利用NLP提升你的求职能力
提升求职能力的NLP应用
基于预训练的sBERT和Plotly Dash界面的语义搜索功能的网络应用程序演示 | 实时应用程序 | Git Hub
介绍
在最常见的职位平台上,搜索功能通常是基于少量输入词汇和一些过滤器(例如位置)来过滤工作。这些词汇通常表示领域或期望的职位,并且在大多数情况下,搜索系统检索的工作描述中必须出现确切的输入词汇。我们不确定最新的自然语言处理(NLP)技术在多大程度上被用于优化我们的搜索。
近年来,NLP取得了显著的突破,我们可以利用一些能够将搜索提升到另一个水平的技术。我们可以考虑使用基于一组查询句子的语义搜索,例如:
- 我们希望在下一份工作中执行的任务
- 理想的工作环境,如公司文化
- (针对技术工作)我们希望使用的技术栈
在本文中,我们将回顾sBERT(句子BERT)模型的工作原理,并展示如何应用预训练模型来改进搜索工作等日常任务。
已经构建了一个Dash应用程序,包括这些搜索功能;下面是它的外观:

目录
1. 什么是sBERT?1.1 NLP嵌入技术快速回顾1.2 Transformers概述1.3 从Transformers到sBERT1.4 从BERT到sBERT2. 生成句子嵌入2.1 在预训练模型中进行选择2.2 使用预训练模型进行语义搜索3. 使用Dash将所有内容整合在一起3.1 数据准备3.2 应用程序输入3.3 匹配机制参考文献
1. 什么是sBERT?
1.1 NLP嵌入技术快速回顾
对于任何NLP任务(如搜索),我们需要将文本表示为向量,以便进行数学运算。现在有着广泛的嵌入技术历史:
- “词袋模型”:这些传统方法使用文档中的词频或词汇共现来创建词(或文档)级别的嵌入。每个向量由二进制条目或频率条目组成(有几种计算频率的方法:tf-idf、ppmi、bm25等)。结果向量通常过于庞大和稀疏。
- “基于计数的模型”:这些模型克服了上述方法的大小/稀疏向量的限制。从词汇共现矩阵(或文档-词汇矩阵)开始,应用降维技术创建稠密且较小的向量。这些方法的一些示例是GloVe(使用增强版本的奇异值分解SVD来减小大小)、LSA(潜在语义分析)。
- “预测模型”:这些模型使用简单(1个隐藏层)的神经网络来预测一个单词。Word2Vec是一个非常著名的模型(更多细节请参见此处),它可以通过一些周围单词(使用固定窗口)来预测目标单词或反之亦然(从给定单词预测上下文)。隐藏层学到的权重可以用作单词嵌入。
- “上下文嵌入”:最近的研究集中在创建考虑上下文的单词表示。事实上,像Word2Vec这样的模型创建了每个单词的“全局”表示,存在一些明显的限制(考虑多义性、上下文相关的术语等)。上下文嵌入模型可以创建动态的单词表示,这些表示根据上下文、单词类型(名词/动词)、语法规则等而变化。这些模型基于深度神经网络。一段时间以来,不同类型的RNN(循环神经网络)(LSTM、GRU)被提出,但存在一些限制:(a)这些架构在计算上是慢的,因为它们需要按顺序进行训练;(b)当涉及到在语料库中相距很远的词语时,它们存在一些限制。所有这些限制都被Transformers克服了,这是由Google创建的一种网络架构[1],它启发了许多不同的模型的创建,如BERT、GPT等。
1.2 Transformers概述
Transformer神经网络是在机器翻译任务中提出的。它们具有编码器架构和解码器架构。由于在本文中,我们只关注使用Transformer进行文本嵌入,因此我们只会重点讨论编码器部分:
](https://miro.medium.com/v2/resize:fit:640/format:webp/1*oiwWwhHc5QoQI5kguuE21g.png)
- 输入嵌入:Transformer架构接受每个单词的输入嵌入向量,维度为512(输入嵌入是稍后将被改进的初始化)。
- 位置编码:由于Transformer同时接受所有单词嵌入作为输入(而不是像RNN一样逐个单词),它们需要一些额外的关于每个单词位置的信息。这就是为什么输入嵌入向量与位置向量相加。每个位置向量使用傅立叶级数理论构建:使用正弦和余弦函数根据单词在句子中的位置(pos)和向量的第i个维度(i)来获得唯一的向量。对于每个单词和维度,将位置分数添加到相应的嵌入中。(观看这个视频以获得图形化和更详尽的解释)。
- 自注意机制:直观地说,自注意机制允许模型为完成任务而与输入中相关的部分分配更大的权重。在计算机视觉中有明显的例子(例如目标检测),CNN(卷积神经网络)学习要应用于图像的“过滤器”,以便网络可以专注于相关的像素。这个概念也被应用到NLP中,使用Q(查询)、K(键)、V(值)矩阵。这些矩阵最初只是输入向量的副本。将Q和K矩阵相乘以构建“掩码”矩阵,即包含每对术语的注意力分数的矩阵。由于乘法,相似的对将获得更高的分数(softmax函数将这些分数限制在0到1之间)。然后,将这个注意力过滤器与V矩阵相乘,以获得每对术语的加权值。直观地说,这种方法允许将每个术语与输入句子的其他部分链接起来以完成任务(例如机器翻译)(观看这个视频以获得图形化和更详尽的解释):
![自注意机制 | 图片来源[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*21-74hrxnaZ-POCKvi7xcA.png)
- 多头注意力:上述注意力机制被多次重复。直观地说,这意味着模型从不同的角度学习任务:一个层可能使用词汇的注意力,另一个层可能使用语法的注意力等。
作为整个编码层的输出,我们得到一个包含所有嵌入向量的矩阵。这些向量存储了单词嵌入、位置编码信息和上下文信息(即被注意层优先考虑的句子中的其他单词)。
1.3 从Transformers到BERT
自Transformer论文以来,已经使用该架构的变种创建了几个模型,用于特定目的。
BERT(基于变换器的双向编码器表示)是由Google于2018年创建的[2],仅使用了变换器架构的编码器组件。这个模型的想法是创建一个多功能的预训练模型,可以生成上下文语义嵌入,然后可以传入微调步骤。简单来说:用户可以根据特定任务使用预训练的BERT模型,并添加一个微调层来完成训练(例如,根据特定的分类任务)。
与原始编码器相比,BERT模型:
- 对架构进行了一些修改:它堆叠了更多的变换器编码器(“BERT基础”版本中有12个,在“BERT大”版本中有24个);它在自注意机制中添加了更多的多头(“BERT基础”版本中有12个,在“BERT大”版本中有16个);最终的嵌入向量具有更大的大小(“BERT基础”为768,“BERT大”为1024)。
- BERT在两个无监督任务上进行训练,如下所述。
这两个任务是:
- 掩码语言模型(MLM):预测输入中被破坏的单词。在训练过程中,将输入句子中的15%的标记以三种不同的方式“掩码”(80%的时间,标记被替换为[MASK]标记;10%的时间,被替换为随机单词;10%的时间保持不变)。编码器被训练用于预测这些标记。
- 下一个句子预测(NSP):BERT被训练用于学习两个句子之间的关系,以提高问题回答或推理性能。当作为输入给定一对句子A,B(由特殊的[SEP]标记分隔),50%的时间,B是紧随A之后的自然句子,而另外50%的时间,B是一个随机句子。编码器被训练用于预测将A与B相关联的“isNext”标签。
