评估提升模型
评估提升模型
因果数据科学
如何比较和选择最佳的提升模型
在工业界中,最常见的因果推断应用之一是提升建模,也就是条件平均处理效应的估计。
在估计治疗(药物、广告、产品等)对感兴趣的结果(疾病、公司收入、客户满意度等)的因果效应时,我们通常不仅仅关心治疗在平均水平上是否有效,还希望知道对于哪些对象(患者、用户、客户等)效果更好或更差。
估计异质性增量效应,或者提升效果,是改进目标策略的重要中间步骤。例如,我们可能希望警告某些人他们更有可能从药物中获得副作用,或者仅向特定一组客户展示广告。
虽然存在许多模型提升的方法,但在特定应用中往往不清楚应该使用哪种方法。关键在于,由于因果推断的基本问题,我们感兴趣的目标——提升效果,从来没有被观察到,因此我们无法像使用机器学习预测算法那样验证我们的估计器。我们无法设置一个验证集并选择表现最好的模型,因为我们没有任何基准,即使在验证集中也没有,即使我们进行了随机实验。
那么我们该怎么办呢?在本文中,我试图介绍最流行的用于评估提升模型的方法。如果您对提升模型不熟悉,我建议先阅读我的入门文章。
理解元学习器
编辑描述
towardsdatascience.com
提升和促销邮件
假设我们在一家对改进电子邮件营销活动感兴趣的产品公司的市场部门工作。在过去,我们主要向新客户发送电子邮件。然而,现在我们想采用数据驱动的方法,将邮件发送给对收入产生最大积极影响的客户。这种影响也称为提升或增量。
让我们来看看我们手头的数据。我从src.dgp中导入数据生成过程dgp_promotional_email()。我还从src.utils中导入一些绘图函数和库。
from src.utils import *from src.dgp import dgp_promotional_emaildgp = dgp_promotional_email(n=500)df = dgp.generate_data()df.head()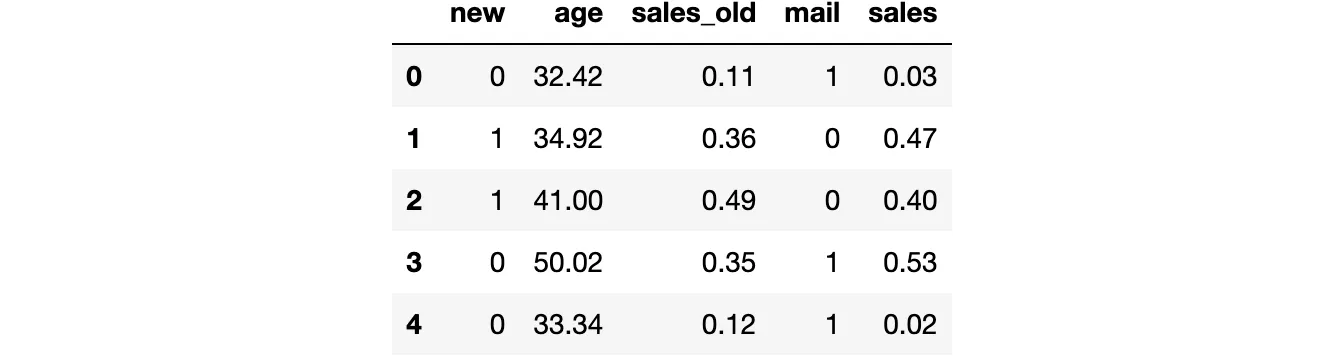
我们有500名客户的信息,我们观察到他们是否是new客户,他们的age,邮件活动之前他们产生的销售额sales_old,是否发送了mail,以及邮件活动之后的sales。
我们感兴趣的结果是sales,我们用字母Y表示。我们希望改进的治疗或策略是mail活动,我们用字母W表示。我们将所有剩余的变量称为混杂因素或控制变量,用X表示。
Y = 'sales'W = 'mail'X = ['age', 'sales_old', 'new']有向无环图(Directed Acyclic Graph, DAG)表示变量之间的因果关系如下所示。感兴趣的因果关系以绿色表示。
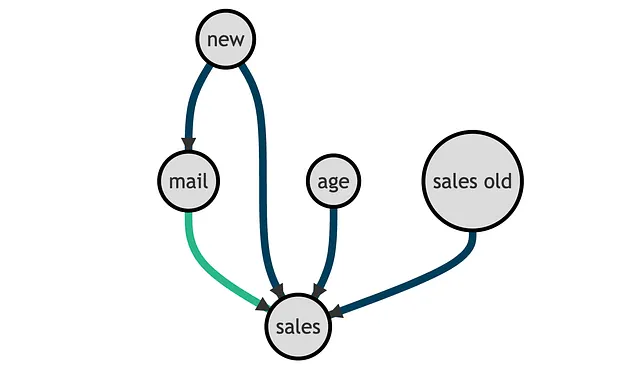
从有向无环图(DAG)中,我们可以看到new客户指示器是一个混淆变量,需要进行控制以便确定mail对sales的影响。而年龄(age)和旧销售额(sales_old)则不是估计所必需的,但可以帮助确定。有关有向无环图和控制变量的更多信息,请参阅我的介绍性文章。
有向无环图和控制变量
编辑描述
towardsdatascience.com
提升建模的目标是恢复个体处理效应(Individual Treatment Effects, ITE) τᵢ,即发送促销mail对sales的增量效应。我们可以将个体处理效应表示为两个假设数量之间的差异:如果客户收到邮件,他们的潜在结果Yᵢ⁽¹⁾,减去如果客户没有收到邮件,他们的潜在结果Yᵢ⁽⁰⁾。
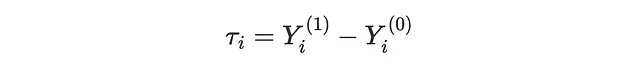
请注意,对于每个客户,我们只观察到两个实现的结果之一,具体取决于他们是否实际收到了mail。因此,个体处理效应是内在不可观察的。可以估计的是条件平均处理效应(Conditional Average Treatment Effect, CATE),即在协变量X条件下的预期个体处理效应τᵢ。例如,对于年龄较大的客户(age > 50),mail对sales的平均效应。
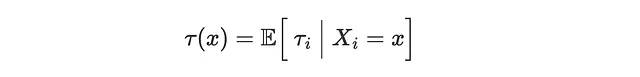
为了能够恢复CATE,我们需要做三个假设。
- 非混淆性(Unconfoundedness):Y⁽⁰⁾, Y⁽¹⁾ ⊥ W | X
- 重叠性(Overlap):0 < e(X) < 1
