机器学习中的特征工程实践方法
机器学习特征工程实践方法

特征学习是机器学习的重要组成部分,但往往很少被谈论,许多指南和博客文章都集中在ML生命周期的后期阶段。这个支持性的步骤可以使机器学习模型更准确、更高效,将原始数据转化为更具体且可用的形式。没有它,建立一个完全优化的模型是不可能的。
在本文中,我们将讨论特征学习在机器学习中的工作原理以及如何通过简单、实用的步骤来实现它。此外,我们还将讨论一些ML的缺点,全面概述这个重要过程。
什么是特征工程?
特征工程是一种重要的机器学习(ML)技术,它处理数据集并将其转化为与特定任务相关的可用数字集。
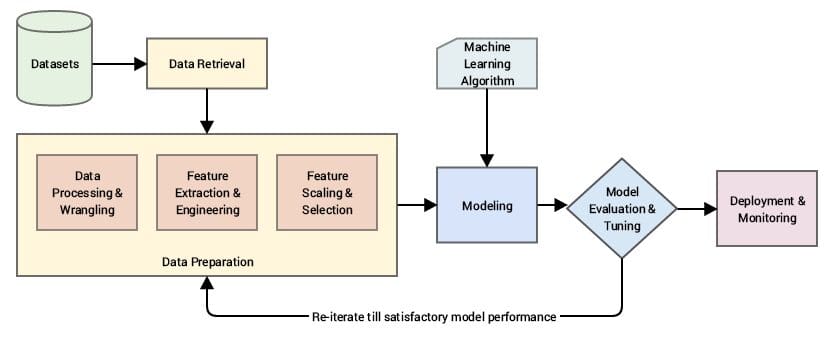
特征是被分析的数据元素,在数据集中以列的形式出现。通过纠正、排序和归一化这些数据元素,可以优化模型以提高性能。特征学习修改这些数据元素使其相关,从而使模型更准确,并且由于使用的变量更少,响应时间更快。
特征工程的过程可以分为以下几个步骤:
- 对数据进行分析,纠正发现的任何问题,如不完整的字段、不一致和其他异常。
- 删除与模型行为无关的任何变量。
- 删除重复的数据。
- 对记录进行相关性和归一化处理。
为什么特征工程在机器学习中如此重要?
没有特征工程,设计能够准确执行其功能的预测模型将是不可能的。特征学习还减少了所需的时间和计算资源,使模型更高效。
数据的特征决定了预测模型的工作方式,有助于训练每个模型以实现预期结果。这意味着即使数据对特定功能不完全适用,也可以进行修改以实现合适的结果。特征学习还显著减少了以后进行数据分析所花费的时间。
特征工程的好处和缺点
虽然特征学习是必不可少的,但它也有一些限制,以及明显的好处,如下所列。
特征工程的好处
- 具有工程特征的模型受益于更快的数据处理。
- 模型更简化,因此更易于维护。
- 预测和估计更准确。
特征工程的缺点
- 特征工程可能是一个耗时的过程。
- 需要进行深入分析才能构建有效的特征列表。这包括对数据集、模型的处理行为和业务背景的全面理解。
机器学习中特征工程的实用方法:六个步骤
现在我们更好地理解了特征学习的作用以及它的缺点,让我们考虑一个实用的六个关键步骤的处理过程。
#1 数据准备
特征工程过程中的第一步是将从各种来源收集到的原始数据转化为可用的格式。可用的ML格式包括:.csc;.tfrecords;.json;.xml;和.avro。为了准备数据,它必须经过一系列的过程,如清理、融合、摄取和加载。
#2 数据分析
分析阶段,有时称为探索阶段,是从数据集中提取洞察力和描述性统计信息,并以可视化方式呈现以更好地理解数据的阶段。然后识别相关变量及其属性,以便清理它们。
#3 改进
一旦数据经过分析和清洗,就需要通过添加缺失值、标准化、转换和缩放来改进数据。数据还可以通过添加虚拟值来进一步修改,虚拟值是表示分类数据的定性/离散变量。
#4 构建
特征可以通过手动和自动使用算法(例如tSNE或主成分分析(PCA))进行构建。在特征构建方面有几乎无穷无尽的选择。然而,解决方案始终取决于问题。
#5 选择
特征/变量/属性选择通过仅选择对模型预测的变量最相关的变量(特征列)来减少输入变量(特征列)的数量。这有助于提供更好的处理速度并减少计算资源的使用。
特征选择技术包括:
- 使用过滤器去除任何无关的特征。
- 使用封装器训练机器学习模型使用多个特征
- 结合过滤器和封装器的混合模型
例如,基于过滤器的技术依赖于统计测试来确定特征与目标变量的相关程度是否足够。
#6 评估和验证
评估过程使用所选择的特征来确定模型在训练数据上的准确性。如果准确性达到所需标准,则可以验证模型。如果不符合要求,则需要重新进行特征选择阶段。
特征工程应用案例
现在让我们看一下机器学习中特征工程的三个常见应用案例。
从相同数据集中获取额外见解
许多数据集包含任意值,如日期、年龄等,可以将其修改为提供有关查询的特定信息的不同格式。例如,可以交叉引用日期和持续时间详细信息,以确定用户行为,例如他们访问网站的频率和在网站上花费的时间。
预测模型
选择正确的特征可以帮助建立多个行业的预测模型,其中一个行业可以从这样的模型中受益的是公共交通,可以帮助估计在特定日期有多少乘客使用服务。
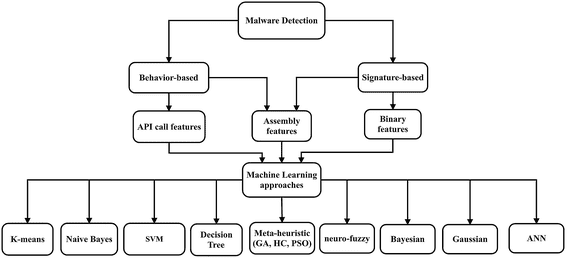
恶意软件检测
手动检测恶意软件非常困难,大多数神经网络在这方面也存在问题。然而,特征工程可以将手动技术和神经网络结合起来,突出异常行为。
机器学习中的特征工程:结论
特征工程是构建机器学习模型时的重要阶段,正确进行这个阶段可以确保机器学习模型更准确、使用更少的计算资源并具有更高的处理速度。
特征工程过程可以分为六个阶段,从初始数据准备到验证,只选择与特定任务最相关的数据元素。 Nahla Davies 是一位软件开发人员和技术作家。在全职从事技术写作之前,她曾担任一家Inc. 5000经验品牌组织的首席程序员,其客户包括三星、时代华纳、Netflix和索尼。






