了解机器学习分类问题的不同性能指标
机器学习分类问题的性能指标
这篇文章将教你机器学习分类任务中使用的不同性能度量。文章还将介绍这些性能度量的正确使用。
让我们从一个问题开始:性能度量是什么意思?
在机器学习的背景下,我们可以将性能度量视为一种测量工具,它将告诉我们训练模型的好坏程度。
通常,“准确率”被视为一种标准的性能度量。但在分类问题的情况下,这种方法存在一个缺点。让我们用一个例子来理解这一点。
假设我们有一个包含100行的验证数据集。目标列只有两个唯一值,分别是“A”和“B”(典型的二分类问题)。假设在我们的验证数据集的目标列中有80个“A”和20个“B”。现在让我们使用一个基本模型,无论输入特征如何,它总是输出“A”来预测我们的验证数据集的输出。由于这个模型非常简单,它很可能对数据欠拟合,并且在新数据上的泛化能力不强。但是,我们在验证数据上获得了80%的准确率。这是非常误导人的。
这种数据集,其中某些类别比其他类别更频繁出现,被称为不平衡或倾斜数据集。对于不平衡数据集,准确率度量会给出误导性的结果。因此,我们需要其他一些方法来衡量模型的性能。
不建议在不平衡数据集上使用准确率性能度量。
注意:在平衡数据集上使用准确率度量是可以的。
让我们学习一些其他的性能度量。
- 混淆矩阵
- 精确率
- 召回率
- F1值
- 受试者工作特征(ROC)曲线下的面积
混淆矩阵
混淆矩阵的基本思想是计算“A”被错误分类为“B”和反之亦然的次数。
要计算混淆矩阵,首先需要有预测结果可以与实际目标值进行比较。
混淆矩阵的每一行代表一个实际类别,而每一列代表一个预测类别。
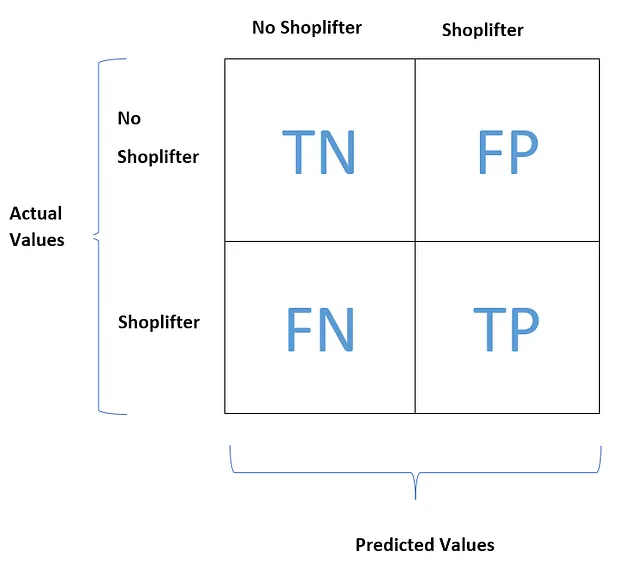
让我们以一个目标列具有名为“A”和“B”的唯一类别的例子为例。我们在这里将B称为非A。
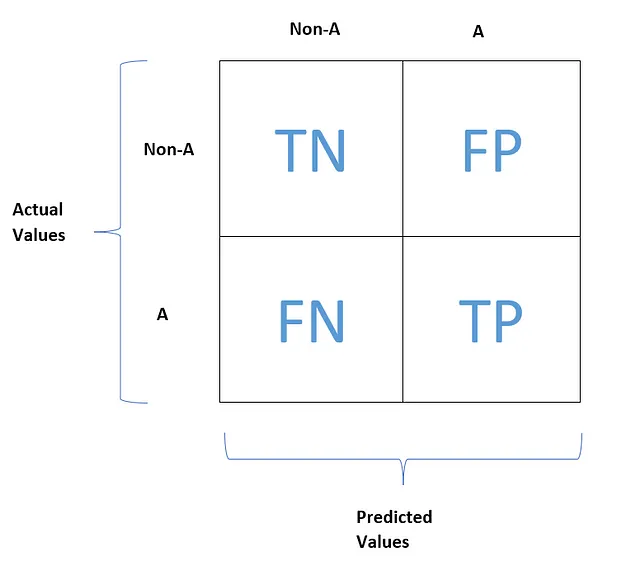
这是一个典型的混淆矩阵的样子。
TN、FP、FN和TP分别代表真负、假正、假负和真正。现在让我们理解一下这些术语的含义。
真负(TN)表示被正确预测为负(非A)的负特征值的数量。
假正(FP)表示被错误预测为正的负特征值(非A)的数量。
假负(FN)表示被错误预测为负的正特征值(A)的数量。
真正(TP)表示被正确预测为正的正特征值(A)的数量。
当以下条件满足时,我们可以将分类器视为完美的分类器:
- FP = FN = 0
- TP ≥ 0且TN ≥ 0
换句话说,完美分类器的混淆矩阵只有在其主对角线上才有非零值。
混淆矩阵将为您提供有关模型性能的大量信息。另外,它是一个矩阵,因此很难一眼就能理解。因此,我们希望有一种更简洁的度量方式来衡量模型的性能。
精确率、召回率和F1分数
精确率和召回率为模型的性能测量提供了简洁的指标。
精确率可以被认为是正例预测的准确性。可以通过查看混淆矩阵来轻松找到精确率。