- 一致性(Consistency):Y = W ⋅ Y⁽¹⁾ + (1−W) ⋅ Y⁽⁰⁾
这里,e(X)是倾向得分(propensity score),即在给定协变量X的条件下被处理的预期概率。
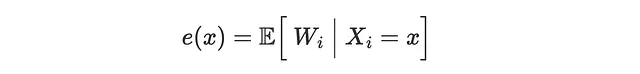
在接下来的内容中,我们将使用机器学习方法来估计CATE τ(x),倾向得分e(x),以及结果的条件期望函数(CEF)μ(x)
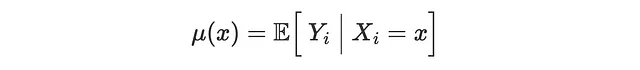
我们使用随机森林回归算法来建模CATE和结果CEF,而使用逻辑回归来建模倾向得分。
from sklearn.ensemble import RandomForestRegressorfrom sklearn.linear_model import LogisticRegressionCVmodel_tau = RandomForestRegressor(max_depth=2)model_y = RandomForestRegressor(max_depth=2)model_e = LogisticRegressionCV()在本文中,我们没有对底层的机器学习模型进行微调,但强烈建议进行微调以提高推动模型的准确性(例如,使用FLAML等自动机器学习库)。
推动模型
有很多方法可以建模推动效应,或者换句话说,估计条件平均处理效应(CATE)。由于本文的目标是比较评估推动模型的方法,我们不会详细解释这些方法。如果您想了解简要介绍,可以查看我关于元学习算法的入门文章。
我们将考虑以下学习器:
- S-learner或单学习器,由Kunzel、Sekhon、Bickel、Yu(2017)引入
- T-learner或双学习器,由Kunzel、Sekhon、Bickel、Yu(2017)引入
- X-learner或交叉学习器,由Kunzel、Sekhon、Bickel、Yu(2017)引入
- R-learner或Robinson学习器,由Nie、Wager(2017)引入
- DR-learner或双重稳健学习器,由Kennedy(2022)引入
我们从Microsoft的econml库中导入所有模型。
from src.learners_utils import *from econml.metalearners import SLearner, TLearner, XLearnerfrom econml.dml import NonParamDMLfrom econml.dr import DRLearnerS_learner = SLearner(overall_model=model_y)T_learner = TLearner(models=clone(model_y))X_learner = XLearner(models=model_y, propensity_model=model_e, cate_models=model_tau)R_learner = NonParamDML(model_y=model_y, model_t=model_e, model_final=model_tau, discrete_treatment=True)DR_learner = DRLearner(model_regression=model_y, model_propensity=model_e, model_final=model_tau)我们在数据上fit()模型,指定结果变量Y、处理变量W和协变量X。
names = ['SL', 'TL', 'XL', 'RL', 'DRL']learners = [S_learner, T_learner, X_learner, R_learner, DR_learner]for learner in learners: learner.fit(df[Y], df[W], X=df[X])现在我们准备好评估模型了!我们应该选择哪个模型?
Oracle损失函数
评估推动模型的主要问题是,即使有验证集,即使进行了随机实验或AB测试,我们也无法观察到我们感兴趣的度量:个体处理效应。实际上,我们只观察到未接受处理的客户的实现结果Yᵢ⁽⁰⁾和接受处理的客户的实现结果Yᵢ⁽¹⁾。因此,在任何客户的验证数据中,我们无法计算个体处理效应τᵢ = Yᵢ⁽¹⁾ − Yᵢ⁽⁰⁾。
我们仍然可以做一些事情来评估我们的估计器吗?
