掌握大型语言模型(LLMs)的7个步骤
掌握大型语言模型(LLMs)的7个步骤,让你轻松无压享受智能写作
GPT-4、Llama、Falcon等等 – 大型语言模型 – LLM,是今年备受瞩目的话题。如果您正在阅读本文,那么您有很大的机会已经通过聊天界面或API使用过其中一个或多个大型语言模型。
如果您曾想过LLMs到底是什么,它们是如何工作的,以及您可以用它们构建什么,那么本指南就是为您准备的。无论您是对大型语言模型感兴趣的数据专业人士,还是为了好奇,本指南都是帮助您了解LLM领域的全面指南。
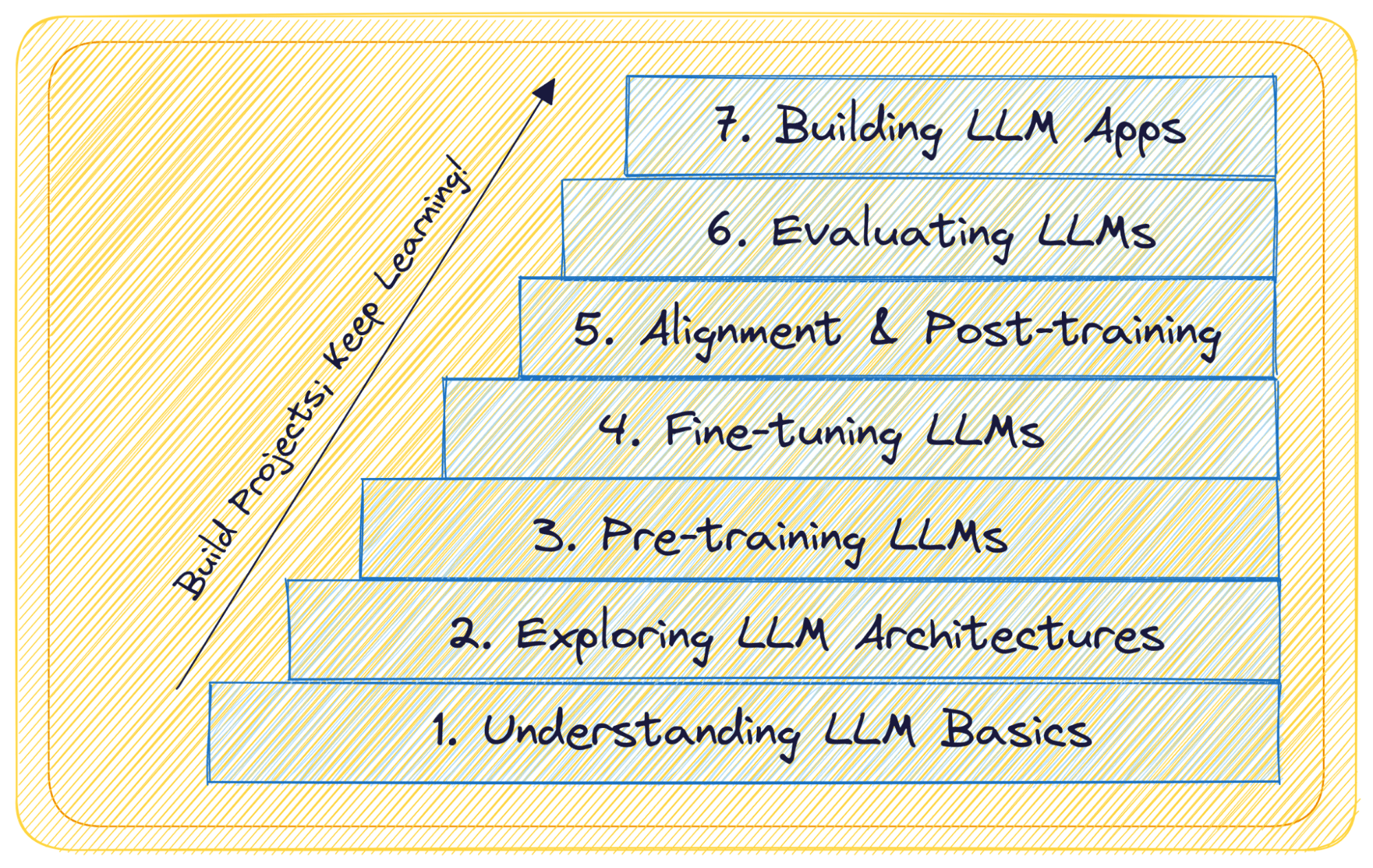
从LLMs的定义到使用LLMs构建和部署应用程序,我们将通过7个简单的步骤来学习有关大型语言模型的所有知识,包括:
- 您应该知道什么
- 各种概念的概述
- 学习资源
让我们开始吧!
