教授语言模型进行算法推理
使用语言模型进行算法推理
文章作者:Hattie Zhou(MILA研究生)、Hanie Sedghi(Google研究科学家)
大型语言模型(LLMs)如GPT-3和PaLM近年来取得了令人印象深刻的进展,这主要得益于模型和训练数据规模的扩大。然而,长期以来存在一个争论,即LLMs是否能进行符号推理(即根据逻辑规则进行符号操作)。例如,当数字较小时,LLMs能够执行简单的算术运算,但在处理大数时却困难重重。这表明LLMs尚未学到执行这些算术运算所需的基本规则。
尽管神经网络具有强大的模式匹配能力,但它们容易过度拟合数据中的虚假统计模式。当训练数据规模庞大且多样化,并且评估结果在分布范围内时,这并不影响良好的性能。然而,对于需要基于规则推理(如加法)的任务,LLMs在超出分布范围的泛化能力上表现不佳,因为训练数据中的虚假相关性往往比真正的基于规则的解决方案更容易被利用。因此,尽管在各种自然语言处理任务上取得了显著进展,但在加法等简单算术任务上的性能仍然是一个挑战。即使在MATH数据集上对GPT-4进行了适度改进,错误仍主要由算术和计算错误引起。因此,一个重要的问题是LLMs是否具备算法推理的能力,即通过应用一组定义了算法的抽象规则来解决任务。
在《通过上下文学习教授算法推理》一文中,我们描述了一种利用上下文学习实现LLMs算法推理能力的方法。上下文学习指的是模型在模型上下文中看到一些示例后能够执行任务的能力。任务通过提示信息指定给模型,而无需权重更新。我们还提出了一种新颖的算法提示技术,使通用语言模型能够在比提示中看到的更困难的算术问题上实现强大的泛化能力。最后,我们展示了在适当的提示策略下,模型能够可靠地在超出分布范围的示例上执行算法。
 |
| 通过提供算法提示,我们可以通过上下文学习来教授模型算术规则。在这个例子中,当给模型提供一个简单的加法问题(例如267+197)的提示时,LLM(词预测器)输出了正确答案,但当问及一个具有更长数字的类似加法问题时失败了。然而,当较困难的问题附带一个加法算法提示(白色+的蓝色方框显示在词预测器下方)时,模型能够正确回答。此外,该模型能够通过组合一系列加法计算来模拟乘法算法(X)。 |
将算法作为一种技能进行教学
为了教授模型算法作为一种技能,我们开发了算法提示,它建立在其他理性增强方法(如草稿本和思路链)的基础上。算法提示从LLMs中提取算法推理能力,并与其他提示方法相比有两个显著区别:(1)它通过输出算法解决任务所需的步骤来解决任务,(2)它以足够详细的方式解释每个算法步骤,以确保LLM没有误解。
为了对算法提示有直观的理解,让我们考虑两个数字相加的任务。在草稿本风格的提示中,我们从右到左处理每个数字,并在每一步中跟踪进位值(即,如果当前数字大于9,则在下一个数字上加1)。然而,只看到少数进位值的例子后,进位规则就变得模棱两可。我们发现,包含用于描述进位规则的显式方程式有助于模型关注相关细节并更准确地理解提示。我们利用这一观点开发了两个数字相加的算法提示,其中我们为每个计算步骤提供了明确的方程式,并以非模棱两可的格式描述各种索引操作。