答案是肯定的,但在给出更多细节之前,让我们先了解一下如果我们能观察到个体处理效应τᵢ时我们会做什么。
Oracle均方误差(MSE)损失
如果我们能观察到个体处理效应(但我们不能,因此有“oracle”属性),我们可以尝试衡量我们的估计值τ̂(Xᵢ)与真实值τᵢ之间的偏差有多大。这正是我们在机器学习中通常做的事情,当我们想评估一个预测方法时:我们留出一个验证数据集,然后在该数据上比较预测值和真实值。有很多损失函数可以评估预测准确性,所以让我们集中在最流行的一个上:均方误差(MSE)损失。
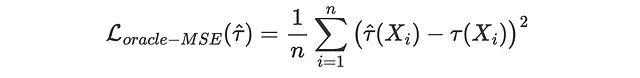
def loss_oracle_mse(data, learner): tau = learner.effect(data[X]) return np.mean((tau - data['effect_on_sales'])**2)函数compare_methods在一个单独的验证数据集上计算并打印评估指标。
def compare_methods(learners, names, loss, title=None, subtitle='较低的值表示较好'): data = dgp.generate_data(seed_data=1, seed_assignment=1, keep_po=True) results = pd.DataFrame({ 'learner': names, 'loss': [loss(data.copy(), learner) for learner in learners] }) fig, ax = plt.subplots(1, 1, figsize=(6, 4)) sns.barplot(data=results, x="learner", y='loss').set(ylabel='') plt.suptitle(title, y=1.02) plt.title(subtitle, fontsize=12, fontweight=None, y=0.94) return resultsresults = compare_methods(learners, names, loss_oracle_mse, title='Oracle MSE损失')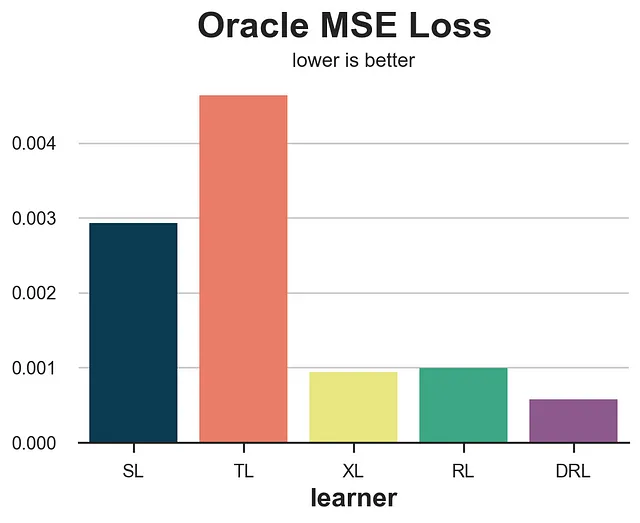
在这种情况下,我们可以看到T-learner明显表现最差,S-learner紧随其后。另一方面,X-learner、R-learner和DR-learner表现明显更好,DR-learner获胜。
然而,这可能不是评估我们提升模型的最佳损失函数。事实上,提升建模只是我们最终目标的一个中间步骤:改善收入。
Oracle政策收益
由于我们的最终目标是提高收入,我们可以根据某个策略函数评估估计器增加的收入量。例如,假设我们发送一封电子邮件的成本为0.01美元。那么,我们的策略是对每个具有预测的条件平均处理效果大于0.01美元的客户进行处理。
cost = 0.01我们的实际收入会增加多少?让我们定义策略函数d(τ̂),如果τ≥0.1,则d=1,否则d=0。那么我们的增益(较高的值表示较好)函数是:
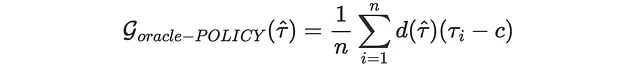
同样,这是一个“oracle”损失函数,在现实中无法计算,因为我们无法观察到个体处理效果。
def gain_oracle_policy(data, learner): tau_hat = learner.effect(data[X]) return np.sum((data['effect_on_sales'] - cost) * (tau_hat > cost))results = compare_methods(learners, names, gain_oracle_policy, title='Oracle政策收益', subtitle='较高的值表示较好')
在这种情况下,S-learner明显是最差的表现者,对收入没有影响。T-learner带来了适度的增益,而X-learner、R-learner和DR-learner都带来了总体增益,X-learner略微领先。
实际损失函数
