你应该如何验证机器学习模型
如何验证机器学习模型
学习如何在你的机器学习解决方案中建立信任

大型语言模型已经以一种重大方式改变了数据科学行业。其中最大的优势之一是,对于大多数应用程序来说,它们可以直接使用-我们不需要自己训练它们。这要求我们重新审视整个机器学习过程中的一些常见假设-许多从业者认为验证是“训练的一部分”,这意味着它不再需要。我们希望读者对验证被认为已过时的建议感到不安-它绝对不是。
在这里,我们将探讨模型验证和测试的概念。如果您认为自己在机器学习的基础知识上非常熟练,您可以跳过这篇文章。否则,请准备好-我们有一些离奇的场景,让您暂时放下怀疑。
本文是Patryk Miziuła博士和Jan Kanty Milczek的合作作品。
在荒岛上学习
想象一下,您想教某人识别推特上的语言。所以你带他去了一个荒岛,给了他100条来自10种语言的推特,告诉他每条推特所使用的语言,然后让他独自待上几天。之后,你回到岛上检查他是否确实学会了识别语言。但你如何检查呢?
- 意大利的一项新的人工智能研究介绍了一种基于扩散的生成模型,能够同时进行音乐合成和音源分离
- 使用Hugging Face构建一个使用LLMs的文本摘要工具
- 微软和哥伦比亚大学的研究人员提出了LLM-AUGMENTER:一种人工智能系统,它通过一组即插即用的模块增强黑盒LLM
你可能首先想到的是问他得到的推特所使用的语言。所以你用这种方式对他进行挑战,而他对这100条推特的语言都回答正确。这是否真的意味着他能够总体上识别语言?可能,但也可能他只是记住了这100条推特!而你无法知道哪种情况是真实的!
在这里,您没有检查您想要检查的内容。基于这样的检查,您根本无法知道在生死攸关的情况下(涉及荒岛时常有发生)是否可以依赖他的推特语言识别能力。
相反,我们应该怎么做?如何确保他学到了,而不仅仅是记忆了?给他另外50条推特,让他告诉你它们所使用的语言!如果他做对了,那么他确实能够识别语言。但是如果他完全失败,你就知道他只是死记硬背了前100条推特-而这不是整个事情的目的。
但这一切与机器学习模型有什么关系呢?
上面的故事比喻地描述了机器学习模型如何学习以及我们如何检查它们的质量:
- 故事中的人代表一个机器学习模型。要将人与世界断开,您需要将他带到一个荒岛上。对于机器学习模型来说,这更容易-它只是一个计算机程序,因此它本质上不理解世界的概念。
- 识别推特语言是一个分类任务,有10个可能的类别,也就是我们选择的10种语言。
- 用于学习的前100条推特被称为训练集。附上的正确语言被称为标签。
- 其他50条仅用于检查人/模型的推特被称为测试集。请注意,我们知道它的标签,但人/模型不知道。
下图显示了如何正确训练和测试模型:
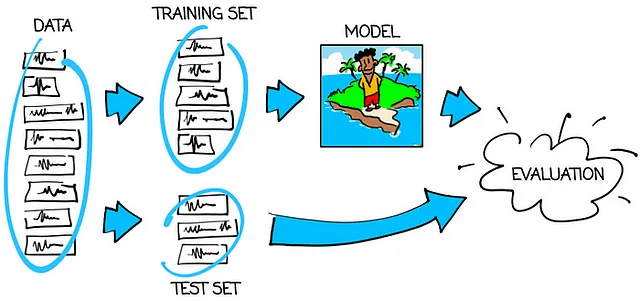
因此,主要规则是:
在训练模型时使用与其不同的数据来测试机器学习模型。
如果模型在训练集上表现良好,但在测试集上表现不佳,我们称该模型过拟合。 “过拟合” 意味着模型把训练数据记住了。这绝对不是我们想要的结果。我们的目标是拥有一个训练好的模型,适用于训练集和测试集。只有这种模型才是可信的。只有这样,我们才能相信它在最终应用中的表现将与在测试集上一样出色。
现在让我们再进一步。
1000个人在1000个荒岛上
想象一下,你真的很想教一个人识别 Twitter 上的推文语言。于是你找到了1000个候选人,把每个人带到不同的荒岛上,给每个人相同的100个推文,涉及10种语言,告诉每个人每个推文是哪种语言,并把他们独自留在那里几天。之后,你用相同的50个不同的推文检查每个候选人。
你会选择哪个候选人?当然是在这50个推文中表现最好的那个。但他到底有多好呢?我们真的能相信他在最终应用中的表现会和在这50个推文上一样吗?