第一步:了解LLM基础知识
如果您对大型语言模型还不熟悉,从一个高层次的角度来了解LLMs及其强大之处会很有帮助。试着回答以下问题:
- LLMs究竟是什么?
- 为什么它们如此受欢迎?
- LLMs与其他深度学习模型有何不同?
- LLMs的常见用途是什么?(您可能已经熟悉了这个问题,但列出来作为练习也是不错的)
您能都回答出来吗?让我们一起来解答吧!
LLMs是什么?
Large Language Models(大型语言模型)或LLMs是深度学习模型的一个子集,它们在大量文本数据上进行训练。它们规模庞大,拥有数百亿个参数,并且在各种自然语言任务上表现出色。
它们为何受欢迎?
LLMs具备理解和生成连贯、上下文相关且语法正确的文本的能力。它们的受欢迎程度和广泛应用包括:
- 在各种语言任务上表现出色
- 提供预训练的LLMs的可访问性和可用性,推动了基于人工智能的自然语言理解和生成的民主化
LLMs与其他深度学习模型有何不同?
LLMs凭借其规模和架构的独特之处,包括自注意机制。关键的区别包括:
- Transformer架构,这个架构革命了自然语言处理并支撑了LLMs(我们指南中即将介绍)
- 能够捕捉文本中的长距离依赖关系,实现更好的上下文理解
- 能够处理各种语言任务,包括文本生成、翻译、摘要和问答
LLMs的常见用途是什么?
LLMs已经在各种语言任务中找到了应用,包括:
- 自然语言理解:LLMs在情感分析、命名实体识别、问题回答等任务上表现卓越。
- 文本生成:它们可以为聊天机器人和其他内容生成任务生成类似人类的文本(如果您曾经使用过ChatGPT或类似的服务,这应该不会让您感到惊讶)。
- 机器翻译:LLMs极大地提高了机器翻译的质量。
- 内容摘要:LLMs可以生成简洁的长文档摘要。您试过摘要YouTube视频的字幕吗?
现在,您已经对LLMs及其能力有了初步的了解,如果您有兴趣进一步探索,以下是一些资源供您参考:
步骤2:探索LLM架构
现在您已经了解了LLMs是什么,让我们继续学习这些强大LLMs背后的变压器架构。因此,在您的LLM之旅中,变压器需要您全部注意力(无意冒犯)。
最初的变压器架构是在论文《注意力机制就是你所需要的全部》中介绍的,这个架构彻底改变了自然语言处理:
- 主要特点:自注意力层、多头注意力、前馈神经网络、编码器-解码器架构。
- 应用案例:变压器是BERT和GPT等著名LLM的基础。
最初的变压器架构使用的是编码器-解码器架构,但也存在仅编码器和仅解码器的变体。以下是这些变体的综合概述,以及它们的特点、著名LLM和应用案例:
|
主要特点 | 著名LLM | 应用案例 |
|
捕捉双向上下文;适用于自然语言理解 |
基于这个架构的RoBERTa,XLNet |
|
|
单向语言模型;自回归生成 |
|
|
| 编码器-解码器 | 输入文本到目标文本;任何文本到文本的任务 |
|
|
以下是学习变压器的绝佳资源:
步骤3:预训练LLMs
现在您已经熟悉大型语言模型(LLMs)和变压器架构的基础知识,可以继续学习预训练LLMs。预训练通过让LLMs接触大规模文本数据,使其理解语言的各个方面和细微差异,为LLMs奠定基础。
这里是你应该了解的概念概述:
- 预训练LLMs的目标:将LLMs暴露给大量文本语料库,学习语言模式、语法和上下文。了解特定的预训练任务,如掩码语言建模和下一个句子预测。
- LLM预训练的文本语料库:LLMs是在大规模和多样化的文本语料库上进行训练,包括网络文章、图书和其他来源。这些是大型数据集,包含数十亿到数万亿的文本标记。常见的数据集包括C4、BookCorpus、Pile、OpenWebText等。
- 训练过程:了解预训练的技术方面,包括优化算法、批量大小和训练周期。了解如何应对数据中的偏见等挑战。
如果你有兴趣进一步学习,可以参考CS324课程中关于LLM训练的模块。
这些预训练的LLMs作为特定任务微调的起点。是的,微调LLMs是我们的下一步!