在前一节中,我们看到了两个损失函数的例子,如果我们能观测到个体处理效果τᵢ,我们希望计算这些损失函数。然而,在实践中,即使进行了随机实验,即使有验证集,我们也无法观测到ITE(我们感兴趣的对象)。现在,我们将介绍一些在这种实际约束条件下尝试评估提升模型的指标。
结果损失
第一种也是最简单的方法是切换到不同的损失变量。虽然我们无法观察到个体处理效应 τᵢ,但我们仍然可以观察到我们的输出变量 Yᵢ。虽然这不是我们真正感兴趣的对象,但我们可能期望一个在预测 y 方面表现良好的 uplift 模型也能产生良好的 τ 估计。
一种这样的损失函数可能是结果的 MSE 损失,这是用于预测方法的通常 MSE 损失函数。
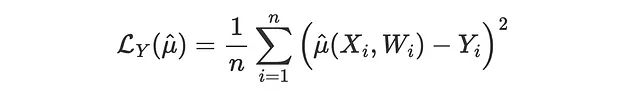
问题在于,并不是所有的模型都直接产生 μ(x) 的估计。因此,我们跳过了这个比较,转而使用可以评估任何 uplift 模型的方法。
预测到预测损失
另一种非常简单的方法是将训练集上训练的模型的预测结果与验证集上训练的另一个模型的预测结果进行比较。虽然直观,但这种方法可能会极其误导。
def loss_pred(data, learner): tau = learner.effect(data[X]) learner2 = copy.deepcopy(learner).fit(data[Y], data[W], X=data[X]) tau2 = learner2.effect(data[X]) return np.mean((tau - tau2)**2)results = compare_methods(learners, names, loss_pred, '预测到预测损失')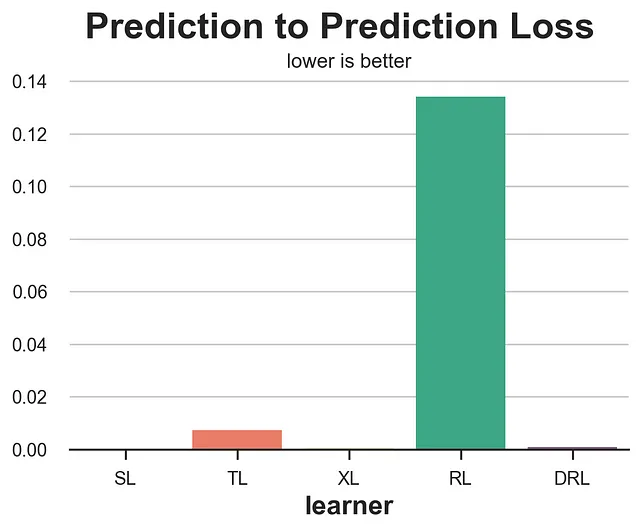
毫不奇怪,这个指标的表现非常糟糕,你应该绝不使用它,因为它奖励那些一致的模型,而不考虑它们的质量。一个总是对每个观测值预测一个随机的常数 CATE 的模型将获得完美的分数。
分布损失
另一种方法是问:我们能有多好地匹配潜在结果的分布?我们可以对已接受或未接受处理的潜在结果进行这个练习。让我们以最后一种情况为例。假设我们采用未接收邮件的客户的观察到的销售额和接收邮件的客户的观察到的销售额减去估计的 CATE τ̂(x)。根据非混淆性假设,这两个未接受处理的潜在结果的分布在给定协变量 X 的条件下应该是相似的。
因此,如果我们正确地估计了处理效应,我们期望这两个分布之间的距离是接近的。
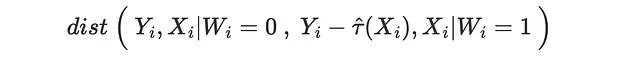
我们也可以对已接受处理的潜在结果做同样的练习。
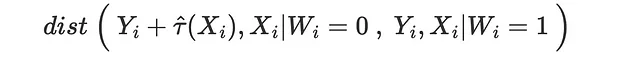
我们使用能量距离作为距离度量。
from dcor import energy_distancedef loss_dist(data, learner): tau = learner.effect(data[X]) data.loc[data.mail==1, 'sales'] -= tau[data.mail==1] return energy_distance(data.loc[data.mail==0, [Y] + X], data.loc[data.mail==1, [Y] + X], exponent=2)results = compare_methods(learners, names, loss_dist, '分布损失')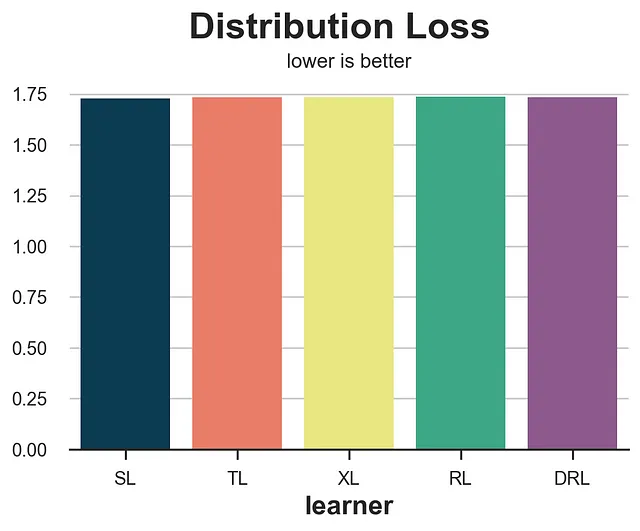
这个度量非常嘈杂,奖励了S-学习者和T-学习者,而实际上它们是表现最差的两个模型。
中位数上下差异
中位数上下损失试图回答这个问题:我们的提升模型是否检测到任何异质性?特别是,如果我们把验证集分成预测提升 τ̂(x) 高于中位数和低于中位数的样本,用平均效应的差异估计量来估计实际差异有多大?我们会期望更好的估计器能够更好地将样本分成高效果和低效果。