1.4 从BERT到sBERT
2019年创建了一个sBERT(句子BERT)模型[3],以改进BERT模型,用于特定任务,如句子相似性或句子聚类。sBERT论文强调了原始BERT模型中以下“弱”点:
- BERT是在NSP上进行训练的,但这并不能准确预测两个句子A和B的相似程度。
- BERT需要两个输入句子才能进行比较,在查找语料库中最相似的句子时,这会降低计算速度。
- BERT无法输出单个句子嵌入。(尝试了几种策略来从BERT中提取句子嵌入,但没有找到一致的方法)。
sBERT模型采用以下架构创建:
![sBERT architecture | Picture from [3]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*1It9uBtVSHJtsrT6nFG7IQ.png)
- 使用BERT模型为每个句子生成嵌入。正如讨论的那样,由于从BERT中提取句子嵌入的方法并不唯一,sBERT的默认方法是对所有Transformer输出进行平均计算。然后,添加一个“池化”层以计算固定大小的句子嵌入(与句子长度无关)。
- sBERT使用孪生网络(两个相同架构的副本),在不同的任务上进行训练(例如句子分类和回归 – 图片是指这第二种情况,即预测句子相似性)。根据任务,体系结构顶层的目标函数可以进行修改。
借助预训练的sBERT模型,我们可以以计算效率高的方式创建固定大小的复杂句子嵌入!让我们看一个示例。
2. 生成句子嵌入
2.1 在预训练模型中进行选择
自sBERT发布以来,许多预训练模型已经构建并在几个任务上进行了比较。
为了选择一个模型,首先让我们关注那些专为我们的任务设计的模型。在本文中,我们希望找到一个用于语义搜索的模型,可以分为两种类型:
- 对称搜索:当查询和结果的大小和内容大致相同时,我们进行对称搜索。
- 非对称搜索:当查询很短,而期望的结果是一个较长的回答查询的句子时,我们进行非对称搜索。
我们将执行对称语义搜索:以下是在此任务上预训练的性能最佳模型的列表。在文章发布时,性能最佳的模型是all-mpnet-base-v2 [4],它:
- 在预测句子相似性时使用超过10亿个句子进行了预训练
- 允许最大384个标记的输入句子(较长的输入会自动截断)
- 输出大小为768的嵌入
2.2 使用预训练模型进行语义搜索
让我们来看看上述模型的效果。
假设我们从两个职位描述中提取了以下两个句子。其中一个是寻找具有流失模型经验的候选人,另一个是寻找具有自然语言处理经验的候选人:
一个寻找与他/她在客户分析方面经验相符的工作的用户输入以下查询:
请注意,查询和两个句子之间没有词汇重叠。传统模型在不进行语义和上下文信息编码的情况下无法将查询与两个句子之一关联起来。
让我们从Huggingface下载sBERT模型并对这三个句子进行编码:
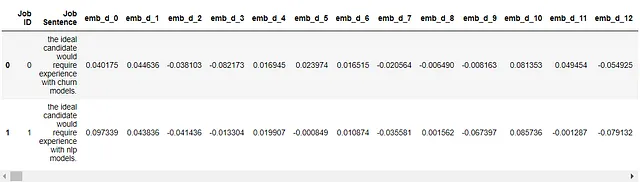
或者,我们也可以使用Huggingface API请求嵌入:
现在我们可以计算查询与每个工作句子之间的余弦相似度:

然后绘制嵌入(我们将使用tSNE将嵌入降低到3维):
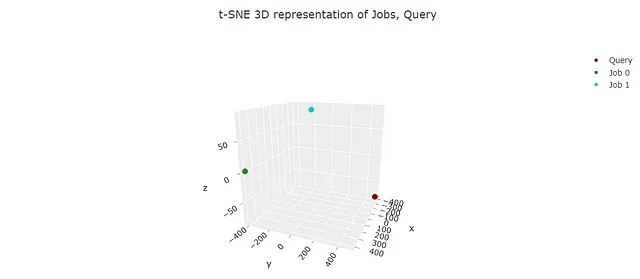
我们可以看到“工作 0”成功被选择为与查询更相似的工作。该模型“知道”流失模型与客户满意度和保留有更多关联,而不是nlp !!!
