在非结构化数据中找到数据片段
寻找非结构化数据片段
数据切片方法简介,包括CIFAR-100数据集的实际示例。
tl;dr:
数据切片是数据的语义有意义的子集,模型在其中执行异常。当处理非结构化数据问题(例如图像、文本)时,找到这些切片是每个数据科学家工作的重要部分。在实践中,这个任务涉及很多个人经验和手动工作。在本文中,我们介绍了一些方法和工具,以使找到数据切片更加系统化和高效。我们讨论了当前的挑战,并演示了一些基于开源工具的实际示例工作流程。
有一个基于CIFAR100数据集的交互式演示可用。
介绍
调试、测试和监控人工智能(AI)系统很困难。软件2.0开发过程中的大部分工作都花在了筛选高质量数据集上。
开发稳健的机器学习(ML)算法的重要策略之一是识别所谓的数据切片。数据切片是模型执行异常的语义有意义的子集。识别和跟踪这些数据片段是每个以数据为中心的AI开发流程的核心。它也是在医疗保健和自动驾驶辅助系统等领域部署安全AI解决方案的核心方面。
传统上,找到数据切片一直是数据科学家工作的重要部分。在实践中,找到数据切片主要依赖于数据科学家的个人经验和领域知识。在以数据为中心的AI运动中,有很多当前的工作和工具试图使这个过程更加系统化。
在本文中,我们概述了非结构化数据上的数据切片查找的当前状态。我们特别演示了一些基于开源工具的实际示例工作流程。
什么是切片查找?
数据科学家经常使用简单的手动切片查找技术。最著名的例子可能是混淆矩阵,用于分类问题的调试方法。在实践中,切片查找过程依赖于预先计算的启发式方法、数据科学家的个人经验和大量的交互式数据探索。
经典的数据切片可以通过对表格特征或元数据的谓词进行联结来描述。在人员数据集中,这可能是某个年龄范围内的男性身高超过1.85米的人。在发动机工况监测数据集中,数据切片可能由特定转速、运行小时和扭矩范围内的数据点组成。
对于非结构化数据,语义数据切片的定义可以更加隐含:它可以是人类可理解的描述,例如“在山区交通繁忙的弯曲道路上的轻雨驾驶场景”。
在非结构化数据上识别数据切片可以通过两种不同的方式实现:
- 可以使用经典信号处理算法(例如暗图像、低信噪比音频)或预训练的深度神经网络进行自动标记,从非结构化数据中提取元数据。然后可以在这些元数据上进行切片查找。
- 可以使用嵌入空间中的潜在表示来对数据聚类。然后可以检查这些聚类以直接识别相关的数据切片。
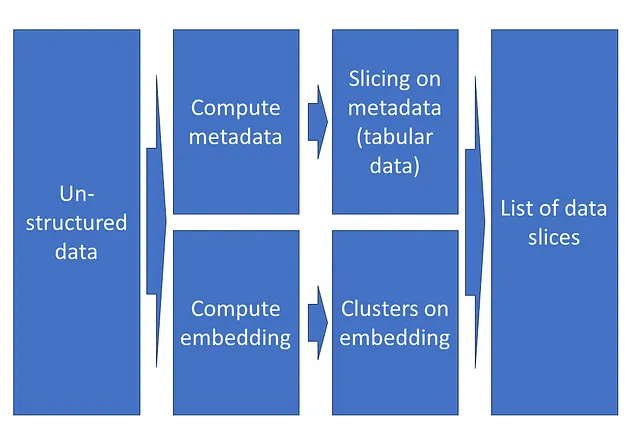
自动化的切片查找技术始终试图在支持切片(应该是大的)和模型性能异常的严重程度(也应该是大的)之间取得平衡。
在表格数据上的切片查找方法与决策树有很多相似之处:在ML模型分析的上下文中,这两种技术都可以用来制定描述模型错误存在的规则。然而,有一个重要的区别:切片查找问题允许重叠的切片。这使得问题在计算上更加困难,因为更难剪枝搜索空间。
为什么数据切片查找很重要?