第四步:微调LLMs
在大规模文本语料库上进行预训练后,下一步是针对特定自然语言处理任务对LLMs进行微调。微调使您能够将预训练的模型适应特定任务,如情感分析、问答或翻译,具有更高的准确性和效率。
为什么要微调LLMs
微调有几个必要性:
- 预训练的LLMs已经获得了一般的语言理解能力,但需要微调才能在特定任务上表现良好。微调有助于模型学习目标任务的细微差别。
- 与从头开始训练模型相比,微调显著降低了所需的数据量和计算量。因为它利用了预训练模型的理解能力,微调数据集可以比预训练数据集小得多。
如何微调LLMs
现在让我们来看看如何微调LLMs:
-
- 选择预训练LLM:选择与您的任务匹配的预训练LLM。例如,如果您正在处理问答任务,选择具有促进自然语言理解的架构的预训练模型。
- 数据准备:为您希望LLM执行的特定任务准备数据集。确保它包含有标注的示例并格式正确。
- 微调:在选择了基础LLM并准备好数据集后,就可以开始实际微调模型。
- 但是如何进行微调呢?
- 有没有参数高效的技术呢?记住,LLMs有数百亿的参数。而且权重矩阵非常庞大!
- 如果你无法获取权重呢?
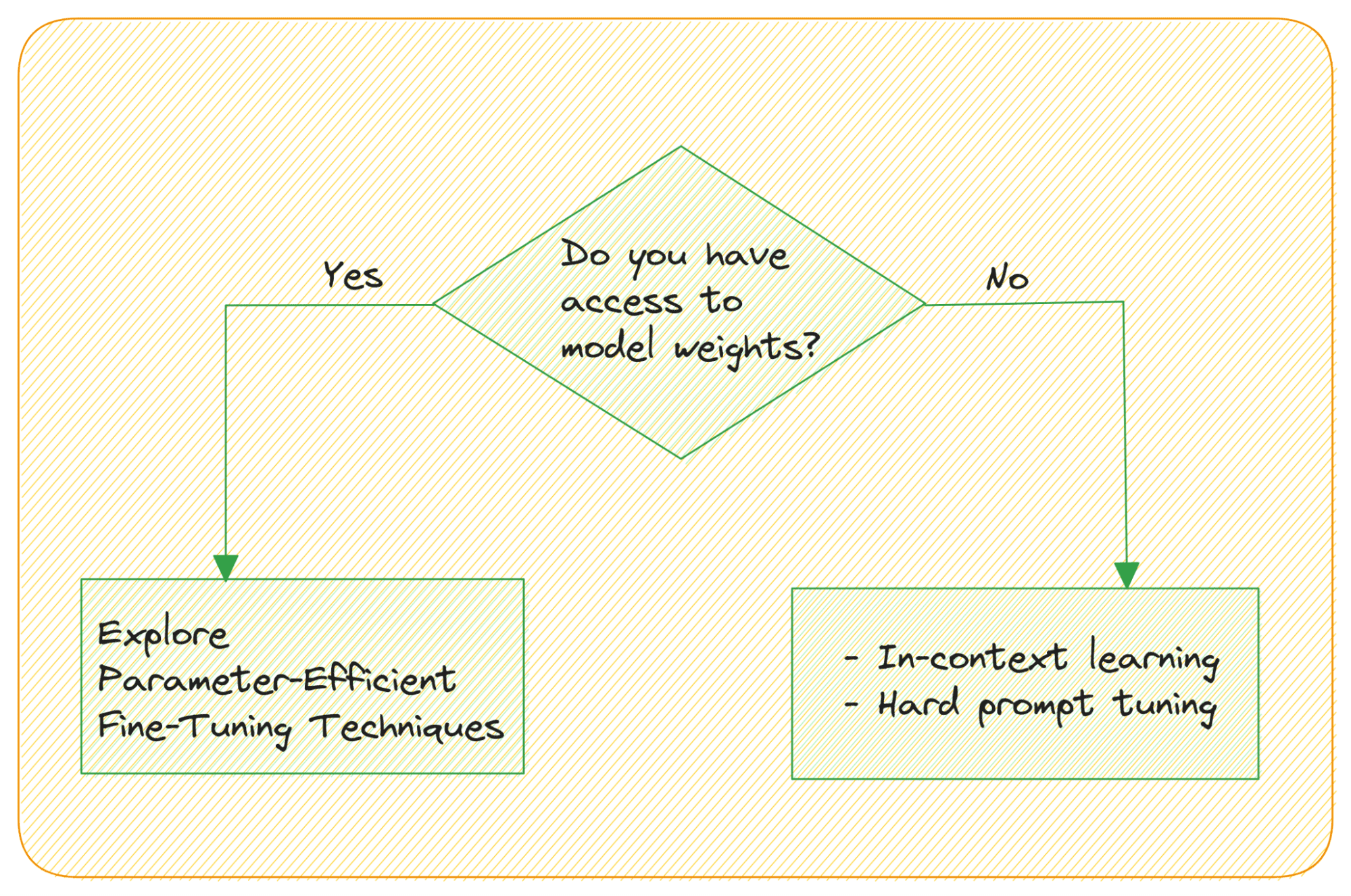
当你无法访问模型权重且通过API访问模型时,如何微调LLM呢?大型语言模型具有上下文学习的能力,不需要明确的微调步骤。您可以利用它们的类比学习能力,通过提供输入和任务的示例输出来让它们学习。
微调提示-修改提示以获得更有帮助的输出-可以是:硬提示微调或(软)提示微调。
硬提示微调直接修改提示中的输入标记,因此不会更新模型的权重。
软提示微调将输入嵌入与可学习张量连接起来。一个相关的思想是前缀微调,其中可学习张量与每个Transformer块一起使用,而不仅仅是输入嵌入。