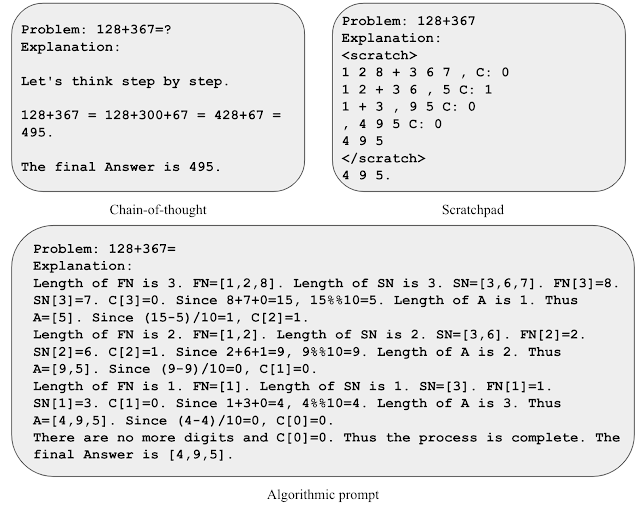 |
| 各种加法提示策略的示意图。 |
通过仅使用三个加法问题的提示示例,答案长度最多为五位数,我们评估了对长达19位数的加法问题的性能。准确度是在总共2000个示例上均匀采样得到的,这些示例的长度覆盖了答案的范围。如下图所示,算法提示的使用使得在问题明显长于提示的情况下仍能保持较高的准确性,这表明模型确实通过执行与输入无关的算法来解决任务。
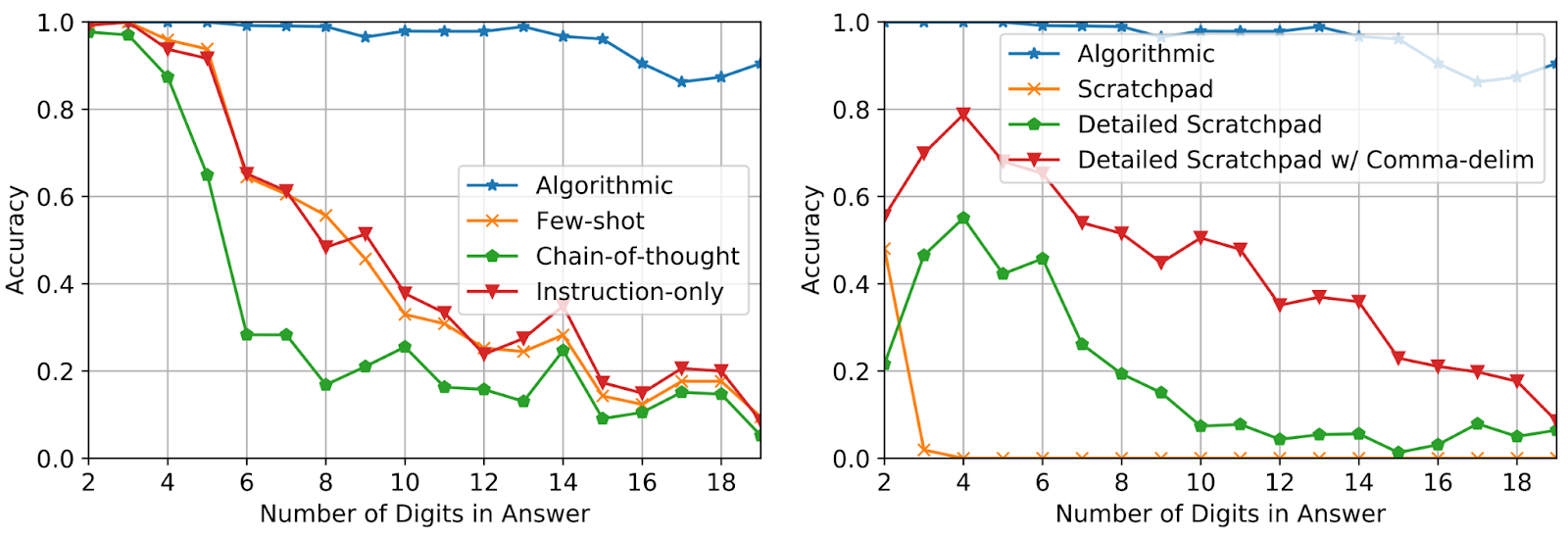 |
| 不同提示方法下,加法问题准确率随问题长度的增加而变化。 |
利用算法技能作为工具使用
为了评估模型是否能够在更广泛的推理过程中利用算法推理,我们使用小学数学问题(GSM8k)进行性能评估。我们具体尝试用算法解决GSM8k中的加法计算。
受到上下文长度限制和不同算法之间可能的干扰的影响,我们探索了一种策略,即不同提示方式的模型相互交互以解决复杂任务。在GSM8k的背景下,我们有一个专门使用思维链提示进行非正式数学推理的模型,以及一个专门使用算法提示进行加法运算的模型。非正式数学推理模型被提示输出特定的标记,以调用加法提示模型执行算术步骤。我们提取标记之间的查询,发送给加法模型并将答案返回给第一个模型,之后第一个模型继续输出。我们使用GSM8k中的一个难题(GSM8k-Hard)来评估我们的方法,随机选择50个仅包含加法的问题,并增加问题中的数值。
 |
| GSM8k-Hard数据集中的一个示例。思维链提示使用方括号表示何时执行算法调用。 |
我们发现使用专门的提示和专门的模型来处理GSM8k-Hard是一种有效的方法。下面,我们观察到,使用算法调用进行加法的模型的性能是有思维链基准的2.3倍。最后,这种策略通过在环境中学习,为解决复杂任务提供了一种通过不同技能的LLM之间的相互作用来实现的例子。
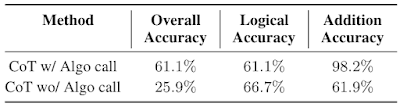 |
| 链式思维 (CoT) 在GSM8k-Hard上的性能,有无算法调用。 |
结论
我们提出了一种利用在环境中学习和一种新颖的算法提示技术来发挥LLM中的算法推理能力的方法。我们的结果表明,通过提供更详细的解释,可能将更长的上下文转化为更好的推理性能。因此,这些发现指出了使用或模拟长上下文并生成更多信息的原因作为有希望的研究方向的能力。
致谢
我们感谢我们的合著者Behnam Neyshabur,Azade Nova,Hugo Larochelle和Aaron Courville对论文的宝贵贡献和博客的宝贵反馈。我们感谢Tom Small在本文中创建动画。此工作是在Hattie Zhou在Google Research实习期间完成的。