答案是否定的!为什么呢?简单来说,如果每个候选人都知道一些答案并猜测一些其他答案,那么你会选择那个得到最多正确答案的人,而不是那个知道最多的人。他确实是最好的候选人,但他的结果被“幸运猜测”所夸大。这很可能是他被选择的主要原因。
为了以数字形式展示这种现象,假设47个推文对所有候选人来说都很容易,但剩下的3个推文对所有竞争者来说太难了,以至于他们都是盲目猜测语言。概率论告诉我们,至少有一个人(可能是多个人)能猜对这3个困难的推文的概率超过63%(给数学迷的信息:几乎是1-1/e)。所以你可能会选择一个得分完美的人,但实际上他对你的需求并不完美。
也许在我们的例子中,50个推文中的3个听起来不是令人惊讶的,但在许多实际情况下,这种差异往往更加明显。
那么我们如何检查获胜者实际上有多好呢?是的,我们必须再获取一组50个推文,并再次检查他!只有这样,我们才能获得一个可信的分数。这种准确性水平是我们对最终应用的期望。
让我们回到机器学习术语
从命名的角度来看:
- 第一组100个推文现在仍然是训练集,因为我们用它来训练模型。
- 但是第二组50个推文的目的已经改变。这次它被用来比较不同的模型。这样的一组被称为验证集。
- 我们已经了解到,在验证集上检查的最佳模型的结果是人为提升的。这就是为什么我们需要另外一组50个推文来扮演测试集的角色,并给我们关于最佳模型质量的可靠信息。
您可以在下面的图像中找到使用训练集、验证集和测试集的流程:
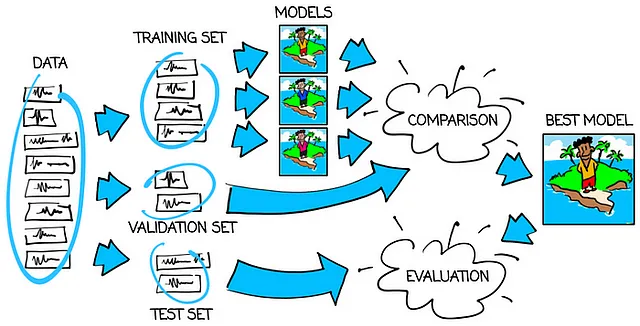
好的,为什么我们要使用恰好100、50和50个推文的集合?
这里有两个关于这些数字的一般想法:
尽可能多地将数据放入训练集。
我们拥有的训练数据越多,模型的视野就越广,训练而不是过拟合的机会就越大。唯一的限制应该是数据的可用性和处理数据的成本。
尽量少放数据到验证集和测试集中,但确保它们足够大。
为什么呢?因为你不想浪费太多数据用于除了训练之外的其他用途。但另一方面,你可能会觉得仅基于一条推文评估模型会有风险。因此,你需要一组足够大的推文,以免在出现少量非常奇怪的推文时担心分数混乱。
那么如何将这两个准则转化为确切的数值呢?如果你有200条推文可用,那么100/50/50的分配似乎很好,因为它遵守了上述两个规则。但如果你有100万条推文,那么你可以轻松地选择800,000/100,000/100,000甚至900,000/50,000/50,000的分配。也许你在某个地方看到了一些百分比的线索,比如60%/20%/20%之类的。嗯,它们只是对上述两个主要规则的过度简化,因此最好还是遵守原始准则。
好的,但如何选择哪些推文将进入训练/验证/测试集?