如上所述,大规模语言模型具有数十亿个参数。因此,对所有层的权重进行微调是一项资源密集型任务。最近,诸如LoRA和QLoRA之类的“参数高效微调技术(PEFT)”变得很受欢迎。使用QLoRA,您可以在单个消费级GPU上对4位量化的LLM进行微调,而不会降低性能。
这些技术引入了一小组可学习的参数-“适配器”-而不是整个权重矩阵进行微调。以下是了解更多关于微调LLM的有用资源:
步骤5:LLM的对齐和后训练
大型语言模型有可能生成有害、偏见或与用户实际期望不符的内容。对齐是指将LLM的行为与人类偏好和伦理原则对齐的过程。它旨在减轻与模型行为相关的风险,包括偏见、有争议的回应和有害内容生成。
您可以探索以下技术:
- 来自人类反馈的强化学习(RLHF)
- 对比后训练
RLHF使用LLM输出的人类偏好注释,并在其中适应奖励模型。对比后训练旨在利用对比技术自动构建偏好对。 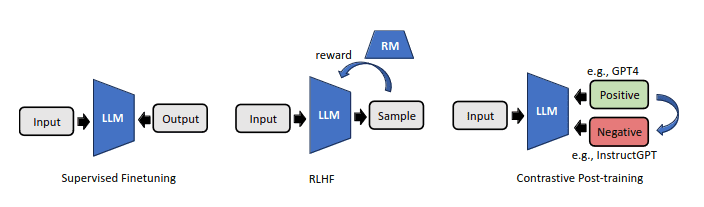
要了解更多信息,请查看以下资源:
步骤6:LLM的评估和持续学习
一旦您为特定任务对LLM进行微调,评估其性能并考虑持续学习和适应策略就变得至关重要。此步骤确保您的LLM保持有效和最新。
LLM的评估
评估性能以评估其有效性并确定改进方面。以下是LLM评估的关键方面:
- 任务特定度量标准:选择适合您任务的度量标准。例如,在文本分类中,您可以使用常规评估指标如准确度、精确度、召回率或F1分数。对于语言生成任务,通常使用困惑度和BLEU分数等度量标准。
- 人类评估:请专家或基于众包的标注人员评估生成内容的质量或模型在真实场景中的响应。
- 偏见和公平性:评估LLM的偏见和公平性问题,特别是在实际应用中部署时。分析模型在不同人群中的表现,并解决任何差异。
