使用OpenAI开发定制的聊天机器人
使用OpenAI定制聊天机器人
介绍
聊天机器人通过提供自动化支持和个性化体验,彻底改变了企业与客户之间的连接方式。人工智能(AI)的最新发展提升了聊天机器人功能的标准。本详细的书籍提供了使用领先的人工智能平台OpenAI创建自定义聊天机器人的详细指导。
本文是Data Science Blogathon的一部分。
什么是聊天机器人?
聊天机器人是模仿人类对话的计算机程序。它们使用自然语言处理(NLP)技术理解用户的话语,并以相关和有帮助的方式进行回答。

由于可用的大规模数据集和优秀的机器学习算法,聊天机器人在近年来变得越来越智能。这些能力使聊天机器人能够更好地理解用户意图,并提供更真实的回复。
聊天机器人现在如何被使用的一些具体实例:
- 客户服务中的聊天机器人可以回答常见问题,并在全天候为消费者提供帮助。
- 营销中的聊天机器人可以帮助企业筛选潜在客户、生成潜在客户,并回答有关产品或服务的问题。
- 教育中的聊天机器人可以提供个性化辅导,并允许学生按照自己的速度学习。
- 医疗保健中的聊天机器人可以提供有关健康问题的信息,回答药品问题,并将患者与医生或其他医疗保健专业人员联系起来。
OpenAI简介
OpenAI是人工智能研究和开发的先驱。它在创建出色的语言模型方面处于领先地位,这些模型在解释和生成自然语言方面表现出色。

OpenAI提供了诸如GPT-4、GPT-3、Text-davinci等复杂的语言模型,广泛用于聊天机器人构建等自然语言处理活动。
使用聊天机器人的优势
在深入了解聊天机器人的代码和实现之前,让我们先了解一些使用聊天机器人的好处:
- 全天候可用:聊天机器人可以提供用户全天候的帮助,摆脱了人工客服代表的限制,使企业能够随时满足客户的需求。
- 改善客户服务:聊天机器人可以通过提供准确和快速的答案,及时回应常见问题,从而改善客户服务的整体质量。
- 节省成本:通过自动化客户支持任务并减少大量支持人员的需求,企业可以节省大量资金。
- 提高效率:聊天机器人可以同时处理多个对话,确保快速响应并减少用户等待时间。
- 数据收集和分析:聊天机器人可以从用户交互中收集有用的信息,让企业了解客户的偏好、需求和痛点。利用这些数据,改进产品和服务。
现在我们已经了解了使用聊天机器人的好处,让我们继续逐步分解使用OpenAI构建定制聊天机器人所需的代码。
步骤
第1步:导入所需的库
我们需要导入必要的库。在提供的代码中,我们可以看到以下导入语句:
!pip install langchain
!pip install faiss-cpu
!pip install openai
!pip install llama_index
# 或者你可以使用
%pip install langchain
%pip install faiss-cpu
%pip install openai
%pip install llama_index在继续之前,请确保您已安装这些库。
第2步:设置API密钥
要与OpenAI API进行交互,您需要一个API密钥。在提供的代码中,有一个占位符指示您在哪里添加您的API密钥:
要找到您的 API 密钥,请访问 OpenAI 网站并创建一个新的 OpenAI 密钥。
import os
os.environ["OPENAI_API_KEY"] = '在这里添加您的 API 密钥'将‘在这里添加您的 API 密钥’替换为您从 OpenAI 获取的实际 API 密钥。
第三步:创建和索引知识库
在此步骤中,我们将创建和索引聊天机器人用于回答用户查询的知识库。提供的代码演示了两种方法:一种是从目录加载文档,另一种是加载现有索引。让我们专注于第一种方法。
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('/Users/tarakram/Documents/Chatbot/data').load_data()
print(documents)使用 SimpleDirectoryReader 类从特定目录加载文档。
将‘/Users/tarakram/Documents/Chatbot/data’替换为包含知识库文档的目录的路径。load_data() 函数加载文档并返回它们。
加载文档后,我们需要使用 GPTVectorStoreIndex 类创建索引:
index = GPTVectorStoreIndex.from_documents(documents)此步骤使用加载的文档创建索引。
第四步:持久化索引
为了避免每次运行代码都需要重新构建索引,我们可以将索引持久化到磁盘上。在提供的代码中,使用以下行保存索引:
# 保存索引
index.storage_context.persist('/Users/tarakram/Documents/Chatbot')请确保将‘/Users/tarakram/Documents/Chatbot’替换为您想要保存索引的目录路径。
通过持久化索引,我们可以在后续运行中加载它,而不会产生额外的令牌成本。
第五步:加载索引
如果您想加载先前保存的索引,可以使用以下代码:
from llama_index import StorageContext, load_index_from_storage
# 重建存储上下文
storage_context = StorageContext.from_defaults
(persist_dir='/Users/tarakram/Documents/Chatbot/index')
# 加载索引
index = load_index_from_storage(storage_context)请确保您将‘/Users/tarakram/Documents/Chatbot/index’更新为您保存索引的正确目录路径。