特别是在过去的十年中,机器学习社区从基准数据集中获得了巨大的益处:从ImageNet开始,这些数据集和竞赛对于解决结构化数据问题的深度学习算法是一个重要的成功因素。在这种情况下,一个新算法的质量通常是根据一些数量化指标,如F1分数或平均精度来评判的。
随着越来越多的机器学习模型部署到生产环境中,真实世界的数据集与基准数据集有很大的不同:真实数据通常非常嘈杂和不平衡,但也富含元数据信息。对于某些用例而言,清理和注释这些数据集可能代价过高。
许多团队发现,迭代训练数据集并监控生产中的漂移是构建和维护安全的人工智能系统的必要步骤。
找到数据切片是这个迭代过程的核心部分。只有知道模型在哪些地方失败,才能改进系统性能:通过收集更多数据,纠正错误标签,选择最佳特征,或者简单地限制系统的操作领域。
为什么数据切片查找如此困难?
数据切片查找的一个关键方面是其计算复杂性。我们可以通过一个小例子来说明:考虑具有一位有效编码的n个二进制特征(例如可以通过分箱或重新编码获得)。那么所有可能特征组合的搜索空间是O(2^n)。这种指数级的复杂性意味着通常使用启发式方法进行剪枝。因此,自动化的数据切片查找不仅需要很长时间(取决于特征数量),而且输出结果不会是一个最优的稳定解,而是一些启发式方法。
在人工智能开发过程中,模型性能不佳通常源于不同的根本原因。由于机器学习模型的随机性质,这很容易导致需要手动检查和验证的虚假发现。因此,即使一个数据切片查找技术可以产生理论上的最优结果,其结果也必须经过手动检查和验证。为跨职能团队提供高效处理这一问题的工具是许多机器学习团队面临的瓶颈。
我们已经指出,通常希望找到具有大量支持的切片,但与数据集基线相比,在模型性能上存在明显差距。不同数据切片之间的关系通常具有层次性质。在自动化的数据切片查找过程和交互式审查阶段处理这些层次关系非常具有挑战性。
自动化的数据切片查找方法在元数据丰富的问题上效果最好。这在现实世界的问题中经常发生。相比之下,基准数据集在元数据方面总是相对稀疏的。造成这种情况的两个主要原因是数据保护和匿名化要求。由于缺乏合适的示例数据集,开发和展示有效的数据切片查找工作流程非常困难。
我们(不幸地)必须在下面的示例部分中应对这个挑战。
实践操作:在CIFAR-100上找到数据切片
CIFAR-100数据集是一个已经建立的计算机视觉基准。我们在本教程中使用它,因为其小规模使得处理起来容易且计算需求低。其结果也很容易理解,不需要特殊领域知识。
