使用遥感(卫星)图像和标题对CLIP进行微调
使用遥感图像和标题微调CLIP
使用遥感(卫星)图像和说明文本微调 CLIP

今年七月,Hugging Face组织了一次Flax/JAX社区周,邀请社区成员提交在自然语言处理(NLP)和计算机视觉(CV)领域训练Hugging Face transformers模型的项目。
参与者使用了Flax和JAX的Tensor Processing Units(TPUs)。JAX是一个线性代数库(类似于numpy),可以进行自动微分(Autograd)和编译为XLA,而Flax是一个基于JAX的神经网络库和生态系统。TPU计算时间由Google Cloud免费提供,他们也是本次活动的共同赞助商。
在接下来的两周里,团队们参加了Hugging Face和Google的讲座,使用JAX/Flax训练了一个或多个模型,并与社区分享了它们,并提供了一个Hugging Face Spaces演示,展示了他们模型的能力。大约有100个团队参加了此次活动,共产生了170个模型和36个演示。
我们的团队,像许多其他团队一样,分布在12个时区。我们的共同点是我们都属于TWIML Slack Channel,我们在那里聚集在一起,基于对人工智能(AI)和机器学习(ML)主题的共同兴趣。
我们使用RSICD数据集中的卫星图像和说明文本对OpenAI的CLIP网络进行了微调。CLIP网络通过以自监督方式使用互联网上的图像和说明文本进行训练,学习视觉概念。在推理过程中,该模型可以根据文本描述预测最相关的图像,或者根据图像预测最相关的文本描述。CLIP足够强大,可以在日常图像上以零样本方式使用。然而,我们认为卫星图像与日常图像有足够的差异,因此微调CLIP对于我们是有用的。正如下面描述的评估结果所示,我们的直觉是正确的。在本文中,我们将详细描述我们的训练和评估过程,以及我们在此项目上的未来计划。
我们项目的目标是提供一个有用的服务,并演示如何将CLIP用于实际应用场景。我们的模型可以通过文本查询搜索大量的卫星图像。这些查询可以对图像进行整体描述(例如,海滩、山脉、机场、棒球场等),或者搜索或提及这些图像中的特定地理或人造特征。CLIP也可以像medclip-demo团队展示的那样,针对其他领域进行微调,例如医学图像。
使用文本查询搜索大量图像的能力是一个非常强大的功能,既可以用于社会公益,也可以用于恶意目的。可能的应用包括国家防御和反恐活动,能够在气候变化产生不可控之前发现并解决其影响等。不幸的是,这种能力也可能被专制国家用于军事和警务监视等目的,因此也引发了一些伦理问题。