from statsmodels.formula.api import ols def loss_ab(data, learner): tau = learner.effect(data[X]) + np.random.normal(0, 1e-8, len(data)) data['above_median'] = tau >= np.median(tau) param = ols('sales ~ mail * above_median', data=data).fit().params[-1] return paramresults = compare_methods(learners, names, loss_ab, title='中位数上下差异', subtitle='值越高越好')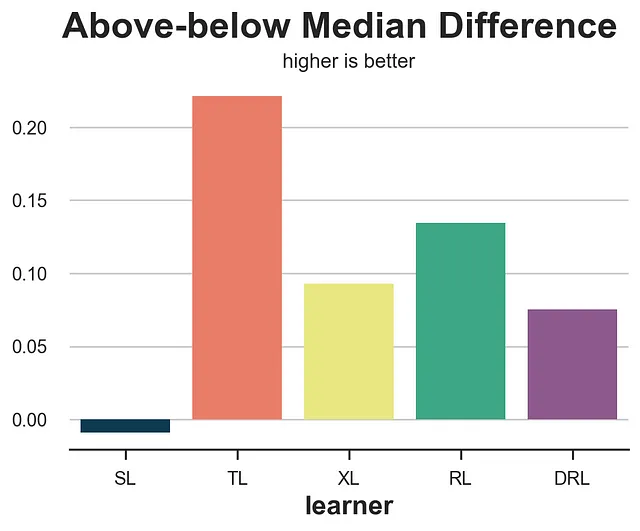
不幸的是,中位数上下差异奖励了T-学习者,它是最差表现的模型之一。
需要注意的是,在两个组(高于和低于中位数 τ̂(x))中的均值差异估计值不能保证是无偏的,即使数据来自随机实验。实际上,我们已经根据高度内生的变量 τ̂(x) 将两个组分开。因此,这种方法应该谨慎使用。
提升曲线
上述中位数测试的一个扩展是提升曲线。这个想法很简单:我们为什么不根据更多的分位数将样本分成更多的组,而不是根据中位数(0.5分位数)来分组呢?
对于每个组,我们计算均值差异估计值,并将其累积和绘制成相应分位数的图。结果被称为提升曲线。解释很简单:曲线越高,我们越能够将高效果和低效果的观察结果分开。然而,同样的免责声明也适用:均值差异估计值不是无偏的。因此,它们应该谨慎使用。
def generate_uplift_curve(df): Q = 20 df_q = pd.DataFrame() data = dgp.generate_data(seed_data=1, seed_assignment=1, keep_po=True) ate = np.mean(data[Y][data[W]==1]) - np.mean(data[Y][data[W]==0]) for learner, name in zip(learners, names): data['tau_hat'] = learner.effect(data[X]) data['q'] = pd.qcut(-data.tau_hat + np.random.normal(0, 1e-8, len(data)), q=Q, labels=False) for q in range(Q): temp = data[data.q <= q] uplift = (np.mean(temp[Y][temp[W]==1]) - np.mean(temp[Y][temp[W]==0])) * q / (Q-1) df_q = pd.concat([df_q, pd.DataFrame({'q': [q], 'uplift': [uplift], 'learner': [name]})], ignore_index=True) fig, ax = plt.subplots(1, 1, figsize=(8, 5)) sns.lineplot(x=range(Q), y=ate*range(Q)/(Q-1), color='k', ls='--', lw=3) sns.lineplot(x='q', y='uplift', hue='learner', data=df_q); plt.suptitle('提升曲线', y=1.02, fontsize=28, fontweight='bold') plt.title('值越高越好', fontsize=14, fontweight=None, y=0.96)generate_uplift_curve(df)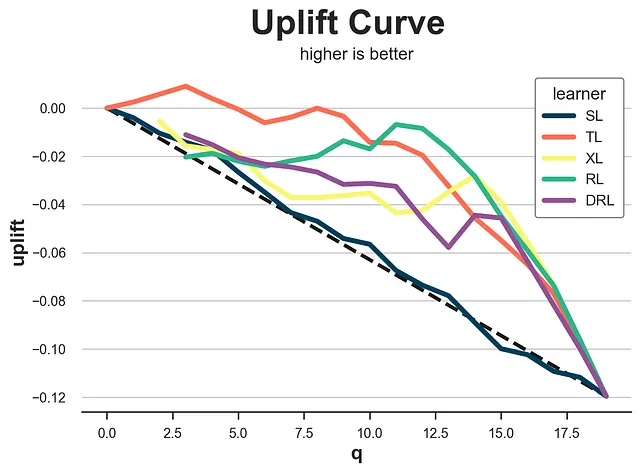
虽然提升曲线可能不是评估提升模型的最佳方法,但它在理解和实施这些模型方面非常重要。事实上,对于每个模型,它告诉我们当我们增加受治疗人群的比例(x轴)时,预期的平均治疗效应(y轴)是多少。
最近邻匹配
我们分析过的最后几种方法使用聚合数据来了解这些方法在较大群体上的效果。而最近邻匹配则尝试了解提升模型预测个体治疗效应的能力。然而,由于个体治疗效应是不可观测的,它试图通过在可观测特征X上匹配治疗组和对照组的观测来构建一个代理。
例如,如果我们获取所有治疗观测(i: Wᵢ=1),并在对照组中找到最近的邻居(NN₀(Xᵢ)),则对应的MSE损失函数为
