如何分块文本数据——一项比较分析
文本数据分块分析方法
探索文本分块的不同方法。
简介
自然语言处理(NLP)中的“文本分块”过程涉及将非结构化文本数据转化为有意义的单元。这个看似简单的任务掩盖了实现它所采用的各种方法的复杂性,每种方法都有其优点和缺点。
从高层次来看,这些方法通常分为两类。第一类是基于规则的方法,依赖于明确的分隔符,如标点符号或空格字符,或者应用复杂的系统(如正则表达式)将文本分割成块。第二类是基于语义聚类的方法,利用文本中固有的含义来指导分块过程。这些方法可能利用机器学习算法来识别上下文并推断文本中的自然分割。
在本文中,我们将探索和比较这两种不同的文本分块方法。我们将使用NLTK、Spacy和Langchain来代表基于规则的方法,并将其与两种不同的语义聚类技术进行对比:KMeans和自定义的相邻句子聚类技术。
我们的目标是使从业者对每种方法的优缺点和理想用例有清晰的理解,以便在他们的NLP项目中做出更好的决策。
在巴西俚语中,“abacaxi”意为“菠萝”,表示“没有好结果、一团乱麻或不好的东西”。
文本分块的用例
文本分块可以被多种不同的应用程序使用:
- 文本摘要:通过将大段文本分解为可管理的块,我们可以单独总结每个部分,从而得到更准确的总结。
- 情感分析:分析较短、连贯的块的情感往往比分析整个文档产生更精确的结果。
- 信息提取:分块有助于定位文本中的特定实体或短语,增强信息检索过程。
- 文本分类:将文本分解为块,使分类器能够关注更小、上下文相关的有意义的单元,而不是整个文档,这可以提高性能。
- 机器翻译:翻译系统通常处理文本块而不是单个单词或整个文档。分块可以帮助保持翻译文本的连贯性。
了解这些用例可以帮助您选择适合您特定项目的最合适的分块技术。
比较语义分块的不同方法
在本文的这一部分,我们将比较用于非结构化文本的语义分块的流行方法:NLTK句子分词器、Langchain文本分割器、KMeans聚类和基于相似性的相邻句子聚类。
在以下示例中,我们将使用从PDF中提取的文本对这种技术进行评估,将其处理为句子和它们的聚类。
我们使用的数据是从巴西维基百科页面导出的PDF。
为了从PDF中提取文本并使用NLTK将其分割成句子,我们使用以下函数:
from PyPDF2 import PdfReaderimport nltknltk.download('punkt')# 从PDF中提取文本def extract_text_from_pdf(file_path): with open(file_path, 'rb') as file: pdf = PdfReader(file) text = " ".join(page.extract_text() for page in pdf.pages) return text# 从PDF中提取文本并将其分割成句子text = extract_text_from_pdf(file_path)这样,我们得到了一个长度为210964个字符的字符串text。
以下是维基文本的示例:
sample = text[1015:3037]print(sample)"""=======Output:=======巴西是世界上面积第五大的国家,人口第七多。它的首都是巴西利亚,人口最多的城市是圣保罗。该联邦由26个州和联邦区组成。它是美洲唯一以葡萄牙语为官方语言的国家。由于过去一个多世纪以来从世界各地大量移民,巴西是最多元化和种族多样化的国家之一。它是人口最多的天主教国家。巴西东临大西洋,有7491公里(4655英里)的海岸线。它与南美洲的所有其他国家和地区接壤,除了厄瓜多尔和智利,覆盖了大约一半的大陆土地面积。其亚马逊流域包括广阔的热带森林,是多样的野生动植物、各种生态系统和广泛的自然资源的家园,涵盖了众多受保护的栖息地。这一独特的环境遗产使巴西成为17个超级多样性国家中的第一名,并引起了全球的重大关注,因为像森林砍伐这样的环境破坏对气候变化和生物多样性损失等全球问题产生直接影响。巴西的领土在1500年被探险家佩德罗·阿尔瓦雷斯·卡布拉尔发现之前,由众多部落国家居住。巴西一直是葡萄牙的殖民地,直到1808年帝国的首都从里斯本转移到里约热内卢。1815年,该殖民地被提升为葡萄牙、巴西和阿尔加夫联合王国的王国等级。1822年实现了独立,建立了巴西帝国,这是一个统一的国家,在宪政君主制和议会制度下治理。1824年第一部宪法的批准导致了两院制立法机构的形成,现在称为国民议会。"""NLTK句子分词器