第六步:创建聊天机器人类
现在,让我们继续创建实际的聊天机器人类,它与用户进行交互并生成响应。以下是提供的代码:
# 聊天机器人
import openai
import json
class Chatbot:
def __init__(self, api_key, index):
self.index = index
openai.api_key = api_key
self.chat_history = []
def generate_response(self, user_input):
prompt = "\n".join([f"{message['role']}: {message['content']}"
for message in self.chat_history[-5:]])
prompt += f"\nUser: {user_input}"
query_engine = index.as_query_engine()
response = query_engine.query(user_input)
message = {"role": "assistant", "content": response.response}
self.chat_history.append({"role": "user", "content": user_input})
self.chat_history.append(message)
return message
def load_chat_history(self, filename):
try:
with open(filename, 'r') as f:
self.chat_history = json.load(f)
except FileNotFoundError:
pass
def save_chat_history(self, filename):
with open(filename, 'w') as f:
json.dump(self.chat_history, f)Chatbot 类有一个 __init__ 方法,用于使用提供的 API 密钥和索引初始化聊天机器人实例。
generate_response 方法接受用户输入,使用索引和 OpenAI API 生成响应,并更新聊天历史记录。
load_chat_history 和 save_chat_history 方法分别用于加载和保存聊天历史记录。
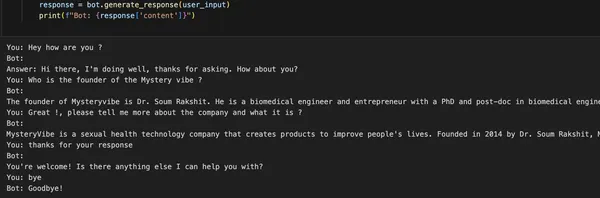
第七步:与聊天机器人交互
最后一步是与聊天机器人进行交互。以下是提供的代码片段,演示如何使用聊天机器人:
bot = Chatbot("在这里添加您的API密钥", index=index)
bot.load_chat_history("chat_history.json")
while True:
user_input = input("您: ")
if user_input.lower() in ["bye", "goodbye"]:
print("机器人: 再见!")
bot.save_chat_history("chat_history.json")
break
response = bot.generate_response(user_input)
print(f"机器人: {response['content']}")要使用聊天机器人,可以通过传递您的OpenAI API密钥和已加载的索引来创建Chatbot类的实例。
将“在这里添加您的API密钥”替换为您的实际API密钥。使用load_chat_history方法从文件中加载聊天记录(将“chat_history.json”替换为实际文件路径)。
然后,使用while循环不断获取用户输入并生成回复,直到用户输入“bye”或“goodbye”为止。
使用save_chat_history方法将聊天记录保存到文件中。
第8步:使用Streamlit构建Web应用程序
提供的代码还包括使用Streamlit构建的Web应用程序,允许用户通过用户界面与聊天机器人进行交互。以下是提供的代码:
import streamlit as st
import json
import os
from llama_index import StorageContext, load_index_from_storage
os.environ["OPENAI_API_KEY"] = '在这里添加您的API密钥'
# 重新构建存储上下文
storage_context = StorageContext.from_defaults
(persist_dir='/Users/tarakram/Documents/Chatbot/index')
# 加载索引
index = load_index_from_storage(storage_context)
# 创建聊天机器人
# 聊天机器人
import openai
import json
class Chatbot:
def __init__(self, api_key, index, user_id):
self.index = index
openai.api_key = api_key
self.user_id = user_id
self.chat_history = []
self.filename = f"{self.user_id}_chat_history.json"
def generate_response(self, user_input):
prompt = "\n".join([f"{message['role']}: {message['content']}"