我们相信你现在清楚了这个主要规则:
使用三个不同的数据集来训练、验证和测试模型。
那么如果违反了这个规则呢?如果同样的或几乎相同的数据,无论是意外还是注意力不集中,进入了三个数据集中的多个?这就是我们所说的数据泄露。验证和测试集就不再可靠。我们无法确定模型是经过训练还是过拟合。我们简单地无法信任该模型。不好。
也许你认为这些问题与我们的荒岛故事无关。我们只需选择100条推文用于训练,另外50条用于验证,再另外50条用于测试,就行了。不幸的是,事情并不那么简单。我们必须非常小心。让我们通过一些例子来说明。
例子1:许多随机推文
假设你从Twitter上爬取了1,000,000条完全随机的推文。不同的作者、时间、主题、位置、反应数量等等。完全随机的。而且它们是用10种语言编写的,你想用它们来教模型识别语言。那么你就不用担心任何问题,你只需随机选择900,000条推文作为训练集,50,000条作为验证集,另外50,000条作为测试集。这被称为随机分割。
为什么要随机选择,而不是将前面的900,000条推文放入训练集,接下来的50,000条放入验证集,最后的50,000条放入测试集?因为推文最初可能会以一种对我们没有帮助的方式排序,比如按字母顺序或按字符数量排序。我们对只将以“Z”开头或最长的推文放入测试集没有兴趣,对吗?所以最好还是随机抽取它们。
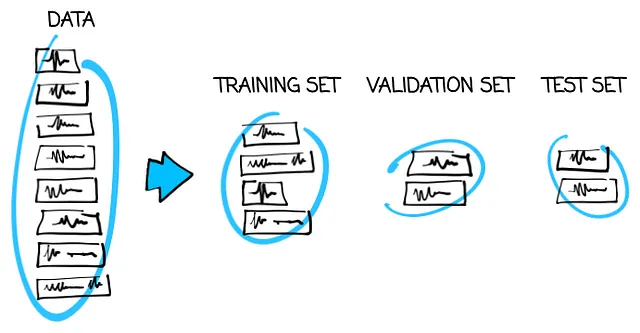
假设推文完全是随机的这个假设是很强的。如果不是,请三思而后行。在接下来的例子中,你将看到如果不是这样会发生什么。
例子2:不那么多的随机推文
如果我们只有200条完全随机的推文,而且它们使用了10种语言,那么我们仍然可以随机分割它们。但是这样会带来一个新的风险。假设某种语言占主导地位,有128条推文,其他9种语言每种有8条推文。根据概率,所有语言都不会都进入50条元素的测试集的机会超过61%(数学迷的信息:使用容斥原理)。但我们肯定想在所有10种语言上测试模型,所以我们肯定需要将它们全部放入测试集中。我们该怎么办呢?
我们可以按类别逐个抽取推文。所以先取出占主导地位的128条推文,其中64条用于训练集,32条用于验证集,还有32条用于测试集。然后对所有其他类别也进行相同的操作——分别为每个类别抽取4、2和2条推文用于训练、验证和测试。这样,你将形成所需大小的三个数据集,每个数据集中的所有类别比例相同。这种策略被称为分层随机分割。
分层随机拆分似乎比普通随机拆分更好/更安全,那为什么我们在示例1中没有使用它呢?因为我们不需要!常常令人费解的是,如果在100万条推文中有5%的推文是英文,并且我们随机选取了50,000条推文而不考虑语言,那么选取的推文中也将有5%是英文的。这就是概率的工作原理。但是,概率需要足够大的数字才能正常工作,所以如果你有100万条推文,那你不用担心,但如果只有200条,就要小心了。
示例3:来自多个机构的推文
现在假设我们有10万条推文,但它们只来自20个机构(比如新闻电视台、一家大型足球俱乐部等),每个机构都有10个不同语言的Twitter账号。再次,我们的目标是总体上识别推文的语言。我们能简单地使用随机拆分吗?
你说得对-如果可以的话,我们就不会问了。但为什么不行呢?为了理解这个问题,首先让我们考虑一个更简单的情况:如果我们只在一个机构的推文上训练、验证和测试模型,我们能在任何其他机构的推文上使用这个模型吗?我们不知道!也许这个模型会过度拟合该机构独特的推文风格,我们无法检查它!