自然语言处理工具包(NLTK)提供了一个有用的函数,用于将文本分割为句子。这个句子分词器将给定的文本块分割成组成的句子,然后可以用于进一步处理。
实现
下面是使用NLTK句子分词器的示例:
import nltknltk.download('punkt')# 将文本分割为句子def split_text_into_sentences(text): sentences = nltk.sent_tokenize(text) return sentencessentences = split_text_into_sentences(text)这将返回从输入文本中提取的2670个句子的列表,每个句子平均包含78个字符。
评估NLTK句子分词器
尽管NLTK句子分词器是将大段文本分割为单独句子的一种简单高效的方法,但它也有一些限制:
- 语言依赖性:NLTK句子分词器在很大程度上依赖于文本的语言。它在处理英语时表现良好,但在没有额外配置的情况下,可能无法提供准确的结果。
- 缩写和标点符号:分词器有时会错误解释句子末尾的缩写或其他标点符号。这可能导致句子的片段被视为独立的句子。
- 缺乏语义理解:像大多数分词器一样,NLTK句子分词器不考虑句子之间的语义关系。因此,跨多个句子的上下文可能在分词过程中丢失。
Spacy句子分割器
Spacy是另一个强大的自然语言处理库,它提供了一个依赖于语言规则的句子分词函数。它与NLTK的方法相似。
实现
实现Spacy的句子分割器非常简单。以下是在Python中如何做到这一点:
import spacynlp = spacy.load('en_core_web_sm')doc = nlp(text)sentences = list(doc.sents)这将返回从输入文本中提取的2336个句子的列表,每个句子平均包含89个字符。
评估Spacy句子分割器
与Langchain字符文本分割器相比,Spacy的句子分割器倾向于创建更小的块,因为它严格遵守句子边界。当需要进行分析时,这可能是有利的。
然而,与NLTK一样,Spacy的性能取决于输入文本的质量。对于标点符号或结构不良的文本,识别的句子边界可能并不总是准确的。
现在,我们将看到Langchain如何为文本数据提供分块框架,并将其与NLTK和Spacy进行进一步比较。
Langchain字符文本分割器
Langchain字符文本分割器通过递归地在特定字符处分割文本。它对于通用文本特别有用。
该分割器由字符列表定义。它尝试根据这些字符将文本分割,直到生成的块满足所需的大小标准。默认列表为[“\n\n”, “\n”, ” “,”“],旨在尽可能保持段落、句子和单词的语义连贯性。
实现
考虑以下示例,我们使用此方法分割从我们的PDF中提取的示例文本。
# 使用自定义参数初始化文本分割器custom_text_splitter = RecursiveCharacterTextSplitter( # 设置自定义块大小 chunk_size = 100, chunk_overlap = 20, # 使用文本长度作为大小度量 length_function = len,)# 创建块texts = custom_text_splitter.create_documents([sample])# 打印前两个块print(f'### 块1: \n\n{texts[0].page_content}\n\n=====\n')print(f'### 块2: \n\n{texts[1].page_content}\n\n=====')"""=======输出:=======### 块1: Brazil是世界上面积第五大的国家,也是人口第七多的国家。它的首都=====### 块2: 是巴西利亚,最多人口的城市是圣保罗。联邦由====="""最后,我们得到了3205个文本块,由texts列表表示。这里每个块的平均长度为65.8个字符,比NLTK的平均长度(79个字符)稍短。
更改参数并使用’\n’作为分隔符:
对于Langchain Splitter的更定制化方法,我们可以根据需要修改chunk_size和chunk_overlap参数。此外,我们还可以指定一个字符(或一组字符)作为分割操作的分隔符,如\n。这将指导分割器仅在新行字符处将文本分成块。
让我们考虑一个例子,我们将chunk_size设置为300,chunk_overlap设置为30,只使用\n作为分隔符。
# 使用自定义参数初始化文本分割器
custom_text_splitter = RecursiveCharacterTextSplitter(