您可以在我们的项目页面上阅读有关该项目的信息,下载我们训练好的模型以在您自己的数据上进行推理,或在我们的演示中看到它的实际效果。
训练
数据集
我们主要使用RSICD数据集对CLIP模型进行微调。该数据集包含约10,000张从Google Earth、百度地图、MapABC和天地图收集的图像。它免费提供给研究社区,以通过Exploring Models and Data for Remote Sensing Image Caption Generation (Lu et al, 2017)推进遥感图像字幕的研究。这些图像是各种分辨率的(224, 224)RGB图像,每个图像有多达5个与之关联的说明文本。
 RSICD数据集中的一些图像示例
RSICD数据集中的一些图像示例
此外,我们还使用了UCM数据集和悉尼数据集进行训练。UCM数据集基于UC Merced Land Use数据集,包含2100张属于21个类别的图像(每个类别100张图像),每个图像有5个说明文本。悉尼数据集包含来自Google Earth的悉尼,澳大利亚的图像,共有613张图像属于7个类别。这些图像是(500, 500)RGB图像,并为每个图像提供5个说明文本。我们使用这些额外的数据集,因为我们不确定RSICD数据集是否足够大以微调CLIP。
模型
我们的模型只是原始CLIP模型的微调版本,如下所示。模型的输入是一批标题和一批图像,分别通过CLIP文本编码器和图像编码器。训练过程使用对比学习来学习图像和标题的联合嵌入表示。在这个嵌入空间中,图像及其相应的标题被推到靠近一起,相似的图像和相似的标题也是如此。相反,不同图像的图像和标题,或者不相似的图像和标题,很可能被推得更远。
 CLIP训练和推理(图片来源:CLIP:连接文本和图像(https://openai.comclip/))
CLIP训练和推理(图片来源:CLIP:连接文本和图像(https://openai.comclip/))
数据增强
为了规范化我们的数据集并防止由于数据集大小引起的过拟合,我们使用了图像和文本增强。
图像增强使用Pytorch的Torchvision包中的内置转换进行。使用的转换包括随机裁剪、随机调整大小和裁剪、颜色抖动以及随机水平和垂直翻转。
我们使用反向翻译对文本进行增强,为每个图像生成少于5个唯一标题的图像。使用Hugging Face的Marian MT系列模型将现有的标题翻译成法语、西班牙语、意大利语和葡萄牙语,然后再翻译回英语,为这些图像的标题填充。
如下所示的损失图表显示,图像增强显著减少了过拟合,而文本和图像增强进一步减少了过拟合。