另外,召回率可以通过正确预测的正例观测数量与正例观测总数的比率来计算。

召回率也有其他名称,比如敏感性或真正例率。
通常方便将精确率和召回率结合到一个称为F1分数的单个指标中,特别是如果你想要一个简单的方法来比较两个分类器。
精确率和召回率的调和平均值称为F1分数。

通常,调和平均值会给较低的值更多的权重。这就是为什么如果精确率和召回率都很高,分类器将获得较高的F1分数。
但这并不是每次都是这样。在某些情况下,您可能需要更高的精确率和较低的召回率,在其他一些情况下,您可能还需要较低的精确率和较高的召回率。这取决于手头的任务。让我们举两个例子来理解这个问题。
例子1:
假设您训练了一个用于检测适合儿童的视频的分类器。对于这个分类器来说,如果一些安全视频被预测为非安全视频是可以接受的。但是,非安全视频被预测为安全视频的次数应该尽可能低。这意味着我们对这个分类器应该有严格的条件,即高的FN和低的FP。
高的FN意味着低的召回率,低的FP意味着高的精确率。

例子2:
假设您训练了一个用于在监控摄像头中检测扒手的分类器。在这种情况下,如果一个无辜的人被预测为扒手(从道德上讲,这是不正确的,但只考虑机器学习的上下文),这是可以接受的。但是,扒手被预测为无辜的人的次数应该尽可能低。这意味着我们对这个分类器应该有严格的条件,即低的FN和高的FP。
低的FN意味着高的召回率,高的FP意味着低的精确率。
让我们回到高召回率和高精确率的情况。不幸的是,在实际情况下这是不可能的。我们要么得到高召回率和低精确率,要么得到低召回率和高精确率。
在这种情况下,我们将尝试查看精确率-召回率曲线,并选择图上精确率和召回率都相对较高的点,根据你的任务来决定。
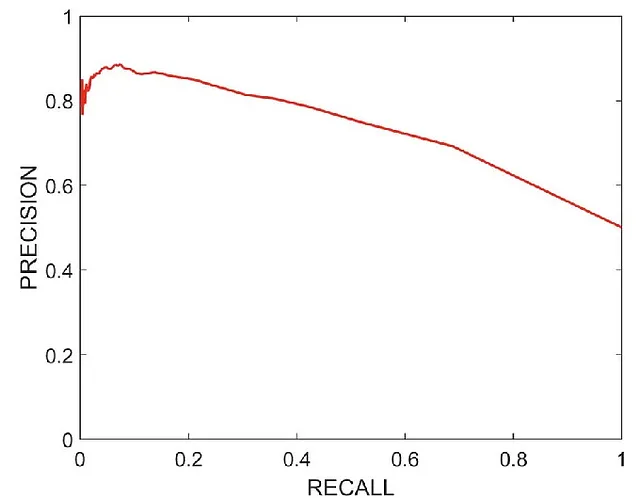
这是一个典型的精确率-召回率曲线。通过观察图表,我们可以得到召回率=0.65和精确率=0.75的点。对于这个点,我们得到了相对较高的精确率和召回率。
接收者操作特征(ROC)曲线
ROC曲线用作二分类问题的度量标准。ROC曲线绘制了真正例率(即召回率)与假正例率之间的关系。
这是典型ROC曲线的样子。
可以使用以下公式找到真正率(TPR)和假正率(FPR)。
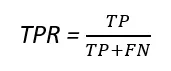
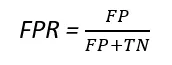
虚线表示纯随机分类模型的ROC曲线;一个好的分类器应尽可能远离该线(向左上角)。
我们可以通过计算曲线下面积来衡量我们的模型与随机模型ROC曲线的差距。如果我们模型的ROC曲线下面积等于1,则说明它与随机模型ROC曲线的差距最大。因此,在这种情况下,我们的模型可以被认为是一个完美的模型。ROC曲线下面积越大的模型将是更好的模型。
ROC曲线下面积可用于比较两个分类器。ROC曲线下面积较大的分类器在性能方面更好。
何时使用精确率-召回率曲线,何时使用ROC曲线?
作为经验法则,当正类别较为罕见或者您更关心假阳性而不是假阴性时,应优先选择精确率-召回率曲线。否则,请使用ROC曲线。
例如,如果我们研究的是一种罕见疾病的感染情况,则我们会得到罕见的正类别。在这种情况下,精确率-召回率曲线将是更好的性能度量。
进一步阅读:
scikit-learn文档
书籍《使用Scikit-Learn、Keras和TensorFlow进行实践机器学习》
(1527) The NO CONFUSION matrix! // What is the confusion matrix? // Confusion matrix visual explanation — YouTube
(1527) Never Forget Again! // Precision vs Recall with a Clear Example of Precision and Recall — YouTube
结束语
希望您喜欢这篇文章。关注我在VoAGI上阅读更多类似的文章。
与我联系:
网站