3. 使用Dash将所有内容整合在一起
我们现在可以构建一个使用Dash模拟搜索系统的Web应用程序。这个应用程序已经使用Python Anywhere部署,可以在这里找到。
3.1 数据准备
在开始搜索之前,我们应该准备数据,对其进行清洗并为每个句子生成嵌入:
- 我们假设一些工作描述数据可用。为了获取这些数据,我们可以抓取工作平台(这是一个示例)。
- 需要使用经典的NLP技术对数据进行预处理,并将其分词为句子(这是该项目使用的代码)。
- 在我设计的应用程序中,使用了两个数据帧。一个(“Job_Info”)包含所有工作信息(例如:工作ID、地点、雇主、完整描述),另一个(“df_embeddings”)包含句子,每行一个。
- 使用句子数据帧,我们使用预训练的sBERT模型的副本生成句子嵌入(句子嵌入直接保存在“df_embeddings”中)。
3.2 应用程序输入
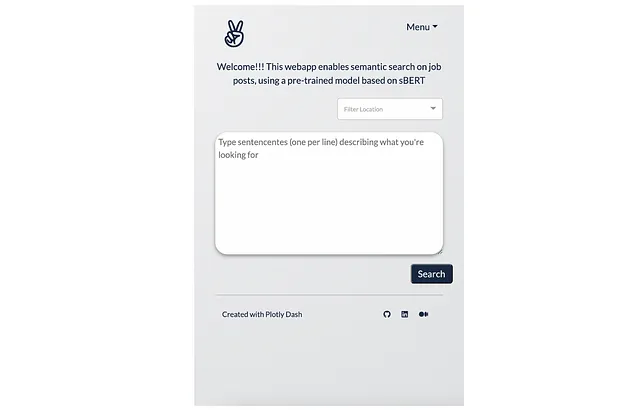
该应用程序需要用户输入才能工作。用户需要:
- 编写一些查询句子。该应用程序最多可以处理10个查询句子。
- (可选)在可用地点中进行选择。
一旦点击“搜索”按钮,应用程序将使用Huggingface API对每个查询句子进行嵌入(上面显示了使用的模型和代码)。(如果您想在本地设置此应用程序的副本,请记得在“.assets/nlp_functions.py/embed_api”中输入您自己的API令牌)。
以下是输入界面的样子:
3.3 匹配机制
为了对工作进行排名,该应用程序计算每个工作句子与每个查询句子之间的余弦相似度。
将保存每个工作和查询句子的最大相似度。因此,假设我们有4个输入查询句子,每个工作将有4个相似度分数。
使用这些相似度分数,每个工作从1(最高相似度)到n进行排名。
最后,使用加权平均法将不同的排名组合在一起,生成每个工作的单个最终排名分数。以下是原因和方法:
- 假设我们有两个输入查询句子。在所有工作句子中,查询-1的最大相似度为0.2,而查询-2的最大相似度为0.8。
- 如果我们选择一个工作(比较来自其所有句子的余弦相似度),在查询-1上排名第一但在查询-2上排名第十,我们可能希望优先考虑在查询-1中得分较低但在查询-2中得分较高的其他工作。
- 因此,使用每个查询中获得的最大相似度计算每个工作排名的加权平均值。
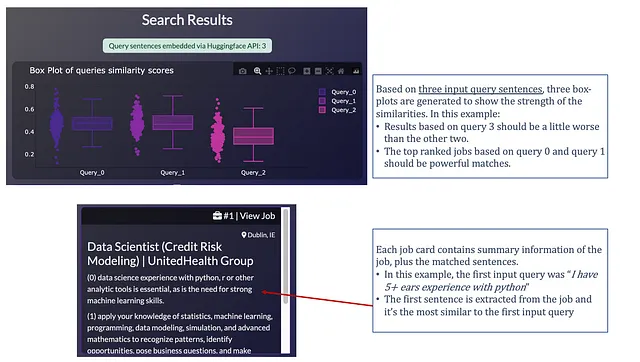
最后,该应用程序生成两个输出:
- 一个箱线图显示工作与查询句子之间相似度得分的“强度”。每个查询句子生成一个箱线图,其中每个工作的最大相似度得分作为个别数据点。通过这个图表,我们可以立即看出我们的查询句子是否产生了“强匹配”。
- 排序结果:为每个工作生成一个dbc.Card,从最相似到最不相似的工作。每个工作卡包含从完整工作描述中提取的用于对工作进行排名的句子。
以下是输出界面的样式:
希望这对您有用,并希望您可以在自己的工作搜索中应用这个方法。感谢您的阅读!!!
参考资料
- [1] “Attention is all you need”(2017)— Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser和Illia Polosukhin。带有实现注释、代码审查和示例的注释版本。
- [2] “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”(2018)— Jacob Devlin, Ming-Wei Chang, Kenton Lee和Kristina Toutanova
- [3] “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks”(2019)— Nils Reimers和Iryna Gurevych
- [4] Huggingface的“all-mpnet-base-v2”模型