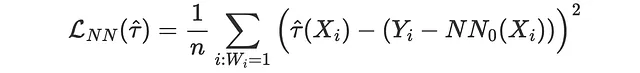
from scipy.spatial import KDTreedef loss_nn(data, learner): tau_hat = learner.effect(data[X]) nn0 = KDTree(data.loc[data[W]==0, X].values) control_index = nn0.query(data.loc[data[W]==1, X], k=1)[-1] tau_nn = data.loc[data[W]==1, Y].values - data.iloc[control_index, :][Y].values return np.mean((tau_hat[data[W]==1] - tau_nn)**2)results = compare_methods(learners, names, loss_nn, title='最近邻损失')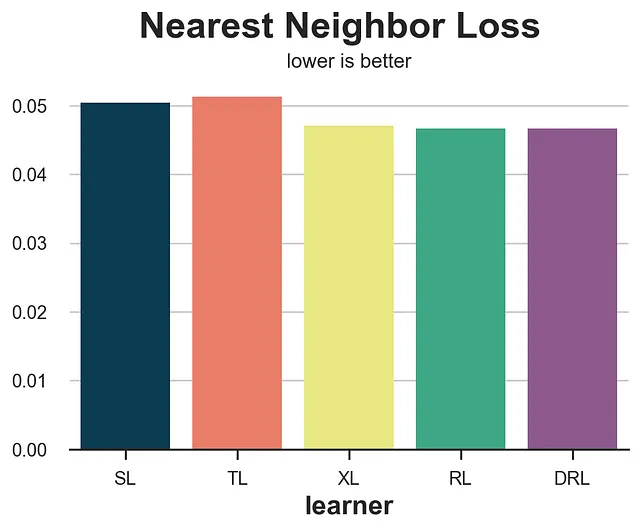
在这种情况下,最近邻损失表现得相当不错,识别出了两种表现最差的方法,S-和T-learner。
IPW损失
反向概率加权(IPW)损失函数首次由Gutierrez和Gerardy(2017)提出,它是我们将要看到的三个使用伪结果Y*评估估计器的度量中的第一个。伪结果是其期望值为条件平均治疗效应的变量,但由于太不稳定而不能直接用作估计。关于伪结果的更详细解释,我建议阅读我关于因果回归树的文章。与IPW损失对应的伪结果为
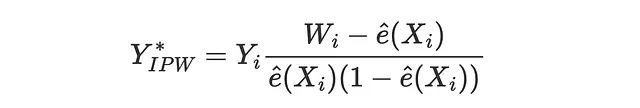
因此,相应的损失函数为
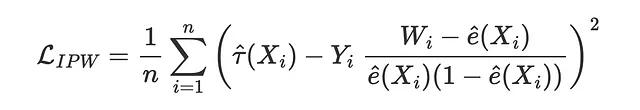
def loss_ipw(data, learner): tau_hat = learner.effect(data[X]) e_hat = clone(model_e).fit(data[X], data[W]).predict_proba(data[X])[:,1] tau_gg = data[Y] * (data[W] - e_hat) / (e_hat * (1 - e_hat)) return np.mean((tau_hat - tau_gg)**2)results = compare_methods(learners, names, loss_ipw, title='IPW损失')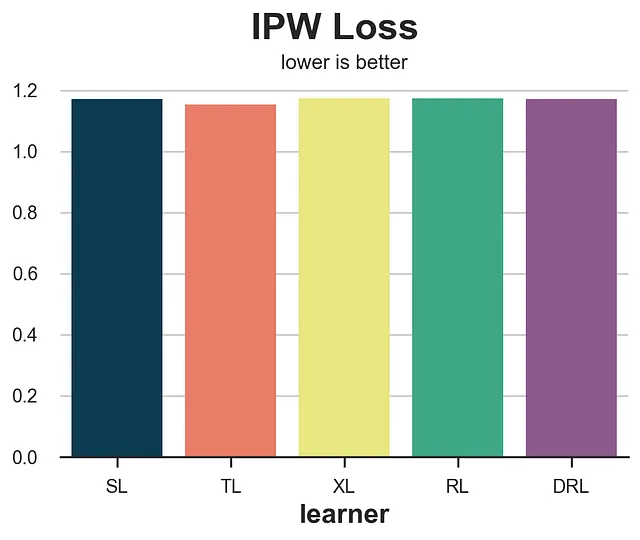
IPW损失函数非常嘈杂。解决方案是使用其更稳健的变体,即R损失或DR损失,下面我们将介绍这两种方法。
R损失
R损失是由Nie,Wager(2017)与R-learner一起引入的,它实质上是R-learner的目标函数。与IPW损失一样,其思想是尝试匹配一个伪结果,其期望值是条件平均处理效应。
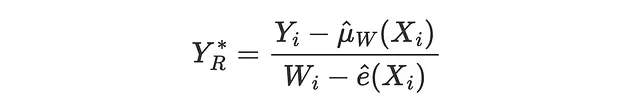
相应的损失函数为

def loss_r(data, learner): tau_hat = learner.effect(data[X]) y_hat = clone(model_y).fit(df[X + [W]], df[Y]).predict(data[X + [W]]) e_hat = clone(model_e).fit(df[X], df[W]).predict_proba(data[X])[:,1] tau_nw = (data[Y] - y_hat) / (data[W] - e_hat) return np.mean((tau_hat - tau_nw)**2)compare_methods(learners, names, loss_r, title='R损失')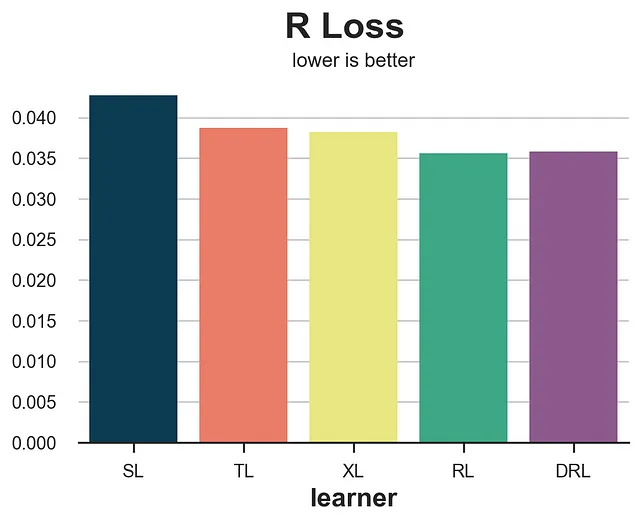
R损失比IPW损失明显更平滑,而且清楚地将S-learner与其他方法区分开来。然而,它倾向于偏好其相应的学习器,即R-learner。
DR损失
DR损失是DR-learner的目标函数,由Saito,Yasui(2020)首次引入。与IPW损失和R损失一样,其思想是尝试匹配一个伪结果,其期望值是条件平均处理效应。DR伪结果与AIPW估计量(也称为双重稳健估计量)密切相关,因此得名DR。