for message in self.chat_history[-5:]])
prompt += f"\nUser: {user_input}"
query_engine = index.as_query_engine()
response = query_engine.query(user_input)
message = {"role": "assistant", "content": response.response}
self.chat_history.append({"role": "user", "content": user_input})
self.chat_history.append(message)
return message
def load_chat_history(self):
try:
with open(self.filename, 'r') as f:
self.chat_history = json.load(f)
except FileNotFoundError:
pass
def save_chat_history(self):
with open(self.filename, 'w') as f:
json.dump(self.chat_history, f)
# Streamlit应用
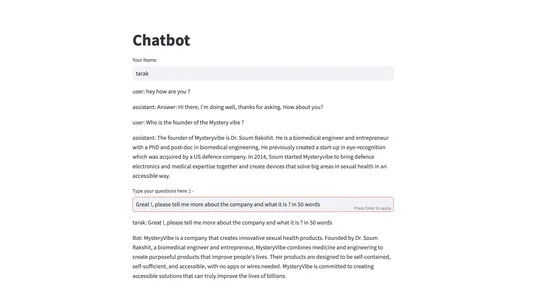
def main():
st.title("聊天机器人")
# 用户ID
user_id = st.text_input("您的姓名:")
# 检查是否提供了用户ID
if user_id:
# 为用户创建聊天机器人实例
bot = Chatbot("在这里添加您的API密钥", index, user_id)
# 加载聊天记录
bot.load_chat_history()
# 显示聊天记录
for message in bot.chat_history[-6:]:
st.write(f"{message['role']}: {message['content']}")
# 用户输入
user_input = st.text_input("在此处输入您的问题 :) - ")
# 生成回复
if user_input:
if user_input.lower() in ["bye", "goodbye"]:
bot_response = "再见!"
else:
bot_response = bot.generate_response(user_input)
bot_response_content = bot_response['content']
st.write(f"{user_id}: {user_input}")
st.write(f"机器人: {bot_response_content}")
bot.save_chat_history()
bot.chat_history.append
({"role": "user", "content": user_input})
bot.chat_history.append
({"role": "assistant", "content": bot_response_content})
if __name__ == "__main__":
main()要运行Web应用程序,请确保已安装Streamlit(pip install streamlit)。
请将“将“Add your API Key here”替换为您实际的OpenAI API密钥。
然后,您可以使用streamlit run app.py命令运行应用程序。
Web应用程序将在您的浏览器中打开,您可以通过提供的用户界面与聊天机器人进行交互。
提高聊天机器人性能的方法
考虑以下改进聊天机器人性能的方式:
- 微调:通过使用更多数据对聊天机器人模型进行微调,不断提高其理解和生成回复的能力。
- 用户反馈集成:集成用户反馈回路,根据真实用户互动改进聊天机器人性能。
- 混合技术:研究将基于规则的系统与AI模型相结合的混合技术,以更有效地处理复杂情况。
- 领域特定信息:包含领域特定的信息和数据,以提高聊天机器人在某些主题领域的专业知识和准确性。
结论
恭喜!您现在已经学会了如何使用OpenAI创建自定义聊天机器人。在本指南中,我们介绍了如何使用OpenAI创建定制的聊天机器人。我们介绍了设置所需库、获取API密钥、创建和索引知识库、创建聊天机器人类以及与聊天机器人交互的步骤。
您还可以通过使用Streamlit构建用户友好的界面来探索构建Web应用程序的选择。创建聊天机器人是一个迭代的过程,不断改进对提高其功能至关重要。通过利用OpenAI的功能和及时了解AI的最新突破,您可以设计出提供出色用户体验和有意义支持的聊天机器人。通过尝试不同的提示、训练数据和微调技术,为您的特定需求量身定制聊天机器人。可能性是无限的,而OpenAI提供了一个强大的平台来探索和释放聊天机器人技术的潜力。
重点提示
- 设置所需库、获取API密钥、生成和索引知识库以及实现聊天机器人类是使用OpenAI构建定制聊天机器人的步骤。
- 聊天机器人是通过提供帮助和回答自然语言问题来模拟人类互动的计算机程序。
- 数据收集对于训练高效的聊天机器人至关重要,它涉及从可靠来源获取相关和多样化的数据集。
- 使用OpenAI的GPT-3.5语言模型和像Llamas库这样的工具进行对话AI应用可以大大提高聊天机器人处理相关数据的能力。
- Streamlit为创建具有直观用户界面的Web应用程序提供了一个实用的框架,使用户可以通过该界面与聊天机器人进行交流。
您可以在Github上访问代码-链接
在Linkedin上与我联系-链接
常见问题
本文中显示的媒体不归Analytics Vidhya所有,而是根据作者的自行决定使用。





