直在做的事情!
有关此设计的更详细描述以及我们基线代理的进一步结果,请参阅我们的论文。或者更好的是,查看我们的GitHub存储库,了解如何使用Acme简化您自己的代理!