- 鲁棒性和对抗性测试:通过对LLM进行对抗性攻击或挑战性输入来测试其鲁棒性。这有助于发现漏洞并增强模型安全性。
持续学习和适应
为了使LLM与新数据和任务保持更新,请考虑以下策略:
- 数据增强:持续增加数据存储以避免因缺乏最新信息而造成性能下降。
- 重新训练:定期使用新数据重新训练LLM,并对其进行微调以适应不断变化的任务。使用最新数据进行微调可以使模型保持更新。
- 主动学习:采用主动学习技术来识别模型不确定或可能出现错误的情况。收集这些实例的注释以完善模型。
LLM(Large Language Models)存在的另一个常见问题是幻觉。务必探索诸如提取增强之类的技术来减轻幻觉。
以下是一些有用的资源:
第7步:构建和部署LLM应用
在开发和优化特定任务的LLM之后,开始构建和部署利用LLM功能的应用程序。本质上,使用LLM构建有用的实际解决方案。 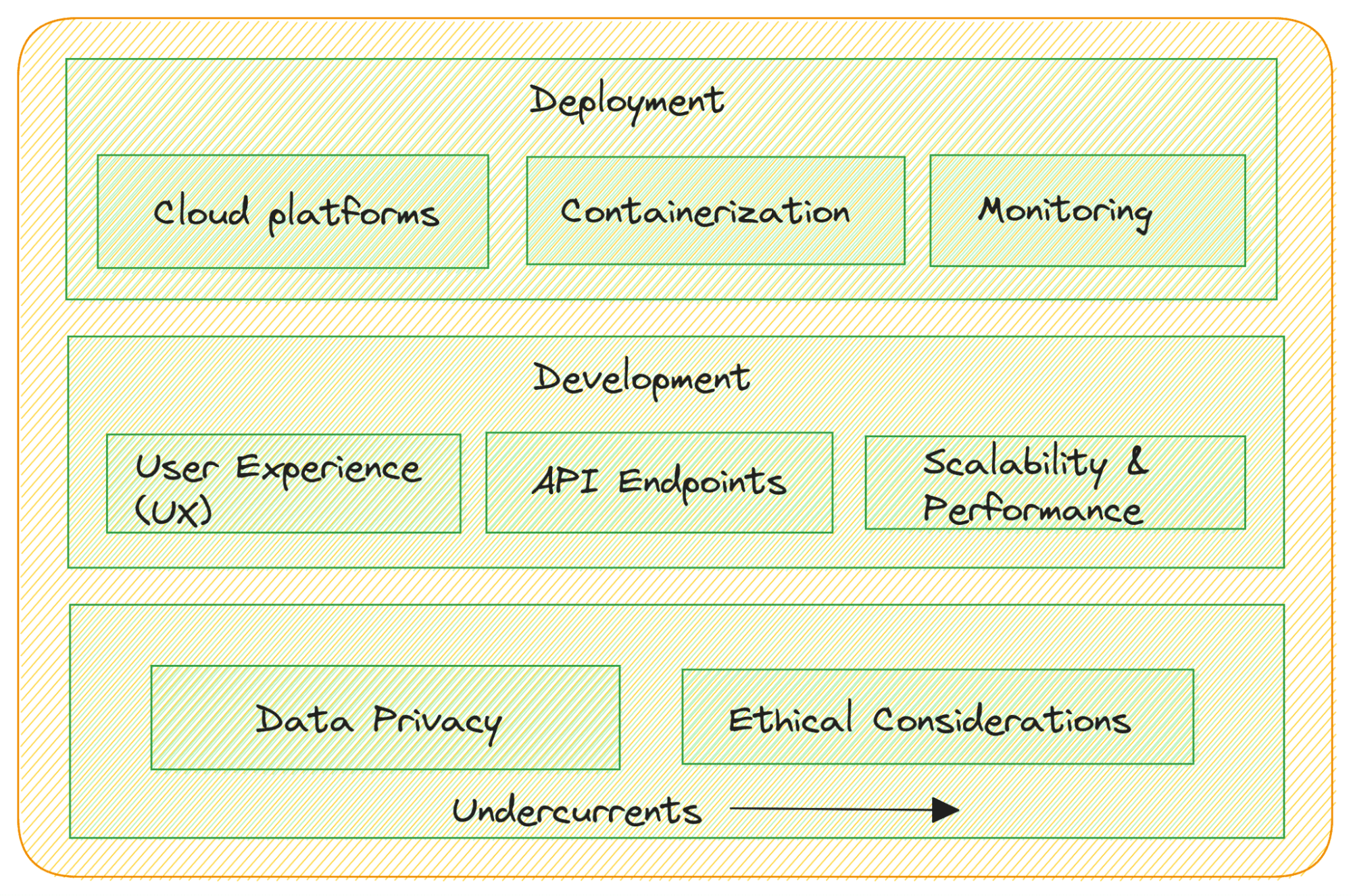
构建LLM应用程序
以下是一些需要考虑的因素:
- 专门针对任务开发应用程序:开发适合特定用例的应用程序。这可能涉及创建基于Web的界面、移动应用程序、聊天机器人或与现有软件系统集成。
- 用户体验(UX)设计:专注于以用户为中心的设计,确保LLM应用程序直观且用户友好。
- API集成:如果您的LLM用作语言模型后端,请创建RESTful API或GraphQL端点,以便其他软件组件能够与模型无缝交互。
- 可扩展性和性能:设计应用程序以处理不同级别的流量和需求。优化性能和可扩展性,以确保用户体验流畅。
部署LLM应用程序
您已经开发了LLM应用程序,并准备将其部署到生产环境中。以下是您应该考虑的事项:
- 云部署:考虑将LLM应用程序部署在AWS、Google Cloud或Azure等云平台上,以实现可扩展性和便于管理。
- 容器化:使用Docker和Kubernetes等容器化技术,打包您的应用程序,并确保在不同环境中一致部署。
- 监控:实施监控,跟踪已部署的LLM应用程序的性能,并实时检测和解决问题。
合规性和法规
数据隐私和伦理考量是核心内容:
- 数据隐私:在处理用户数据和个人身份信息(PII)时,确保符合数据隐私法规。
- 伦理考量:在部署LLM应用程序时遵守伦理准则,以减轻潜在的偏见、错误信息或有害内容生成。
您还可以使用LlamaIndex和LangChain等框架帮助您构建端到端LLM应用程序。以下是一些有用的资源:
总结
我们从定义大型语言模型的含义以及它们为什么受欢迎开始讨论,然后逐渐深入技术方面。我们以构建和部署LLM应用程序作为结尾,这需要仔细规划、以用户为中心的设计和稳健的基础设施,并优先考虑数据隐私和伦理。
正如您可能已经意识到的那样,保持与该领域的最新进展并不断开展项目非常重要。如果您具有一些自然语言处理方面的经验,本指南将进一步构建您的基础。即使没有经验,也不用担心。我们为您提供了我们的《7步掌握自然语言处理》指南。祝您学习愉快!
[Bala Priya C](https://twitter.com/balawc27) 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉领域工作。她感兴趣并擅长于DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过编写教程、操作指南、观点文章等来学习和与开发者社区分享她的知识。