# 设置自定义块大小
chunk_size=300,
chunk_overlap=30,
# 使用文本长度作为大小度量
length_function=len,
# 仅使用"\n\n"作为分隔符
separators=['\n']
)
# 创建自定义文本块
custom_texts = custom_text_splitter.create_documents([sample])
# 打印前两个文本块
print(f'### 文本块1:\n\n{custom_texts[0].page_content}\n\n=====\n')
print(f'### 文本块2:\n\n{custom_texts[1].page_content}\n\n=====')现在,让我们将一些标准参数和自定义参数的输出进行比较:
# 打印抽样的文本块
print("==== 从'标准参数'中抽样的文本块: ====\n\n")
for i, chunk in enumerate(texts):
if i < 4:
print(f"### 文本块{i+1}:\n{chunk.page_content}\n")
print("==== 从'自定义参数'中抽样的文本块: ====\n\n")
for i, chunk in enumerate(custom_texts):
if i < 4:
print(f"### 文本块{i+1}:\n{chunk.page_content}\n")
"""=======输出:=========== 从'标准参数'中抽样的文本块: ====### 文本块1:巴西是世界第五大国,面积居第七位。它的首都### 文本块2:是巴西利亚,最受欢迎的城市是圣保罗。该联邦由### 文本块3:由26个州和联邦区组成的联盟。它是美洲唯一一个以葡萄牙语为官方语言的国家。 从'自定义参数'中抽样的文本块: ====### 文本块1:巴西是世界第五大国,面积居第七位。它的首都是巴西利亚,最受欢迎的城市是圣保罗。该联邦由### 文本块2:由26个州和联邦区组成的联盟。它是美洲唯一一个以葡萄牙语为官方语言的国家。 从'标准参数'中抽样的文本块: ====### 文本块1:巴西是世界第五大国,面积居第七位。它的首都### 文本块2:是巴西利亚,最受欢迎的城市是圣保罗。该联邦由### 文本块3:由26个州和联邦区组成的联盟。它是美洲唯一一个以葡萄牙语为官方语言的国家。 从'自定义参数'中抽样的文本块: ====### 文本块1:巴西是世界第五大国,面积居第七位。它的首都是巴西利亚,最受欢迎的城市是圣保罗。该联邦由### 文本块2:由26个州和联邦区组成的联盟。它是美洲唯一一个以葡萄牙语为官方语言的国家。它是一个多元文化和种族多样化程度最高的国家,这是由于一个多世纪以来### 文本块3:的世界各地的大规模移民以及最受欢迎的罗马天主教国家。巴西东临大西洋,拥有7491公里(4655英里)的海岸线。它### 文本块4:与南美洲的所有其他国家和领土接壤,除了厄瓜多尔和智利,占据了该大陆陆地面积的大约一半。其亚马逊流域包括一个广阔的热带森林,是许多不同种类的动植物栖息地。我们已经可以看到,这些自定义参数得到的文本块比默认参数得到的文本块要大得多,因此保留了更多的内容。
评估Langchain字符文本分割器
在使用不同参数将文本分割成块之后,我们得到了两个列表的文本块:texts和custom_texts,分别包含3205个和1404个文本块。现在,让我们绘制这两种情况下文本块长度的分布图,以更好地了解更改参数的影响。

在这个直方图中,x轴代表块的长度,y轴代表每个长度的频率。蓝色柱状图表示原始参数的块长度分布,橙色柱状图表示自定义参数的块长度分布。通过比较这两个分布,我们可以看到参数的变化如何影响最终的块长度。
请记住,理想的分布取决于文本处理任务的具体要求。如果您处理的是细粒度分析,您可能希望有更小、更多的块;如果是进行更广泛的语义分析,您可能希望有更大、更少的块。
Langchain字符文本分割器 vs. NLTK和Spacy
之前,我们使用Langchain分割器的默认参数生成了3205个块。而NLTK句子分词器将同一段文本分成了总共2670个句子。
为了更直观地了解这些方法之间的差异,我们可以可视化块长度的分布。下图显示了每种方法的块长度密度,让我们可以看到长度的分布情况以及大部分长度的位置。