 评估和训练损失图表对比(顶部)无增强 vs 图像增强,以及(底部)图像增强 vs 文本+图像增强
评估和训练损失图表对比(顶部)无增强 vs 图像增强,以及(底部)图像增强 vs 文本+图像增强
评估
指标
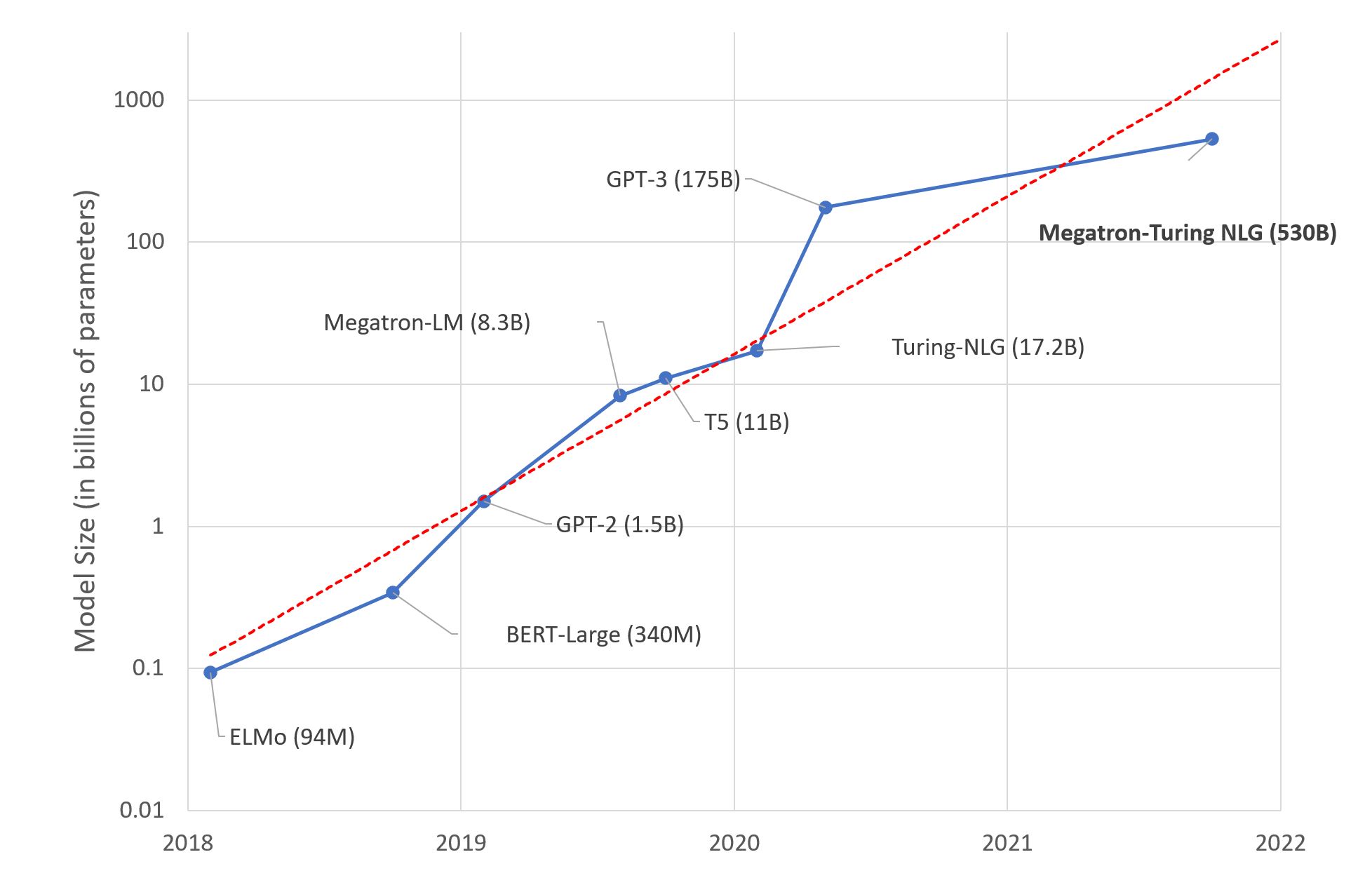
我们使用RSICD测试集的一个子集进行评估。在这个子集中,我们找到了30个图像类别。评估通过将每个图像与一组形如"一个{category}的航拍照片"的30个标题句子进行比较来进行。模型产生了一个排名列表,从最相关到最不相关的30个标题。将得分最高的前k个(k=1、3、5和10)得分对应的类别与通过图像文件名提供的类别进行比较。得分在用于评估的整个图像集合上进行平均,并针对不同的k值报告,如下所示。
基准模型代表预训练的openai/clip-vit-base-path32 CLIP模型。该模型使用RSICD数据集的标题和图像进行微调,结果显示显著的性能提升,如下所示。
我们的最佳模型是使用图像和文本增强训练的,批次大小为1024(每个8个TPU核心为128),使用学习率为5e-6的Adam优化器进行训练。我们的第二个基准模型使用相同的超参数,只是使用学习率为1e-4的Adafactor优化器进行训练。您可以从下表中链接的模型存储库中下载任一模型。
1 – 我们的最佳模型,2 – 我们的第二个最佳模型
演示
您可以在这里访问CLIP-RSICD演示。它使用我们的微调CLIP模型提供以下功能:
- 文本到图像搜索
- 图像到图像搜索
- 在图像中查找文本特征
前两个功能使用RSICD测试集作为图像语料库。它们使用我们最佳的微调CLIP模型进行编码,并存储在一个NMSLib索引中,该索引允许基于近似最近邻的检索。对于文本到图像和图像到图像搜索,查询文本或图像会使用我们的模型进行编码,并与语料库中的图像向量进行匹配。对于第三个功能,我们将传入的图像划分为多个补丁并对其进行编码,将查询的文本特征进行编码,将文本向量与每个图像补丁向量进行匹配,并返回在每个补丁中找到该特征的概率。
未来工作
我们很荣幸能有机会进一步改进我们的模型。我们对未来工作的一些想法如下:
- 使用CLIP编码器和GPT-3解码器构建一个序列到序列模型,并对其进行训练,用于图像描述。
- 从其他数据集中获取更多的图像描述对,对模型进行微调,并研究是否可以提高其性能。
- 研究微调对模型在非RSICD图像描述对上的性能影响。
- 研究经过微调的模型在超出其微调类别范围的分类能力。
- 使用其他标准(如图像分类)评估模型。