不幸的是,CIFAR-100已经完美平衡,高度策划并且缺乏有意义的元数据。因此,在这个部分中生成的数据切片查找工作流程的结果并不像在实际环境中那么有意义。然而,所呈现的工作流程应足以了解如何快速在您的真实数据上使用它们。
在准备步骤中,我们使用Cleanvision库计算图像元数据。有关此丰富的更多信息可以在我们的数据中心AI指南中找到。
我们还为数据切片分析定义了一些重要的变量:要分析的特征以及标签和预测列的名称:
大多数切片技术只适用于分箱特征。由于SliceLine和WisePizza库本身不提供分箱功能,我们将其作为预处理步骤执行:
SliceLine
SliceLine算法由Sagadeeva等人于2021年提出。它旨在处理包含许多特征的大型表格数据集。它利用基于稀疏线性代数技术的新型剪枝技术,并能够在单台计算机上快速找到数据切片。
在本教程中,我们使用了DataDome团队的SliceLine实现。它运行非常稳定,但目前仅支持Python版本<=3.9。
SliceLine算法的大多数参数都非常直观:切片的最小支持度(min_sup),定义切片的谓词的最大数量(max_l)以及要返回的切片的最大数量(k)。参数alpha为切片错误的重要性分配了一个权重,essential参数控制了切片的大小和错误减少之间的权衡。
我们调用SliceLine库来获取最有趣的20个切片:
为了交互式地探索这些切片,我们丰富了每个数据切片的描述:
我们启动Spotlight来交互式地探索数据切片。您可以在Huggingface空间中直接体验结果。
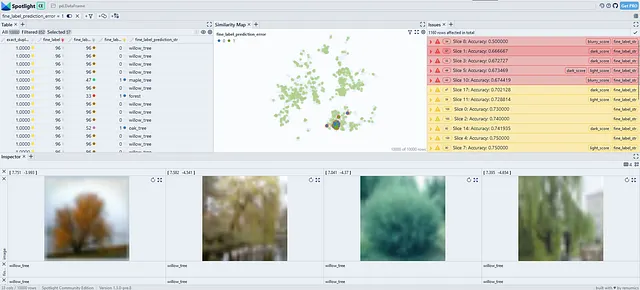
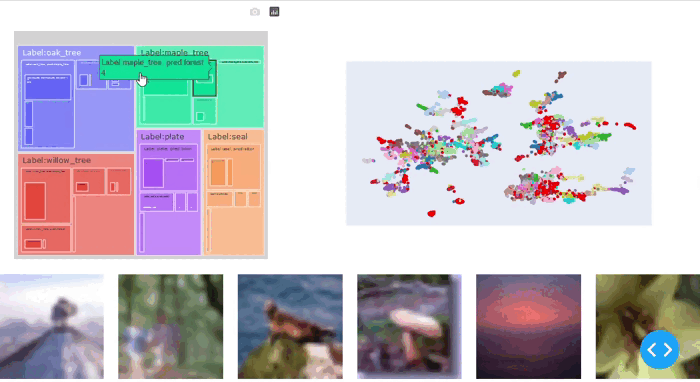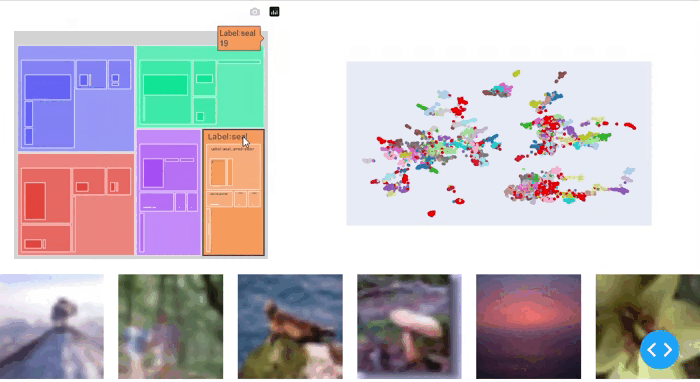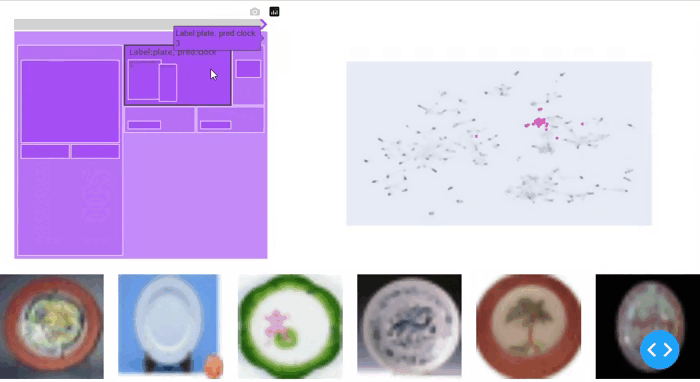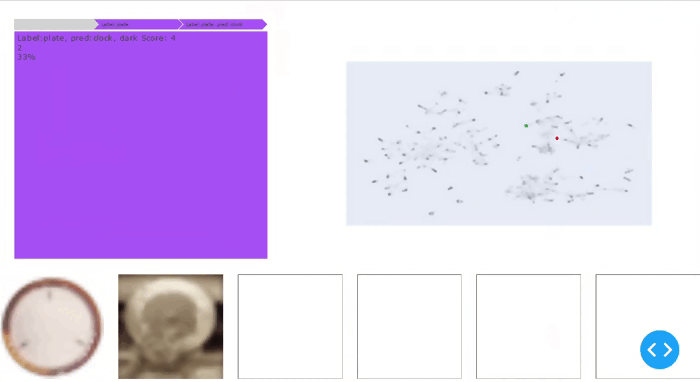
我们可以看到,SliceLine算法在CIFAR-100数据集中找到了一些有意义的数据切片。枫树、柳树和橡树这些类别似乎存在问题。我们还发现,这些类别中具有较高暗分数的数据点尤其具有挑战性。经过仔细检查,我们发现这是因为具有明亮背景的树对模型来说很困难。
智能披萨
智能披萨是Wise团队最新开发的产品,旨在找到并可视化表格数据中有趣的数据切片。其核心思想是使用Lasso回归为每个切片找到重要系数。关于智能披萨的更多信息可以在博客文章中找到。