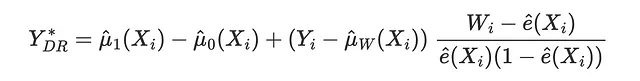
相应的损失函数为
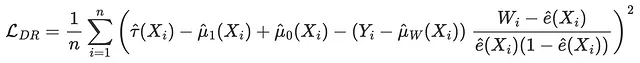
def loss_dr(data, learner): tau_hat = learner.effect(data[X]) y_hat = clone(model_y).fit(df[X + [W]], df[Y]).predict(data[X + [W]]) mu1 = clone(model_y).fit(df[X + [W]], df[Y]).predict(data[X + [W]].assign(mail=1)) mu0 = clone(model_y).fit(df[X + [W]], df[Y]).predict(data[X + [W]].assign(mail=0)) e_hat = clone(model_e).fit(df[X], df[W]).predict_proba(data[X])[:,1] tau_nw = mu1 - mu0 + (data[Y] - y_hat) * (data[W] - e_hat) / (e_hat * (1 - e_hat)) return np.mean((tau_hat - tau_nw)**2)results = compare_methods(learners, names, loss_dr, title='DR损失')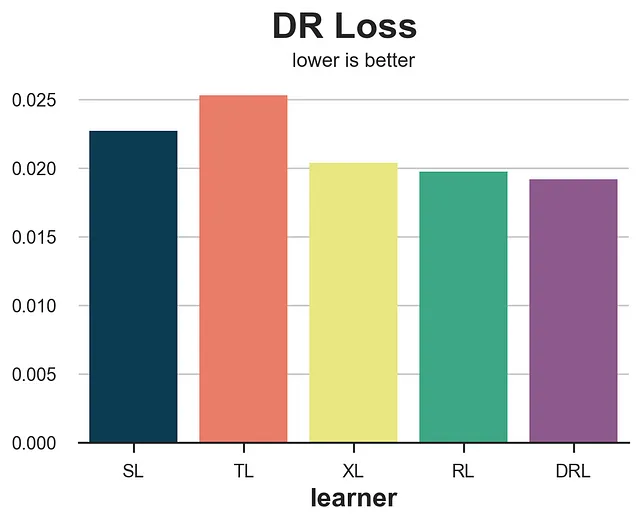
就R-loss而言,DR-loss倾向于支持其对应的学习器,即DR-learner。然而,从算法准确性的角度来看,它提供了更准确的排序。
经验策略增益
我们将要分析的最后一个损失函数与我们迄今为止看到的所有其他损失函数都不同,因为它不关注我们能够多好地估计治疗效应,而是关注相应的最优治疗策略的表现如何。具体而言,Hitsch、Misra、Zhang(2023)提出了以下增益函数:
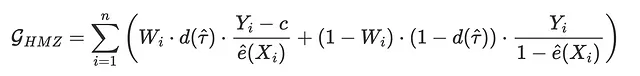
其中c是治疗成本,d是给定估计的CATE τ̂(Xᵢ)的最优治疗策略。在我们的案例中,我们假设每个个体的治疗成本为c=0.01美元,因此最优策略是对估计的CATE大于0.01的每个客户进行治疗。
术语Wᵢ⋅d(τ̂)和(1-Wᵢ)⋅(1-d(τ̂))意味着我们仅使用实际治疗W与最优治疗策略d相对应的个体进行计算。
def gain_policy(data, learner): tau_hat = learner.effect(data[X]) e_hat = clone(model_e).fit(data[X], data[W]).predict_proba(data[X])[:,1] d = tau_hat > cost return np.sum((d * data[W] * (data[Y] - cost)/ e_hat + (1-d) * (1-data[W]) * data[Y] / (1-e_hat)))results = compare_methods(learners, names, gain_policy, title='经验策略增益', subtitle='值越高越好')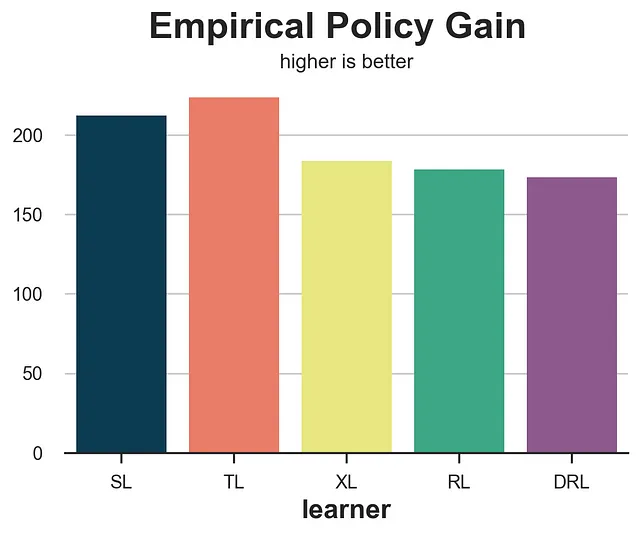
经验策略增益表现非常好,将最差的两种方法,即S-学习器和T-学习器,隔离开来。
元研究
在本文中,我们介绍了多种评估提升模型的方法,即条件平均治疗效应估计器。我们还在我们的模拟数据集上进行了测试,这是一个非常特殊和有限的示例。这些指标在一般情况下的表现如何?
Schuler、Baiocchi、Tibshirani、Shah(2018)比较了S-loss、T-loss、R-loss在模拟数据上对应的估计器。他们发现R-loss“是验证集度量,当优化时,最一致地导致选择高性能模型”。作者还发现了所谓的相似性偏差:诸如R-loss或DR-loss的指标倾向于偏向相应的学习器。