从图1中我们可以看到,Langchain分割器产生了更简洁的聚类长度密度,并且更倾向于具有更长的聚类,而NLTK和Spacy似乎在聚类长度方面产生了非常相似的输出,更喜欢较小的句子,但也具有许多长度长达1400个字符的离群值,且长度呈下降趋势。
KMeans聚类
句子聚类是一种根据语义相似性对句子进行分组的技术。通过使用句子嵌入和K-means等聚类算法,我们可以实现句子聚类。
实现
下面是使用Python库sentence-transformers生成句子嵌入以及使用scikit-learn进行K-means聚类的简单示例代码片段:
from sentence_transformers import SentenceTransformerfrom sklearn.cluster import KMeans# 加载句子嵌入模型model = SentenceTransformer('all-MiniLM-L6-v2')# 定义句子列表(您的文本数据)sentences = ["这是一个示例句子。", "另一个句子在这里。", "..."]# 为句子生成嵌入embeddings = model.encode(sentences)# 选择适当的聚类数(这里我们选择3作为示例)num_clusters = 3# 执行K-means聚类kmeans = KMeans(n_clusters=num_clusters)clusters = kmeans.fit_predict(embeddings)可以看到,对句子列表进行聚类的步骤如下:
- 加载句子嵌入模型。在此示例中,我们使用HuggingFace的sentence-transformers/all-MiniLM-L6-v2中的
all-MiniLM-L6-v2模型。 - 定义您的句子,并使用模型的
encode()方法生成它们的嵌入。 - 然后定义您的聚类技术和聚类数(这里我们使用KMeans并设定为3个聚类),最后将其拟合到数据集中。
评估KMeans聚类
最后,我们为每个聚类绘制一个词云图。
from wordcloud import WordCloudimport matplotlib.pyplot as pltfrom nltk.corpus import stopwordsfrom nltk.tokenize import word_tokenizeimport stringnltk.download('stopwords')# 定义停用词列表stop_words = set(stopwords.words('english'))# 定义一个清理句子的函数def clean_sentence(sentence): # 分词 tokens = word_tokenize(sentence) # 转换为小写 tokens = [w.lower() for w in tokens] # 去除标点符号 table = str.maketrans('', '', string.punctuation) stripped = [w.translate(table) for w in tokens] # 移除非字母的单词 words = [word for word in stripped if word.isalpha()] # 过滤停用词 words = [w for w in words if not w in stop_words] return words# 为每个聚类计算并打印词云for i in range(num_clusters): cluster_sentences = [sentences[j] for j in range(len(sentences)) if clusters[j] == i] cleaned_sentences = [' '.join(clean_sentence(s)) for s in cluster_sentences] text = ' '.join(cleaned_sentences) wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white").generate(text) plt.figure() plt.imshow(wordcloud, interpolation="bilinear") plt.axis("off") plt.title(f"Cluster {i}") plt.show()以下是生成的聚类的词云图:

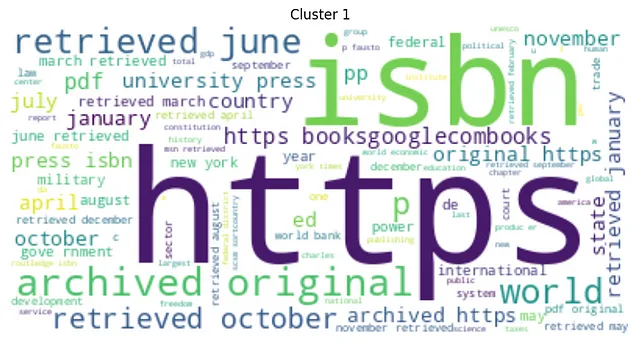

通过对KMeans聚类的词云分析,我们可以明显看出每个聚类在其最常见的词语的语义上有明显的区别。这表明聚类之间存在强烈的语义差异。此外,我们还观察到聚类大小的明显变化,表明每个聚类包含的序列数量存在显著差异。
KMeans聚类的局限性
尽管句子聚类有益,但也有一些明显的缺点。主要限制包括:
- 丢失句子顺序:句子聚类不会保留原始句子的顺序,这可能会扭曲叙述的自然流程。**这非常重要**
- 计算效率:KMeans在处理大型文本语料库或较大数量的聚类时可能会计算密集且较慢。这对实时应用程序或处理大数据来说是一个重要的缺点。
聚类相邻句子
为了克服KMeans聚类的一些限制,特别是句子顺序的丢失,一种替代方法是根据句子的语义相似性对相邻句子进行聚类。这种方法的基本假设是,文本中连续出现的两个句子比两个相隔较远的句子更可能在语义上相关。
实现
以下是使用Spacy句子作为输入的扩展实现:
import numpy as npimport spacy# 加载Spacy模型nlp = spacy.load('en_core_web_sm')def process(text): doc = nlp(text) sents = list(doc.sents) vecs = np.stack([sent.vector / sent.vector_norm for sent in sents]) return sents, vecsdef cluster_text(sents, vecs, threshold): clusters = [[0]] for i in range(1, len(sents)): if np.dot(vecs[i], vecs[i-1]) < threshold: clusters.append([]) clusters[-1].append(i) return clustersdef clean_text(text): # 在这里添加您的文本清理过程 return text# 初始化聚类长度列表和最终文本列表clusters_lens = []final_texts = []# 处理文本threshold = 0.3sents, vecs = process(text)# 聚类句子clusters = cluster_text(sents, vecs, threshold)for cluster in clusters: cluster_txt = clean_text(' '.join([sents[i].text for i in cluster])) cluster_len = len(cluster_txt) # 检查聚类是否太短 if cluster_len < 60: continue # 检查聚类是否太长 elif cluster_len > 3000: threshold = 0.6 sents_div, vecs_div = process(cluster_txt) reclusters = cluster_text(sents_div, vecs_div, threshold) for subcluster in reclusters: div_txt = clean_text(' '.join([sents_div[i].text for i in subcluster])) div_len = len(div_txt) if div_len < 60 or div_len > 3000: continue clusters_lens.append(div_len) final_texts.append(div_txt) else: clusters_lens.append(cluster_len) final_texts.append(cluster_txt)从这段代码中获取的关键要点:
- 文本处理:每个文本块都传递给
process函数。该函数使用SpaCy库创建句子嵌入,用于表示文本块中每个句子的语义含义。 - 聚类创建:函数
cluster_text根据句子嵌入的余弦相似度形成句子的聚类。如果余弦相似度小于指定阈值,则开始一个新的聚类。 - 长度检查:代码然后检查每个聚类的长度。如果一个聚类太短(少于60个字符)或太长(超过3000个字符),则调整阈值并对该特定聚类重复该过程,直到达到可接受的长度。
让我们来看一下这种方法的一些输出块,并将它们与Langchain Splitter进行比较:
==== 从 'Langchain Splitter with Custom Parameters' 中获取的示例块: ====### 块 1:巴西是世界第五大面积国家,也是人口第七大的国家。其首都是巴西利亚,人口最多的城市是圣保罗。联邦由26个州和联邦区组成。它是美洲唯一一个以葡萄牙语为官方语言的国家。[11][12]由于一个多世纪的多元文化和种族多样性,它是最多元文化和种族多样性的国家之一。=== 从 'Adjacent Sentences Clustering' 中获取的示例块: ====### 块 1:巴西是世界第五大面积国家,也是人口第七大的国家。其首都是巴西利亚,人口最多的城市是圣保罗。### 块 2:联邦由26个州和联邦区组成。它是美洲唯一一个以葡萄牙语为官方语言的国家。[11][12]好了,现在让我们比较final_texts(使用相邻序列聚类方法得到的)的块长度分布与Langchain字符文本分割器和NLTK句子分词器的分布。为此,我们首先需要计算final_texts中各个块的长度:
final_texts_lengths = [len(chunk) for chunk in final_texts]现在我们可以绘制所有三种方法的分布图:
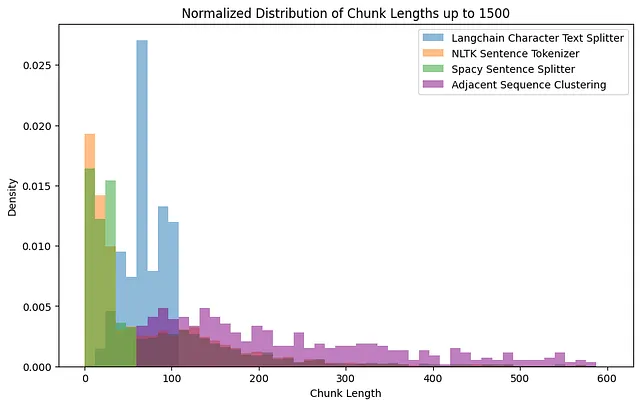
从图3可以看出,Langchain分割器使用其预定义的块大小创建了一个均匀的分布,表示块长度一致。
另一方面,Spacy句子分割器和NLTK句子分词器似乎更喜欢较小的句子,尽管存在许多较大的异常值,这表明它们依赖于语言线索来确定分割点,并可能产生不规则大小的块。
最后,基于语义相似性进行聚类的自定义相邻序列聚类方法展现了更多样化的分布。这可能表明这种方法更具上下文敏感性,保持块内内容的连贯性,同时允许更大的灵活性。
评估相邻序列聚类方法
相邻序列聚类方法带来了独特的好处:
- 上下文连贯性:通过考虑语义和上下文连贯性生成具有主题一致性的块。
- 灵活性:平衡上下文保留和计算效率,提供可调整的块大小。
- 阈值调整:允许用户根据自己的需求微调分块过程,通过调整相似度阈值。
- 序列保留:保留文本中句子的原始顺序,对于顺序语言模型和文本顺序很重要的任务至关重要。
比较文本分块方法:洞察总结
Langchain字符文本分割器
这种方法提供一致的块长度,产生均匀的分布。这在需要下游处理或分析的标准尺寸时可能是有益的。这种方法对文本的特定语言结构不太敏感,更关注产生预定义字符长度的块。
NLTK句子分词器和Spacy句子分割器
这些方法更倾向于较小的句子,但也包括许多较大的异常值。这可能导致在块大小上有更高的变异性,但也可能导致更具语言连贯性的块。
这些方法也可以产生良好的结果,可作为下游任务的输入。
相邻序列聚类
这种方法生成更多样化的分布,表明其上下文敏感的方法。通过基于语义相似性进行聚类,它确保每个块内的内容连贯,同时允许灵活的块大小。当重要的是保持文本数据的语义连续性时,这种方法可能是有优势的。
为了更直观和抽象(或愚蠢)地表示,让我们看一下下面的第7张图,并尝试找出哪种“切割”菠萝的方式更好地表示所讨论的方法:
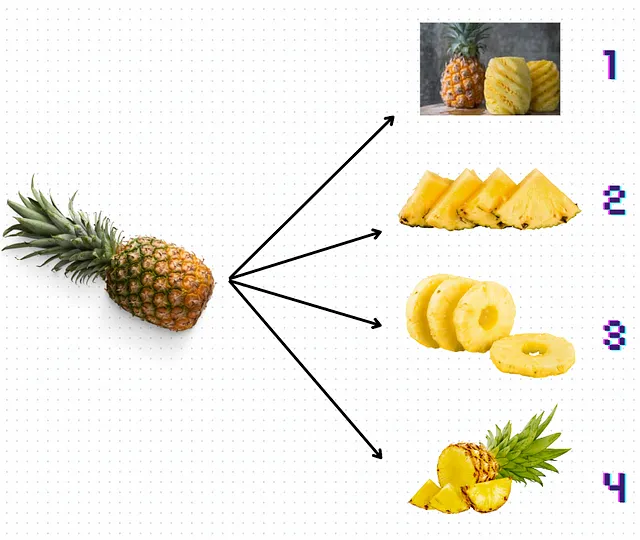
按顺序列出它们:
- 切割编号1将表示基于规则的方法,您可以根据过滤器或正则表达式“剥离”您想要的“垃圾”文本。不过,要处理整个菠萝还需要很多工作,因为它还保留了许多具有更大上下文大小的异常值。
- Langchain就像切割编号2一样。大小非常相似的块,但不保留整个所需的上下文(它是一个三角形,所以也可能是一个西瓜)。
- 切割编号3明确是KMeans。您甚至可以仅对对您有意义的部分进行分组-最多汁的部分-但是您将无法获得其核心。没有核心,块失去了所有的结构和意义。我认为这也需要很多工作…尤其是对于较大的菠萝。
- 最后,切割编号4说明了相邻句子聚类方法。块的大小可以变化,但它们通常保持上下文信息,类似于不均匀的菠萝块,仍然指示了水果的整体结构。
简而言之:在本文中,我们比较了三种文本块划分方法及其独特的优点。Langchain提供一致的块大小,但语言结构不太重要。NLTK和Spacy提供语言连贯的块,但大小差异很大。相邻序列聚类基于语义相似性进行聚类,提供内容连贯性和灵活的块大小。最终,最佳选择取决于您的具体需求,包括语言连贯性、块大小的一致性和可用的计算能力。
感谢您的阅读!
- 在Linkedin上关注我!