让我们回到我们的案例。问题是一样的。总共有20个机构,数量较小。因此,如果我们使用来自同样的20个机构的数据来训练、比较和评分模型,那么模型可能会过度拟合这20个机构的独特风格,并在任何其他作者身上失败。而且再次强调,没有办法检查它。这不好。
那么该怎么办呢?让我们再遵循一个主要规则:
验证集和测试集应尽可能忠实地模拟模型将应用的真实情况。
现在情况更清楚了。由于我们预计最终应用程序中会有不同的作者,而我们的数据中却没有这些作者,所以验证集和测试集中的作者也应该与训练集中的作者不同!而实现这一点的方法是按机构拆分数据!例如,我们从训练集中随机选取10个机构,再从验证集中选取另外5个机构,剩下的5个机构放入测试集,问题就解决了。

请注意,任何对机构进行较松散的拆分(例如将4个机构的全部数据和剩余16个机构的一小部分数据放入测试集)都会造成数据泄露,这是不好的,因此在分离机构时我们必须严格要求。
一个令人沮丧的最后的说明:对于正确的按机构进行验证拆分,我们可以对来自不同机构的推文信任我们的解决方案。但私人账户的推文可能会有所不同,因此我们无法确定我们拥有的模型能否在这些推文上表现良好。根据我们拥有的数据,我们没有任何工具来检查它…
示例4:相同的推文,不同的目标
示例3很难,但如果你仔细阅读过,那么这个例子会相对容易理解。因此,假设我们拥有与示例3中完全相同的数据,但现在目标不同了。这次我们想要识别我们数据中同样来自这20个机构的其他推文的语言。现在随机拆分还可以吗?
答案是:可以。随机拆分完全符合上述最后一个主要规则,因为我们最终只关心我们数据中的这些机构。
示例3和示例4向我们展示了数据拆分的方式不仅取决于我们拥有的数据,还取决于数据和任务。无论何时设计训练/验证/测试拆分,请牢记这一点。
示例5:仍然是相同的推文,但另一个目标
在上一个例子中,让我们保留我们拥有的数据,但现在让我们尝试教会模型根据未来的推文预测机构。所以我们再次面临一个分类任务,但这次有20个类别,因为我们获取了来自20个机构的推文。对于这种情况怎么样呢?我们可以随机分割我们的数据吗?
和之前一样,让我们先思考一个更简单的情况。假设我们只有两个机构——一个电视新闻台和一个大型足球俱乐部。他们都喜欢从一个热门话题跳到另一个热门话题。三天关于特朗普或梅西,然后三天关于拜登和罗纳尔多,依此类推。显然,在他们的推文中,我们可以找到每隔几天就会变化的关键词。那么一个月后,我们会看到什么关键词呢?哪个政治家、恶棍、足球球员或足球教练将会是“热门”呢?可能是现在完全不知名的人。所以,如果你想学习识别机构,你不应该专注于临时的关键词,而是要试图抓住总体风格。
好的,让我们回到我们的20个机构上。上述观察仍然有效:推文的主题随着时间变化,所以我们希望我们的解决方案适用于未来的推文,我们不应该专注于短暂的关键词。但是机器学习模型很懒。如果它找到了一个简单的方法来完成任务,它就不会再做更多的努力。而坚持关键词就是这样一个简单的方法。那么我们如何检查模型是否正确学习了,还是只是记住了临时的关键词呢?
我们非常确定您意识到,如果您使用随机分割,您应该期望在所有三个集合中都能看到每周英雄的推文。因此,这样一来,您会在训练集、验证集和测试集中得到相同的关键词。这不是我们想要的。我们需要更聪明地进行分割。但是该如何做呢?
当我们回到最后的主要规则时,问题变得简单。我们希望在未来使用我们的解决方案,所以验证集和测试集应该是相对于训练集的未来!我们应该按时间划分数据。因此,如果我们有,假设,12个月的数据——从2022年7月到2023年6月——那么将2022年7月到2023年4月放入测试集,2023年5月放入验证集,2023年6月放入测试集应该就可以了。

也许您担心通过按时间划分,我们不能在所有季节中检查模型的质量。你是对的,这是一个问题。但这个问题比我们随机划分时遇到的问题要小。您还可以考虑例如以下划分:每个月的1日至20日分配给训练集,20日至25日分配给验证集,25日至月底分配给测试集。无论如何,选择验证策略是在潜在数据泄漏之间进行权衡。只要您理解并有意识地选择最安全的选项,您就做得很好。
总结
我们将故事设定在一个荒岛上,并尽力避免任何和所有复杂性——将模型验证和测试的问题与所有可能的现实考虑隔离开来。即便如此,我们仍然遇到了一个又一个陷阱。幸运的是,避免这些陷阱的规则很容易学习。但是,要精通它们却很困难。您并不总是能立即注意到数据泄漏。您也不总是能够完全预防它。然而,仔细考虑您验证方案的可信度肯定会带来更好的模型。即使有新的模型被发明出来并发布了新的框架,这一点仍然是相关的。
此外,我们在荒岛上有1000名被困的人。一个好的模型可能正是我们及时救援他们所需要的。