值得注意的是,智能披萨并不是作为ML调试工具开发的。相反,它主要用于支持EDA期间的段分析。因此,可以手动定义段候选项并为它们分配权重。在我们的实验中,我们直接在数据集上运行智能披萨,并将每个数据点的权重设置为1:
为了探索我们的非结构化数据集中的问题,我们以与Sliceline示例相同的方式提取问题。
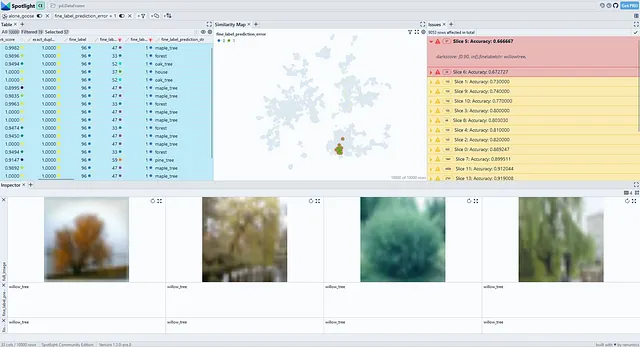
从图4中可以看出,在简单的CIFAR-100基准数据集上,智能披萨找到了相关的段落:它还将具有较高暗分数的柳树类别列为顶级切片。然而,下面的结果仅限于不同的类别,且不像SliceLine的输出那样精细。其中一个原因是智能披萨算法没有直接提供切片支持度和准确性下降之间的加权机制。
Sliceguard
Sliceguard库使用层次聚类来确定可能的数据切片。然后,使用公平学习的方法对这些聚类进行排序,并通过可解释的AI技术来挖掘谓词。有关Sliceguard的更多信息可以在博客文章中找到。
我们构建Sliceguard的主要原因是它不仅适用于表格数据,还直接适用于嵌入数据。该库提供了许多内置功能,用于预处理(例如分箱)和后处理。
我们只需要几行代码就可以在CIFAR-100上运行Sliceguard:
Sliceguard使用Spotlight提供对识别的数据切片的交互式可视化:
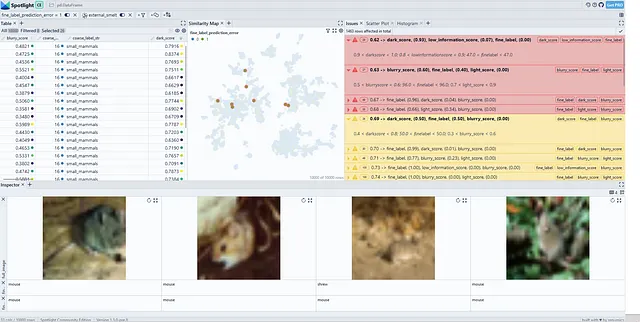
issue_df, issues = sg.report(spotlight_dtype={"image": Image})Sliceguard可以在CIFAR-100数据集上发现精细的数据切片(图5)。除了之前在树类别中发现的数据切片外,我们还发现了其他问题(例如在鼠类中)。
结论
我们介绍了三个用于挖掘数据切片的开源工具。即使在简单的CIFAR-100基准测试上,它们也可以快速发现关键的数据片段。识别这些数据切片是了解模型失败模式并改进训练数据集的重要步骤。
SliceLine工具适用于表格数据,并识别由多个谓词描述的数据切片。Sliceguard不能返回数学上保证的最佳谓词组合,但它可以直接处理嵌入向量。此外,它只需几行代码即可在非结构化数据集上运行。
在实践中,SliceLine和Sliceguard都对于识别数据切片非常有帮助。然而,这两个工具不能用于完全自动化的切片分析。相反,它们提供了强大的启发式方法,可以与交互式探索相结合使用。如果使用得当,这种方法将成为跨学科数据团队构建可靠的机器学习系统的重要工具。
您是否有使用过所介绍的数据切片工具的经验,或者能否推荐其他开源库?我很愿意在评论中听到您的意见。