Curth、van der Schaar(2023)从理论角度研究了更广泛的学习器。他们发现“在我们考虑的所有实验条件下,没有现有的选择标准在全局范围内是最好的”。
Mahajan、Mitliagkas、Neal、Syrgkanis(2023)是在范围上最为全面的研究。作者在144个数据集和415个估计器上比较了许多指标。他们发现“没有任何指标明显占优”,但“使用DR元素的指标似乎总是在候选赢家中”。
结论
在本文中,我们探讨了多种评估提升模型的方法。主要挑战是无法观测到感兴趣的变量,即个体治疗效应。因此,不同的方法尝试使用其他变量,使用代理结果或近似暗示最优策略的效果来评估提升模型。
由于在理论和实证角度上都没有关于哪种方法表现最佳的共识,因此很难建议使用单一方法。使用 R 和 DR 元素的损失函数往往表现得更好,但也对相应的学习器有偏见。然而,了解这些度量如何工作可以帮助我们理解它们的偏见和局限性,以便根据具体情况做出最合适的决策。
参考文献
- Curth, van der Schaar (2023), “In Search of Insights, Not Magic Bullets: Towards Demystification of the Model Selection Dilemma in Heterogeneous Treatment Effect Estimation”
- Gutierrez, Gerardy (2017), “Causal Inference and Uplift Modeling: A review of the literature”
- Hitsch, Misra, Zhang (2023), “Heterogeneous Treatment Effects and Optimal Targeting Policy Evaluation”
- Kennedy (2022), “Towards optimal doubly robust estimation of heterogeneous causal effects”
- Kunzel, Sekhon, Bickel, Yu (2017), “Meta-learners for Estimating Heterogeneous Treatment Effects using Machine Learning”
- Mahajan, Mitliagkas, Neal, Syrgkanis (2023), “Empirical Analysis of Model Selection for Heterogeneous Causal Effect Estimation”
- Nie, Wager (2017), “Quasi-Oracle Estimation of Heterogeneous Treatment Effects”
- Saito, Yasui (2020), “Counterfactual Cross-Validation: Stable Model Selection Procedure for Causal Inference Models”
- Schuler, Baiocchi, Tibshirani, Shah (2018), “A comparison of methods for model selection when estimating individual treatment effects”
相关文章
- 理解元学习器
- 理解 AIPW,双重一致估计器
- 理解因果树
- 从因果树到森林
代码
你可以在这里找到原始的 Jupyter Notebook:
Blog-Posts/notebooks/evaluate_uplift.ipynb at main · matteocourthoud/Blog-Posts
我的 VoAGI 博客文章的代码和笔记本。通过创建一个贡献来协助 matteocourthoud/Blog-Posts 的开发…
github.com
谢谢阅读!
非常感谢!🤗 如果你喜欢这篇文章并想看更多,请考虑关注我。我每周发布有关因果推断和数据分析的主题。我试图保持文章简洁但准确,始终提供代码、示例和模拟。
另外,一个小免责声明:我写作是为了学习,所以错误是常态,尽管我尽力避免。如果你发现错误,请告诉我。我也欢迎对新主题的建议!




